







学习python踩的坑
写在前面:大家都知道,数据的处理对科研人员来说是重要的。最近老师交给我一个任务,爬取一些关键的信息从PDF或者是网站。PDF中的信息很全,但是一千个读者就有一千个哈姆雷特,想要从PDF中截取有用的信息,我们必须明确什么是目标数据。或者我们要找的数据是不是已经有人将它们全部都汇总到了网页上呢?这样的话,岂不是很省事呢?把刀用在刀刃上,是我一直以来的思想。不过现实生活中,我们总会走些弯路。
- python可以干什么?
听说python是个很神奇的编程语言,无所不能。从网络爬虫、数据分析、数据可视化到web开发、人工智能、自动化测试运维等。
python主要可以做数据分析、数据可视化;网络爬虫,利用python可以从网络上爬取任何格式的数据,比如文本数据、视频、音频等;词云图;web开发。Life is short, You need Python!
- 导入驱动器selenium
selenium是自动化测试套件之一。selenium测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代web浏览器中运行。在爬虫领域,selenium可以解决大部分的网页反爬问题。
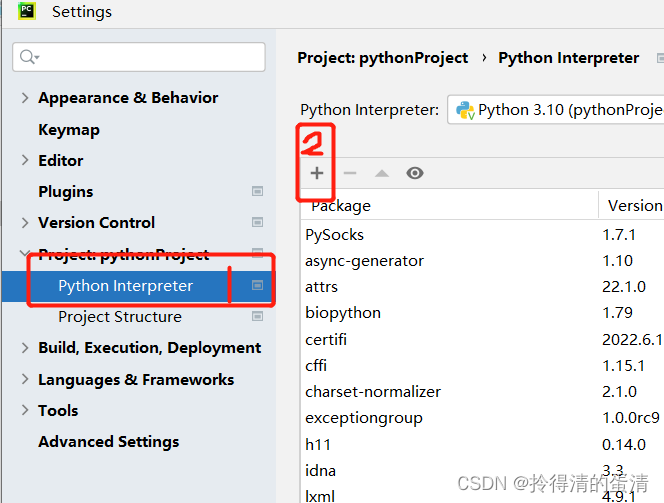
首先,我们需要下载selenium。在我使用的是pycharm
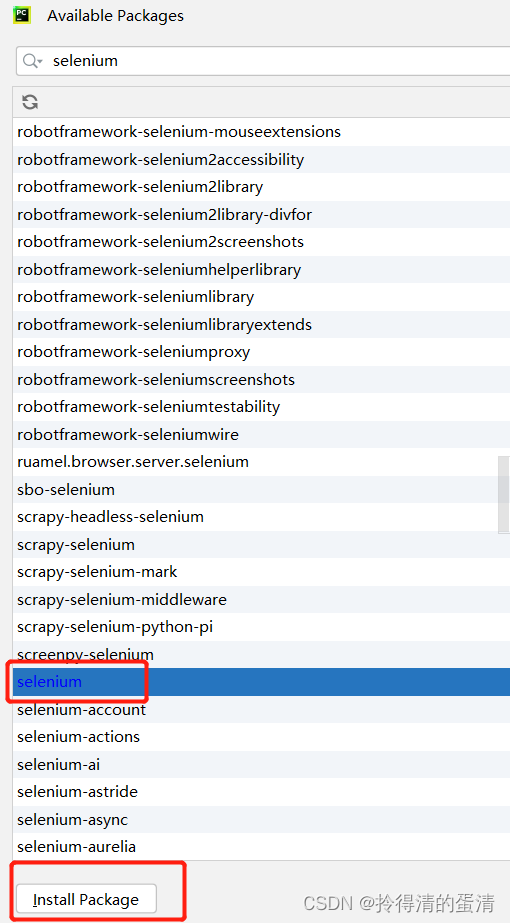
这样我们就可以正常使用selenium这个包了。 - 浏览器驱动器
我们需要知道自己现状使用的浏览器的版本号,下载对应的驱动就行了。

找到我们想要下载的驱动版本号以后,从chrome驱动中找到符合的压缩包,解压安装即可。
将解压后的驱动器保存到我们的文件夹下面即可。
这样我们就可以正常的使用这个驱动器了。 - 调用不到函数。
driver = webdriver.Chrome()
首先呢,我们要保证我们输入的语法是对的,不然的话,是调用不到参数的。
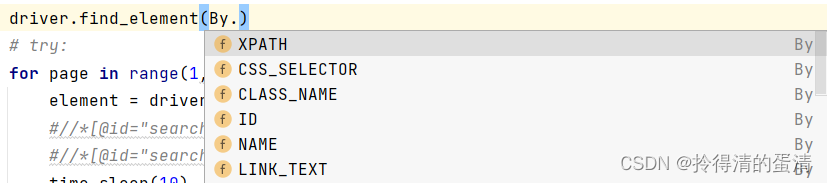
driver.find_element(By.XPATH,'//*[@id="article-return-to-search-link"]')
再有,调用不到find_element_by_css_selector这个函数,是因为我们目前的版本使用的是另一种函数调用规则。find_element(元素定位方法,‘对应的路径’)
4. python用open函数打开文件
打开文件的时候函数是
open(r'E:\pycharm\information.txt','w')
open('E:/pycharm/information.txt','r')
我们可以有两种读入和写入文件的方法。
open('E:\pycharm\information.txt','w')
如果我们使用上面这种编写格式,那么我们就会遇到OSError: [Errno 22] Invalid argument: ‘E:\pycharm\information.txt’
5. 输出list的方法
list_a = [1,2,3,4,5]
for i in range(len(list_a)):
print(list_a[i])
1
2
3
4
5
list_a = [1,2,3,4,5]
for i,j in enumerate(list_a):
print(i)
print(j)
print('====')
0
1
====
1
2
====
2
3
====
3
4
====
4
5
====















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









