







python 中提供了 KMeans库,可以方便我们对数据进行相应的聚类分析。
下面举个对于气温数据进行聚类分析的例子,数据来自ERA-5,可以自行从官网下载。
数据内容如下所示:
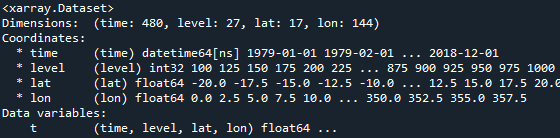
1、聚类分析
首先是导入库:
from sklearn.cluster import KMeans
然后对数据进行一下处理:
1、转换一下数据维度顺序,将高度level放到第一维
2、对nan值数据进行掩膜,
3、经纬度、时间、高度的大小,构造聚类矩阵
import xarray as xr
import numpy as np
path='D://t_data.nc'
ds=xr.open_dataset(path).sel(lat=slice(-20,20))
da=ds.transpose('level','time','lat','lon') #转换一下数据维度顺序便于后续处理
time=da.time.data #读取时间
lat=da.lat.data #读取纬度
lon=da.lon.data #读取经度
omega=da.t.data #读取气温
w= omega.reshape(27,17*144*480) #构建矩阵,27表示level层数,其他几项代表经纬度、时间的size
mask = np.isfinite(w[0,:]) #构建掩膜mask,判断是否有nan值
# # # # 依次循环将每一层得数据填入到零矩阵
# # 空矩阵k,便于后续聚类
k = np.zeros(((w[0,:][mask].shape[-1]),27))
# # 对于每一个高度层进行循环,填入每一层的非nan值数据
for i in range(27):
k[:,i] = w[i,mask]
上面把矩阵构建好了,是个二维矩阵k,第2维表示高度层(level),第1维表示该层上所有的非nan值的数据,下面就可进行聚类了。K-means则是事先给定聚类数,这里的聚类数可以通过一些方法(SSE、轮廓系数)进行评估,以便选取适合的聚类数。
km=KMeans(n_clusters=6) # 6表示聚类的个数,聚类容器
km.fit(k) #进行聚类
label=km.labels_ #获取聚类的标签
等代码运行结束就可以发现聚类成功了,数据被分为0、1、2、3、4、5六类数据,这里可以将聚类后的数据单独保存,以便后续数据处理,直接导入即可,不需要再聚类一次浪费时间。(ps:这里提醒一下,对于同一套数据进行多次聚类,会导致label的标签序号每次可能都不同,但是个数是不变的,所以建议聚类一次后没问题就直接保存!!
2、保存数据
保存数据,可以直接使用下面两种方法都行,保存为.npy或者.nc,看个人喜好。
### 直接保存为.npy格式
np.save("/label.npy",label)
### 保存为 .nc格式
# label = time*lat*lon
label_save = np.full((12*17*144), np.nan)
label_save[mask] = label
label_save = label_save.reshape(12,17,144)
# =============================================================================================
# save labels
label_nc = xr.Dataset(
{
"label":(("month","lat","lon"), label_save)
},
coords={
"month":time,
"lat":lat,
"lon":lon,
}
)
label_nc.attrs["long_name"] = "K-mean labels"
label_nc.to_netcdf("/Kmean6label.nc")
3、对于聚类的数据进行计算
聚类结束后,可以对于每一类数据进行计算,求平均值、标准差、绘制曲线等等。
# select type of omega
label0 = np.array(np.where(label==0))
label1 = np.array(np.where(label==1))
label2 = np.array(np.where(label==2))
label3 = np.array(np.where(label==3))
label4 = np.array(np.where(label==4))
label5 = np.array(np.where(label==5))
#
numlabel0=len(label0[0,:])
numlabel1=len(label1[0,:])
numlabel2=len(label2[0,:])
numlabel3=len(label3[0,:])
numlabel4=len(label4[0,:])
numlabel5=len(label5[0,:])
# 将二维数据转为一维
w0 = np.array([k[i,:] for i in label0]).squeeze()
w1 = np.array([k[i,:] for i in label1]).squeeze()
w2 = np.array([k[i,:] for i in label2]).squeeze()
w3 = np.array([k[i,:] for i in label3]).squeeze()
w4 = np.array([k[i,:] for i in label4]).squeeze()
w5 = np.array([k[i,:] for i in label5]).squeeze()
# calculate mean
w0_mean = np.nanmean(w0, axis=0)
w1_mean = np.nanmean(w1, axis=0)
w2_mean = np.nanmean(w2, axis=0)
w3_mean = np.nanmean(w3, axis=0)
w4_mean = np.nanmean(w4, axis=0)
w5_mean = np.nanmean(w5, axis=0)
# calculate std
w0_std = np.std(w0, axis=0)
w1_std = np.std(w1, axis=0)
w2_std = np.std(w2, axis=0)
w3_std = np.std(w3, axis=0)
w4_std = np.std(w4, axis=0)
w5_std = np.std(w5, axis=0)
4、聚类个数评估
主要有以下两种方法对于聚类个数的大小进行评估:
1、SSE(簇内误方差)–手肘法
- SSE参数的核心思想就是计算误方差和,SSE的值越小,证明聚类效果越好,随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高,那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。
2、轮廓系数S - 局部轮廓系数最大(极大值),则该值为最优选择。对于下面的代码中,也就是说当s最大值所对应的k值,即为聚类的个数。
# method 1
SSE = []
for i in range(1,11):
km = KMeans(n_clusters=i)
km.fit(k)
#获取K-means算法的SSE
SSE.append(km.inertia_)
plt.plot(SSE)
plt.show()
# method 2
from sklearn.metrics import silhouette_score
S = [] # 存放轮廓系数
for i in range(2,10):
kmeans = KMeans(n_clusters=i) # 构造聚类器
kmeans.fit(k)
S.append(silhouette_score(k,kmeans.labels_,metric='euclidean'))
# plt.plot(S)
# plt.show()
一个努力学习python的海洋
水平有限,欢迎指正!!!
欢迎评论、收藏、点赞、转发、关注。
关注我不后悔,记录学习进步的过程~~
















 5264
5264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











