










MySQL索引优化实战
一、前言
当我们使用数据库进行查询时,通常为了提高查询效率,我们倾向于为常用的查询条件创建索引,从而达到快速查找的目的。对于一些可以预见数据量很小的业务表来说,没有索引的影响并不大,而对于一些持续增长大量数据的表来说,选择创建合适的索引是必要的,否则将会严重影响数据的查询效率。
二、项目情况
这里我们便使用一个常见的分布式开源项目xxl-job,配合自己的业务来进行分析。在xxl-job中每天任务的调度记录都需要记录到数据库中,这也算是xxl-job中能算是数据量达到最大的一张表了。它的表结构如下:
CREATE TABLE `XXL_JOB_QRTZ_TRIGGER_LOG` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
查询每七天的数据量为26万多,平均每天四万左右的数据量。由于表的数据量比较大,且越靠以前的数据参考意义越不大,因此我们会定时清理两个月以前的数据,这样整张表的数据量在265万左右。
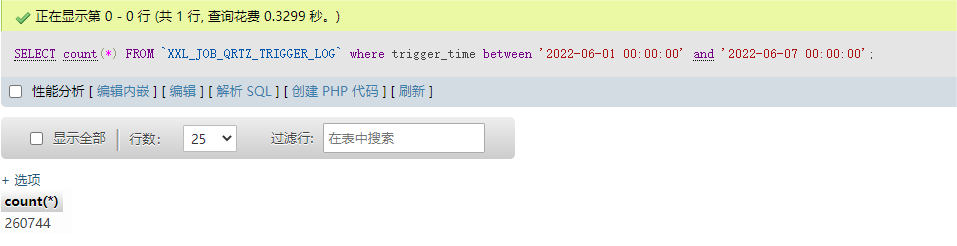
由于我们有时需要常看某一段时间,某个任务的所有调度信息记录,比如:查看2022-06-01到2022-06-10的一个任务数据,经常就会出现页面超时的情况,所以才需要对这张表进行优化。如下所示:
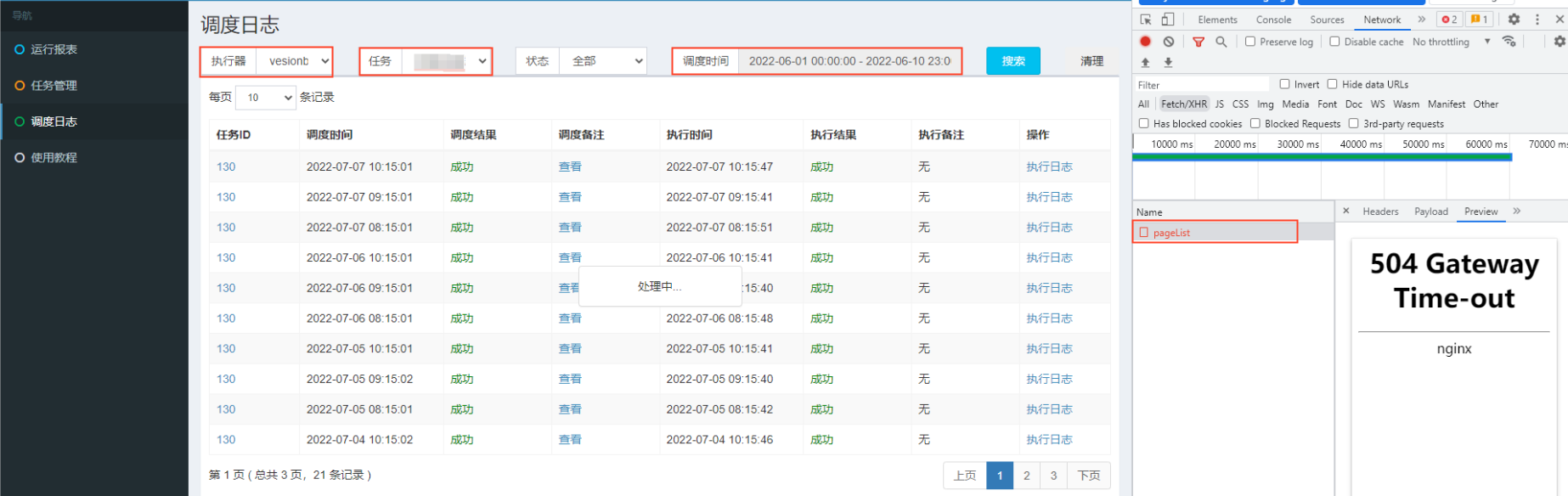
目前这张表已经有了trigger_time的索引,用于做任务触发时间的索引,而页面上的查询条件还有执行器、任务、状态这些条件,分别对应 job_group、job_id、handle_code这几个字段。
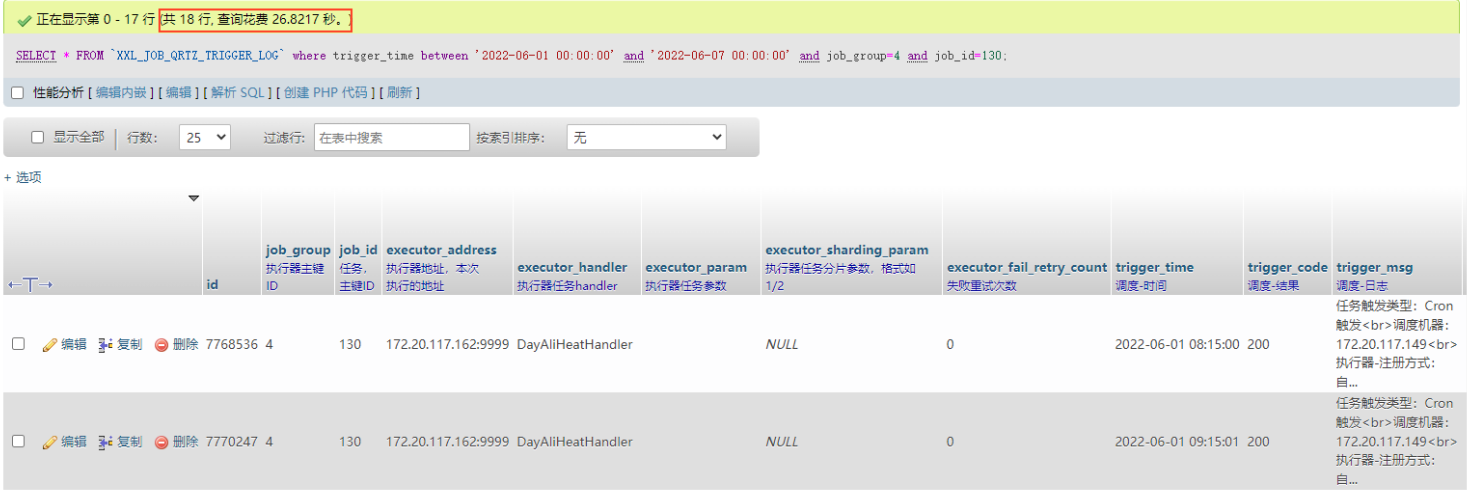
为了优化表的查询速度,先要对该表做查询分析,从测试的结果看,查询一周的数据需要二十秒以上的时间:
三、explain分析
进行explain分析(PG和mysql 8.0以上支持explain analyze,能够执行sql体现出实际成本,这里我们用的是5.7只能用explain):


当查询条件是6.1到6.7的时候,走的是trigger_time的索引,但是由于是范围查询,索引区分度过低,通过索引能够查询出260744(explain中估算为560046) 条数据出来,再对这260744条数据进行逐行扫描筛选数据,查询出18行数据。
而当查询条件是6.1到6.10的时候,由于数据库的查询优化器认为使用trigger_time索引的数据区分度太低,认为进行全表扫描比走索引进行查询效率更高,因而直接走了全表扫描,实际测试全表扫描需要几分钟。
在进行explain分析时,我们着重注意type、key、rows、filtered字段,基本都能够看到rows过高,filtered过低,存在很大的优化空间。
这里我们的主要问题就是索引区分度过低,即通过索引查出来的数据太多,需要通过逐行扫描大量数据来筛选小批量数据。
四、优化方案
因此,考虑到XXL_JOB_QRTZ_TRIGGER_LOG几乎所有的查询都来自于上面的调度日志查询页面,trigger_time、job_group、job_id和handle_code都是经常使用的查询条件,因此我们这里可以考虑使用联合索引来优化查询。
简单列一下联合索引的创建原则:
- 由于最左前缀原则,最经常使用、最必不可少的字段应该放在最前面
- 区分度更高的应该放在前面
- 对于有范围查询(非等值查询)的字段,应该放在最末尾,因为他右边的字段索引都不会生效
- 联合索引不应过长,尽量不超过3个
从这些来看的话,trigger_time是最经常用且必选的条件,但他是范围查询,因此应该将它放到最后,选了job_id就必有job_group作为查询条件,即job_group更加常用,因此job_group应该放在job_id前面,handle_code是最不常用的,且他的值较少,区分度也低,为了避免太多字段的联合索引,因此handle_code不需要加入到联合索引当中来。
综上,创建索引SQL如下:
alter table XXL_JOB_QRTZ_TRIGGER_LOG add index I_union_index(job_group,job_id,trigger_time) using btree;
五、Online DDL与注意事项
5.1 Online DDL介绍
需要注意的是,在使用MySQL作为数据库,其在5.6之后新增了一个Online DDL 的功能,可以使得数据库的增删改查操作能够与DDL语句并行执行,使得DDL操作对数据库影响变得更小,这个功能对于生产环境就显得尤为重要了。因为一般情况下,我们应该尽量保证服务的可用性,在MySQL 5.6以前,DDL是需要直接锁表进行操作的,因此必须需要停服再对数据库进行操作。
| 操作 | In Place | Rebuilds Table | 保证并发DML | 仅修改元数据 |
|---|---|---|---|---|
| 添加非主键索引 | √ | x | √ | x |
| 删除索引 | √ | x | √ | √ |
| 重命名索引 | √ | x | √ | √ |
| 添加全文索引 | √ | x | x | x |
| 添加空间索引 | √ | x | x | x |
| 改变索引类型 | √ | x | √ | √ |
5.2 遇到的问题
如果认为有了online ddl 就万事大吉了,那肯定是不对的,在正式更新生产环境之前,我们在测试环境和预生产环境都执行了这个建索引的SQL,并没有想象的那么顺利,在执行完SQL等待它完成的过程中,我们开启了另一个session对这张表进行访问,发现这个普通的查询SQL并没有及时返回,可能是被阻塞住了,于是使用show full processlist进行查看
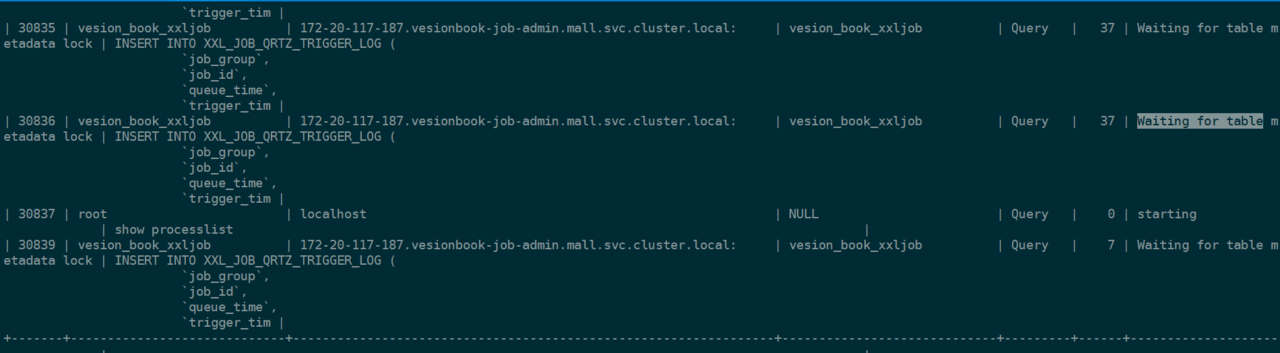
这里可以看到,所有关于XXL_JOB_QRTZ_TRIGGER_LOG这个表的语句都在等待锁的释放:Waiting for table metadata lock。
再执行 select * from information_schema.innodb_trx
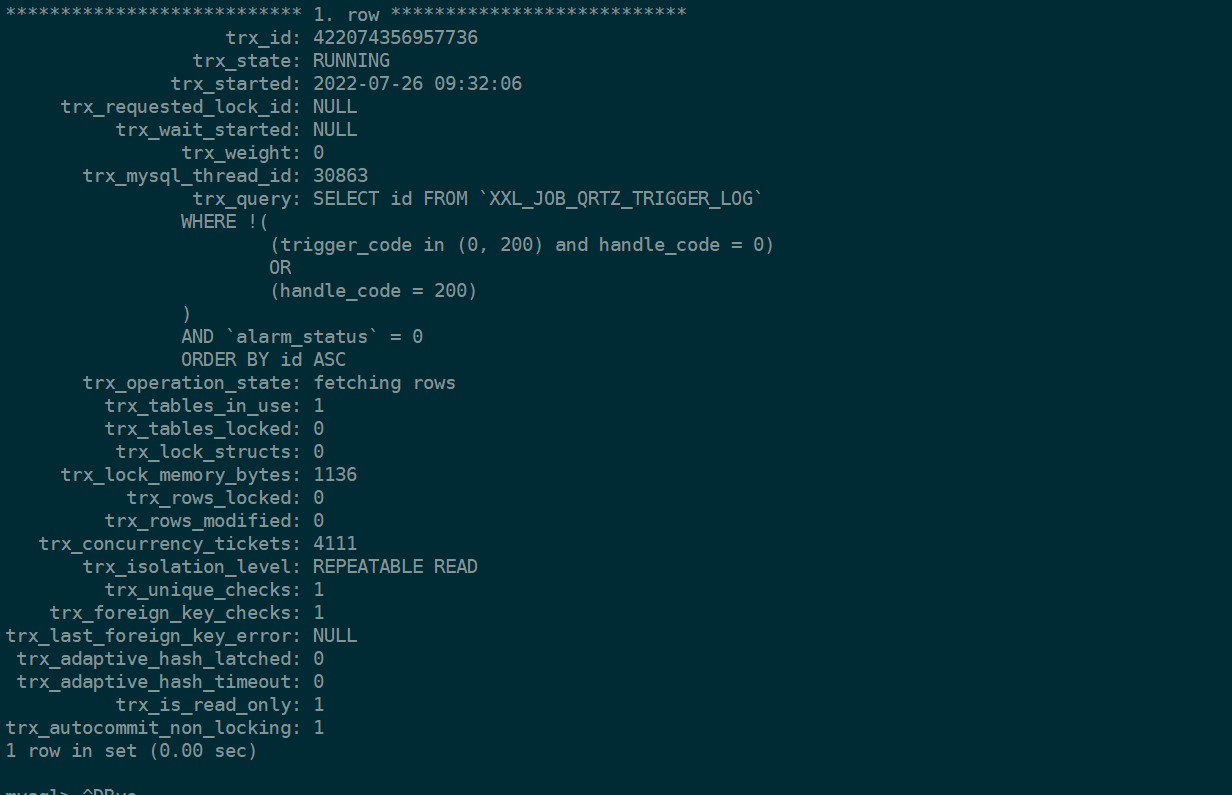
看到了有这个sql在运行,然而这个sql是没有带trigger_time的索引的,因此会走一个全表扫描取执行,之前我们也测试过,一个全表扫描的sql大概需要五六分钟才能够执行完成。
(后面了解到,这个sql是xxl-job-admin用来做任务失败重试和告警使用的,每十秒钟会执行一次,感觉这也是个急需改进的sql,对于目前我们项目这样的任务量来说,每次扫描都需要进行一次全表扫描,需要五六分钟失败的任务才能得到响应,滞后性较大,且xxl-job-admin是一直在运行的,不会存在时隔太久且需要重试的失败任务,且很早以前的失败任务再重新触发,也没有什么意义了,后续可以改成加trigger_time在最近三天或最近七天内就完全足够了)。
5.3 Online DDL的注意事项
在online ddl操作完成之前,它必须等待在表上持有元数据锁的事务提交或回滚。online ddl 操作会在prepare阶段获取表的独占元数据锁一段时间,并且在更新表定义时在操作的最后阶段(commit 阶段)也需要获取独占元数据锁。因此,在这个表上已经持有元数据锁的事务可能会导致online ddl操作阻塞。如果这个事务的运行时间很长,还可能会导致online ddl 操作超时。尤其要注意的是,在线 DDL 操作请求的未决独占元数据锁会阻塞表上的后续事务,这会使得online ddl在等那个长时间运行的事务,而后续所有的请求都在等online ddl,目前我们就是发生了这种情况。
因此我们最好在运行online ddl之前先看一下目前这个表上有没有正在长时间运行的事务,如果有的话,先kill掉这个事务再运行。
5.4 生产环境操作
由于在测试和预生产已经发现了这个问题,因此在生产环境操作时就需要有相应的措施,我们在生产环境是这样操作的:
- 提前准备三个sql执行页面:ddl创建索引、show full processlist和select * from information_schema.innodb_trx
- 执行ddl创建索引sql,等待进入prepare阶段
- 执行show full processlist,直到出现waitting for metadata lock
- 执行select * from information_schema.innodb_trx,再kill掉该sql线程
- 执行show full processlist,waitting for metadata lock消失,表示prepare阶段已经获取到独占锁
- 再次执行3步骤,等待进入commit阶段,执行4步骤kill掉该sql线程
- 等待sql完成
这里主要就是保证online ddl的prepare和commit阶段能够顺利获取到独占锁,尽量减少业务sql被阻塞的时间。
观察xxl-job-admin应用日志,除了两个被kill掉的sql的日志,没有其他错误日志的出现,说明业务基本没有被影响到。
六、最终效果
创建索引语句执行完以后,再来测试之前的语句,看加上联合索引之后,有了多大的改观:

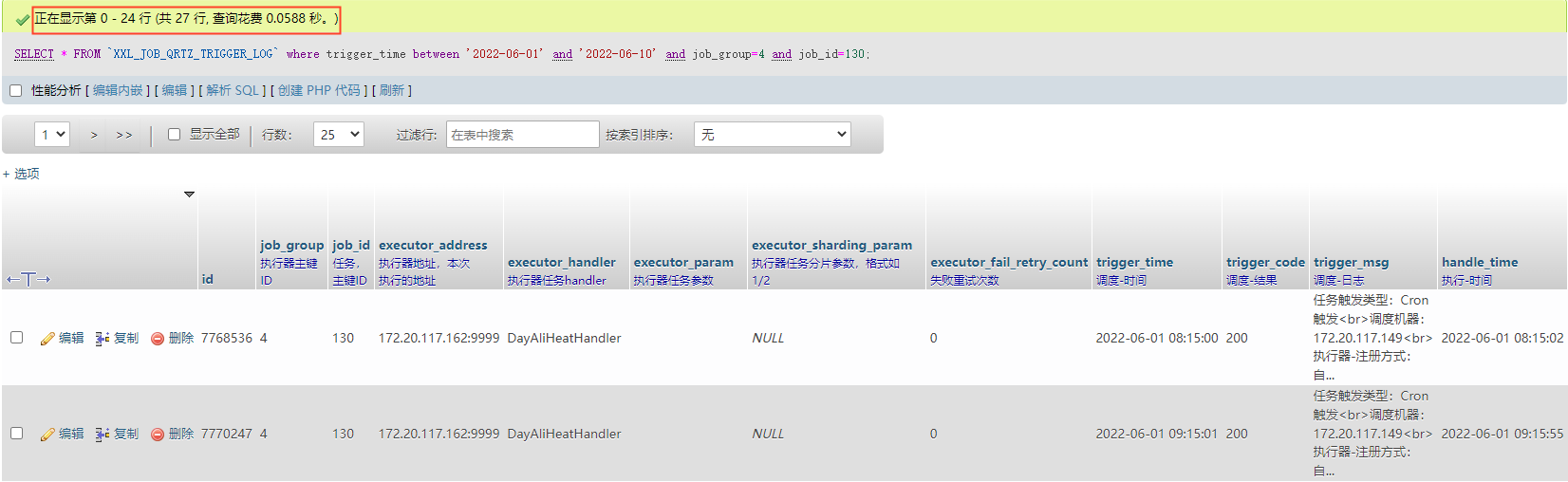
这里查询性能几乎从20多秒控制到了100ms以内了
参考MySQL官网:
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-limitations.html
https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-performance.html














 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









