







👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

python懂车帝数据可视化(代码+报告)
一、研究背景
在当今社会,汽车已经成为人们生活中不可或缺的一部分,而汽车的购车决策往往受到各种因素的影响。为了更好地了解市场上不同汽车的价格分布情况,以及为购车者提供更全面的信息,我们对懂车帝网站上的汽车数据进行了深入研究和分析。该数据包含了各种品牌和型号的汽车,涵盖了最低价、最高价等关键信息,为我们提供了一个全面洞察汽车市场的机会。
总体而言,通过对懂车帝网站上爬取的汽车数据进行综合分析,我们有望揭示汽车市场中价格的分布特征,为购车者提供更为全面的参考,为汽车制造商提供更为明智的市场定价策略,促使汽车市场更好地满足消费者需求,推动整个行业的可持续发展。
👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇
二、研究目的
本研究的目的在于深入分析懂车帝网站上的汽车数据,主要关注汽车的最低价和最高价这两个关键指标。通过对这些价格数据的综合研究,我们旨在揭示不同汽车在市场上的价格分布情况,以及探究价格背后可能存在的因素。具体而言,我们的研究目的包括以下几个方面
首先,我们旨在了解不同汽车型号的最低价和最高价的分布特征。通过对这两个关键价格指标的统计学分析,我们可以得知市场上汽车价格的整体水平和波动情况。这有助于消费者更全面地了解不同车型在价格上的差异,为购车决策提供更为明智的依据。
其次,我们将通过分析最低价和最高价的最大、最小、中位数和方差等统计指标,揭示价格分布的规律。通过了解价格的最大值和最小值,我们可以确定市场上价格最高和最低的汽车型号,为购车者提供关键信息。同时,中位数和方差的分析将揭示价格的中间趋势和波动幅度,有助于我们更全面地了解市场的价格变化趋势。
三、数据采集过程
3.1 反爬情况
从提供的代码中,虽然没有直接看到网站反爬虫的措施,但我们可以根据代码的一些特征和编写方式来进行分析。以下是一些可能的反爬情况的分析
1. UserAgent头部
代码中设置了请求头的UserAgent字段,模拟了浏览器访问,这是常见的反爬手段。一些网站会检测UserAgent,如果发现是爬虫或非正常浏览器访问,可能会限制或拒绝访问。
headers = {
"UserAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
2. IP封锁或限制
在较为严格的反爬情况下,网站可能会对请求的IP地址进行监控。频繁的大量请求可能导致IP被封锁或限制访问。为了规避这种情况,可以考虑使用代理池,轮换IP进行请求。
3. 请求频率控制
代码中没有显式的设置请求频率控制,但在实际爬取中,为了规避被反爬,建议合理控制请求频率,避免短时间内发送过多请求。
👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇
3.2 爬取过程
这段爬取数据的代码主要包括两个Python脚本懂车帝爬虫.py 和 懂车帝可视化.py。首先,我们来分析懂车帝爬虫.py中的数据爬取过程
1. 爬取数据源
使用requests库向懂车帝网站发送HTTP请求,模拟浏览器访问行为。
通过json()方法解析HTTP响应,获取JSON格式的汽车信息数据。
url = f"https://www.dongchedi.com/motor/pc/car/rank_data?aid=1839&app_name=auto_web_pc&city_name=%E5%8C%97%E4%BA%AC&count=10&offset={i}&month=202311&new_energy_type=&rank_data_type=11&brand_id=&price=&manufacturer=&outter_detail_type=&nation=0"
response = requests.get(url=url, headers=headers)
cars_msg = response.json()["data"]["list"]
👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇
2. 数据提取
使用for循环遍历每一组汽车信息,提取车名、图片链接、最低价、最高价、品牌等关键信息。
将提取的信息以列表形式存储在car列表中。
for message in cars_msg:
car_name = message["series_name"] # 车名
car_img = message["image"] # 图片链接
car_price_lower, car_price_upper = message["price"].split("万")[0].split("") # 最低/高价
car_brand = message["sub_brand_name"] # 商标名称
car.append([car_name, car_brand, car_price_lower, car_price_upper, car_img])
3. 数据保存
将爬取的汽车信息以CSV格式保存在名为data.csv的文件中。
with open('data.csv', 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerows(car)
四、数据展示
4.1 数据预处理
包括处理异常值、缺失值以及计算最高价和最低价之差。不过,如果需要进一步的数据预处理,可以考虑以下几个方面:
数据类型转换:
确保价格列(最低价和最高价)的数据类型为数值型,以便进行后续的统计和可视化操作。
#将最低价和最高价转换为数值型
data['最低价'] = pd.to_numeric(data['最低价'], errors='coerce')
data['最高价'] = pd.to_numeric(data['最高价'], errors='coerce')
# 删除包含缺失值的行
data = data.dropna()
# 或者使用均值进行填充
data['最低价'].fillna(data['最低价'].mean(), inplace=True)
data['最高价'].fillna(data['最高价'].mean(), inplace=True)
其他数据清洗:
根据实际需求进行其他数据清洗操作,比如去除重复值、转换日期格式等。
# 去除重复值
data = data.drop_duplicates()
👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇
4.2 数据可视化
可视化部分的代码主要使用了matplotlib和wordcloud库,涵盖了柱状图、折线图、饼状图以及词云图的绘制。下面对每个可视化部分进行分析
- 柱状图最低价前十名和最高价前十名
使用plt.bar函数分别绘制了最低价和最高价前十名的柱状图,通过颜色的选择使得图表更加直观。图表的横轴为车名,纵轴为价格。这样的柱状图清晰地展示了最低价和最高价的排名前十的车型,方便用户对价格的比较。
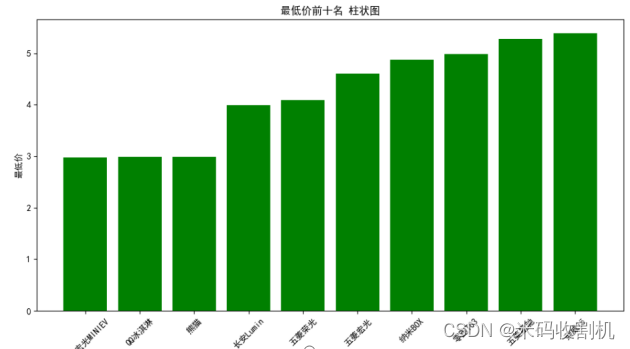
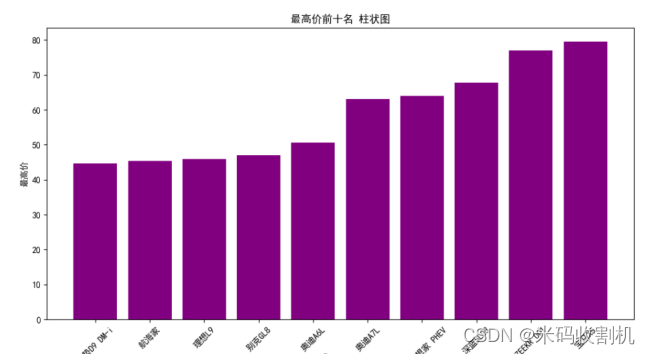
👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇
2. 折线图品牌 vs 最高价
使用plt.plot函数绘制了品牌与最高价的折线图,通过标明不同品牌,观察它们在最高价上的分布情况。这样的折线图有助于观察品牌之间的价格趋势。
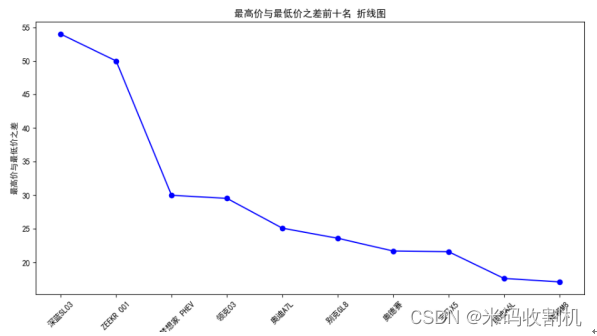
3. 饼状图品牌占比
使用plt.pie函数绘制了品牌占比的饼状图,通过颜色和标签的搭配,直观地展示了不同品牌在数据集中的占比情况。
👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇
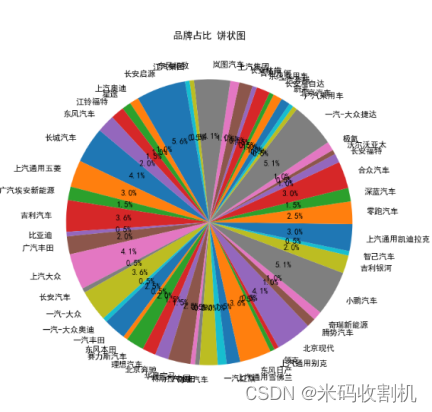
4. 词云图车名词云
使用WordCloud库绘制了车名的词云图。通过将车名的频次转化为图形展示,可以更形象地反映出车名的分布情况。

👇👇👇 关注公众号,回复 “二手车可视化” 获取源码👇👇👇


















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











