







这篇文章主要介绍2021的cvpr论文 美团学者对经典分割架构BiSeNet的Rethinking
Rethinking BiSeNet For Real-time Semantic Segmentation
我将用Cityscapes数据集 结合RethinkingBiSeNet的开源代码 分析论文项目数据预处理是如何做的 并且在接下来的几篇文章 我将结合开源代码深入浅出分析整个项目 喜欢的朋友可以持续关注
1.将下载的cityscopes数据集中的gtFine和leftimg8bit这两个文件夹解压到项目data文件夹下
项目数据集整体结构如下:

作者论文中主要应用了训练集train和验证集val,gtFine文件夹存储的是标签数据,leftlmg8bit存储的原始图像。
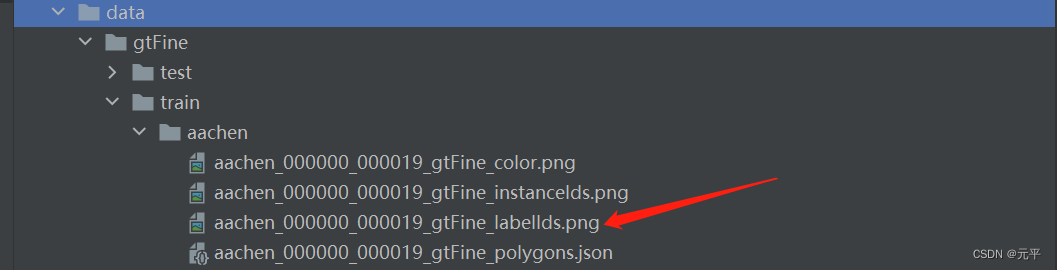
标签文件中,每张图片包含有四张不同的标签,语义分割主要使用labellds结尾的标签文件即可:
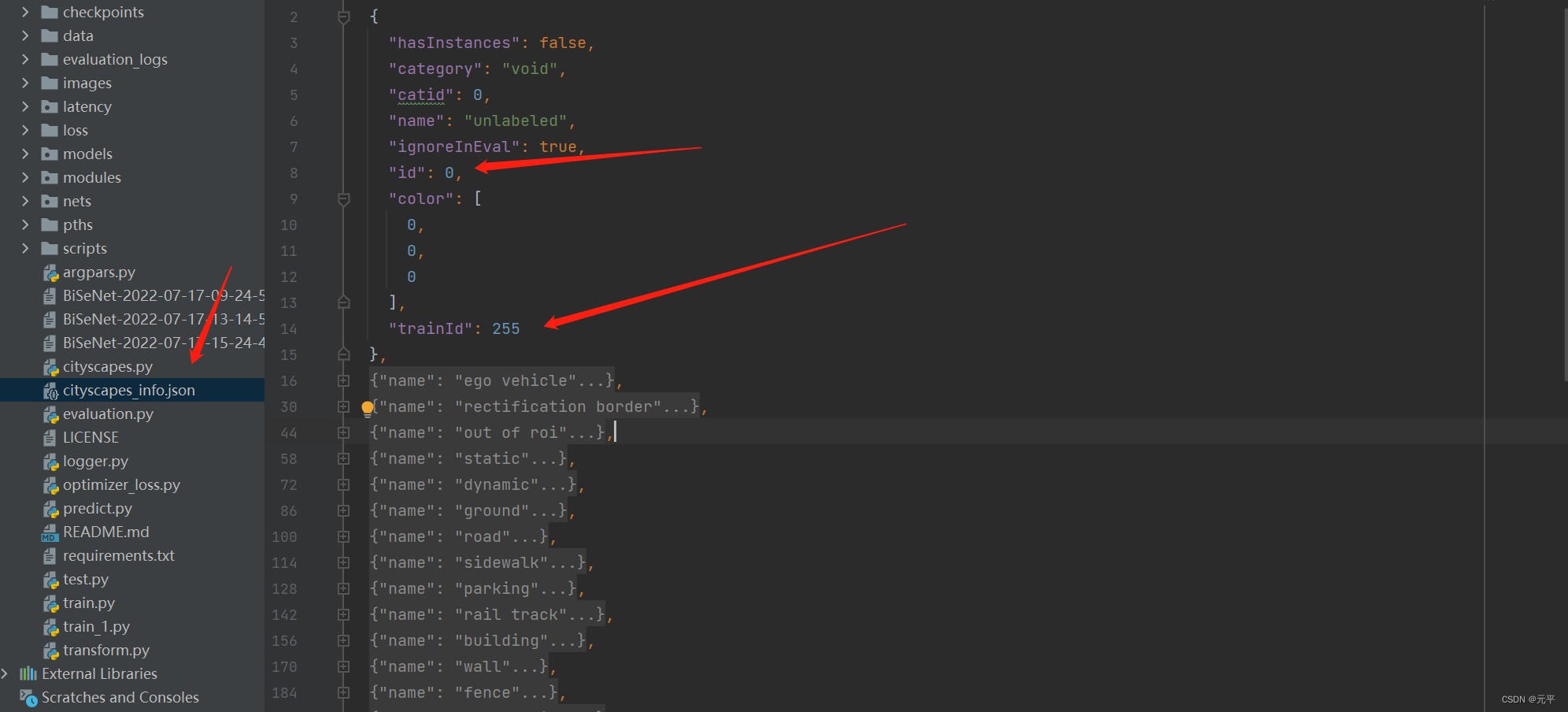
标签文件原本包含34种类别,项目中使用了19种类别,所以需要对标签文件进行一定的处理,项目cityscapes_info.json文件中存储了相应的映射关系,将34类中感兴趣的类别映射到19类中,其它不感兴趣的类别就直接设成255,所以这也是为什么转换后的标签中有白色像素的原因,因为那些白色像素的类别不是我们感兴趣的,变成255白色了。 当然,这个预变换处理也不一定非要先做,因为有的模型,比如deeplabv3+,训练时,本身就会做这个转换。json文件中已经存储了我们需要的19类的映射关系,其他不需要的转换为255,所以json文件我们主要需要id和trainid的对应关系即可。
读取json文件生成lb_map(生成id与trainid对应关系)代码如下:
with open(r'C:\Users\18312\Desktop\STDC-Seg-master\cityscapes_info.json', 'r') as fr:
labels_info = json.load(fr)
lb_map = {el['id']: el['trainId'] for el in labels_info}
生成结果如下;

对标签图片进行转换的函数如下:
#通过id和train_id对标签数据进行处理 lable[label==id] = trainid
#数据集原本有34类 通过构建映射到19类 不需要的类pix映射到255
def convert_labels(self, label):
for k, v in self.lb_map.items():
label[label == k] = v
return label
原始图片-原始标签图片-转换后的标签图片 如下图所示:



上面我已经阐述了数据集处理的关键部分,下面对数据集处理的代码整体进行分析,代码如下:
#!/usr/bin/python
# -*- encoding: utf-8 -*-
#图像数据预处理模块
import torch
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import os.path as osp
import os
from PIL import Image
import numpy as np
import json
from transform import *
from tqdm import tqdm
class CityScapes(Dataset):
def __init__(self, rootpth, cropsize=(640, 480), mode='train',
randomscale=(0.125, 0.25, 0.375, 0.5, 0.675, 0.75, 0.875, 1.0, 1.25, 1.5), *args, **kwargs):
#super(CityScapes, self).__init__(*args, **kwargs)
super(CityScapes, self).__init__()
assert mode in ('train', 'val', 'test', 'trainval') #assert断言 mode在列出的序列中则继续运行 否则报错
self.mode = mode
self.ignore_lb = 255
#读取cityscope。jaso生成映射关系
with open('./cityscapes_info.json', 'r') as fr:
labels_info = json.load(fr)
self.lb_map = {el['id']: el['trainId'] for el in labels_info}
# print(self.lb_map)
## parse img directory
self.imgs = {}
imgnames = []
impth = osp.join(rootpth, 'leftImg8bit', mode)
folders = os.listdir(impth)
for fd in folders:
fdpth = osp.join(impth, fd)
im_names = os.listdir(fdpth)
names = [el.replace('_leftImg8bit.png', '') for el in im_names]
impths = [osp.join(fdpth, el) for el in im_names]
imgnames.extend(names)
self.imgs.update(dict(zip(names, impths))) #(img_name,img_path)
## parse gt directory
self.labels = {}
gtnames = []
gtpth = osp.join(rootpth, 'gtFine', mode)
folders = os.listdir(gtpth)
for fd in folders:
fdpth = osp.join(gtpth, fd)
lbnames = os.listdir(fdpth)
lbnames = [el for el in lbnames if 'labelIds' in el]
names = [el.replace('_gtFine_labelIds.png', '') for el in lbnames]
lbpths = [osp.join(fdpth, el) for el in lbnames]
gtnames.extend(names)
self.labels.update(dict(zip(names, lbpths))) #(label_name,label_path)
self.imnames = imgnames
self.len = len(self.imnames)
print('self.len', self.mode, self.len)
assert set(imgnames) == set(gtnames)
assert set(self.imnames) == set(self.imgs.keys())
assert set(self.imnames) == set(self.labels.keys())
## pre-processing
self.to_tensor = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
self.trans_train = Compose([
ColorJitter(
brightness = 0.5,
contrast = 0.5,
saturation = 0.5),
HorizontalFlip(),
# RandomScale((0.25, 0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0)),
RandomScale(randomscale),
# RandomScale((0.125, 1)),
# RandomScale((0.125, 0.25, 0.375, 0.5, 0.675, 0.75, 0.875, 1.0)),
# RandomScale((0.125, 0.25, 0.375, 0.5, 0.675, 0.75, 0.875, 1.0, 1.125, 1.25, 1.375, 1.5)),
RandomCrop(cropsize)
])
#如果在类中定义了__getitem__()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。当实例对象做P[key]运算时,就会调用类中的__getitem__()方法。
def __getitem__(self, idx):
fn = self.imnames[idx]
impth = self.imgs[fn]
lbpth = self.labels[fn]
#读出来的图像是RGBA四通道的,A通道为透明通道,该通道值对深度学习模型训练来说暂时用不到,因此使用convert(‘RGB’)进行通道转换
img = Image.open(impth).convert('RGB')
label = Image.open(lbpth)
#如果是训练则对图片进行预处理
if self.mode == 'train' or self.mode == 'trainval':
im_lb = dict(im = img, lb = label)
im_lb = self.trans_train(im_lb)
img, label = im_lb['im'], im_lb['lb']
img = self.to_tensor(img)
label = np.array(label).astype(np.int64)[np.newaxis, :]
label = self.convert_labels(label)
return img, label
def __len__(self):
return self.len
#通过id和train_id对标签数据进行处理 lable[label==id] = trainid
#数据集原本有34类 通过构建映射到19类 不需要的类pix映射到255
def convert_labels(self, label):
for k, v in self.lb_map.items():
label[label == k] = v
return label
if __name__ == "__main__":
ds = CityScapes('./data/', n_classes=19, mode='val')
print('数据处理')
uni = []
for im, lb in tqdm(ds):
lb_uni = np.unique(lb).tolist()
uni.extend(lb_uni)
print(uni)
print(set(uni))
构建了一个cityscopes类,初始化的一些处理主要包括读取数据路径,生成 图片名称与图片路径的对应关系 标签名称与标签路径的对应关系 训练图片 以及训练图片的预处理方法。定义__getitem__(self, idx)魔法方法方便取值,并在其中定义了根据不同mode对图片的不同处理方式,即在训练或者训练验证时需要对图片进行预处理,其他mode时则只需要直接输出图片,不进行任何预处理操作。下面主函数中的代码,是作者对数据集进行测试所用,其他模块引用cityscopes类时,主函数中的代码不会被引入,没有影响。文章主要是结合Rethinking BiSeNet For Real-time Semantic Segmentation论文的开源代码进行讲解,所以并没有着重讲解数据集的一些细节,而是着重于讲解作者是如何处理数据集的,关于Cityscapes数据集的细节可以查阅数据集官网。















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









