






1、定义
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。节点有两种类型:内部节点和叶节点。内部节点表示特征或者属性,叶节点表示一个类。

上图中,圆是内部节点,方框是叶节点。
决策树的学习常用算法有ID3、C4.5与CART。
2、特征选择
特征选择的准则是信息增益或者信息增益比。信息增益表示得知特征X的信息而使类Y的信息的不确定性减少的程度。也就是说,如果我们利用一个特征进行分类,但和随机分类的结果没有很大差别,则称这个特征是没有分类能力的。
划分数据的最大原则,就是将无序的数据变得更加有序。固我们引入熵的概念。熵定义为信息的期望值,表示随机变量不确定性的度量。
记X得概率分布为P(X=xi)=pi,i=1,2……,n
熵可以定义为以下式子:
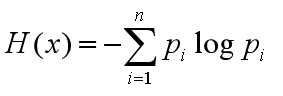
随机变量X给定的条件下随机变量Y的条件熵:
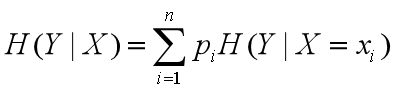
信息增益:
也就是不知道A的时候D的混乱程度-知道A以后D的混乱程度.
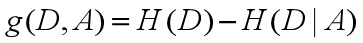
如果存在偏向于选择取值较多的特征的问题,使用信息增益比可以对这一问题进行校正。这是特征选择的另一标准。
信息增益比:
其中
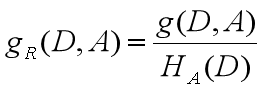
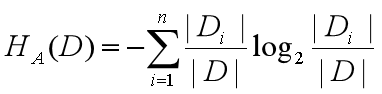
3、决策树的生成
ID3算法:决策树各个节点上应用信息增益准侧选择特征,递归地构建决策树。
C4.5的生成算法:与ID3算法类似,但是使用信息增益比来选择特征。
CART算法:分类与回归树,假设决策树是二叉树,内部结构特征的取值为“是”或“否”,左分支为取值为“是”的分治,右分治为取值“否”的分支。递归地二分每个特征,将输入空间分为有限个单元,并在这些单元上确定预测的概率分布。也就是在输入给定条件下输出的条件概率分布。
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
(1)ID3算法
①若D中实例都属于同一类Ck,则T为单节点数,类Ck,返回T。
②若A=∅,则T为单节点树并将D中实例最大类Ck作为该节点标记,返回T。
③否则,计算A中各特征对D的信息增益、选择信息增益最大的特征Ag。
④Ag小于阈值,则T为单节点树并将D中实例最大类Ck作为该节点标记,返回T。
⑤否则按照Ag=ai分割若干非空子集Di,由结点和它的子结点构成T并返回。
⑥递归调用⑤。
(2)C4.5 类似上
(3)CART算法
i 最小二乘回归树的生成方法:
①选择最优切分变量j与切分点s,求解
遍历j对固定的切分变量j扫描切分点s。
②用选定的(j,s)划分区域并决定相应的输出值;
③对两个子区域重复①②直到满足条件
④将输入空间划分为M个区域生成决策树
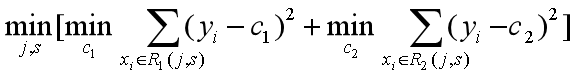
ii CART算法:
1、基尼指数
若样本集合D根据特征A是否取某一可能值a被分割成D1,D2两部分,(D2=D-D1),那么基尼指数定义为:
①对每一个特征A=a计算基尼指数;
②选出基尼指数最小的特征及其对应的切分点作为最优特征和最优切分点
③对子结点递归调用①②
④生成CART决策树
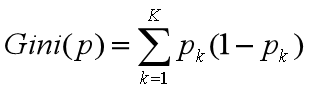
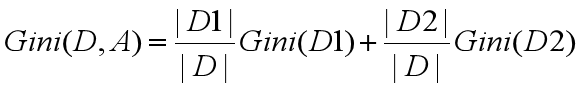
4、剪枝
由于生成的决策树存在过拟合问题,所以需要剪枝。决策树的剪枝往往通过极小化决策树的整体损失函数或代价函数来实现。
sklearn实例:
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train,)
tree_pic = export_graphviz(clf, out_file="mytree.pdf")
with open('mytree.pdf') as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
会生成一棵决策树















 2806
2806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









