







- 特点:
- 一次写入,多次读取(write-once-read-many),降低并发要求控制,监护数据聚合性,支持高吞吐量;
- 将处理逻辑放置到数据附近(比将数据移向应用程序空间更好)
- 数据写入严格限制为,一次一个写入程序。字节被附加到流的末尾,字节流总以写入顺序存储
- HDFS的应用层序几口:
HDFS提供了一个原生的Java应用程序接口(API)和一个针对这个Java API的原生C语言
封装器。另外可以使用web浏览器浏览HDFS文件
- FileSystem(FS) shell:命令行接口,支持与数据进行交互;
- DFSAdmin:管理一个HDFS集群命令集;
- fsck:Hadoop命令/应用程序的一个子命令,用来检查文件的不一致,但不能更正不一致;
- Name Node和 Data Node:拥有内置web服务器,允许管理员检查集群的当前状态
- HDFS架构:
HDFS由互连的节点集群组成,文件和目录驻留在节点上。一个HDFS集群包含一个节点,即
Name Node,用来管理文件系统名称空间并规范客户端对文件的访问。 Data Node将数
据作为块存储在文件中。
-
Name Node和Data Node:
管理一些文件系统名称空间操作,比如:打开、关闭、以及重命名文件和目录。Name Node还将数据块映射到Data Node上,处理来自HDFS客户端的读写请求。Data Node还根据Name Node的指令创建、删除和恢复数据块。

-
Name Node和Data Node之间的关系:
两者是一些软件的组件,以解耦方式跨多个异构操作系统在普通的PC上运行。HDFS是使用Java语言构建的,因此任何支持Java片编程的机器都能运行HDFS。一个典型的安装集群拥有一台专用机器运行NameNode,可能还有一个Data node,集群中其他每台机器上运行一个d=Data Node。
Data Node持续循环,询问Name Node指令。Name Node不能直接连到Data Node,只是从Data Node调用函数返回值。每个Data Node都维护一个开放的服务器套接字,以便客户端代码或其他Data Node能够读写数据。Name Node知道这个服务器的主机或者端口,将信息提供给相关客户端或Data Node
所有HDFS通信协议都构建于TCP/IP协议之上。HDFS客户端连接到Name Node上打开一个Transmission Control Call(TCP)端口,然后使用一个基于Remote Procedure Call(RPC)的专有协议与Name Node通信。Data Note使用一个基于块的专有协议与Name Node通信 -
文件系统名称空间
HDFS支持传统的层级式文件结构,用户或应用程序可以在其中创建目录和保存文件,层级类似于现有大多数文件系统;另外HDFS还支持第三方文件系统,比如CloudStore和Amazon SimpleStorage Service
数据复制:
HDFS复制文件以便容错;在文件创建时指定文件的副本数,也可以随时更改。由Name
Node负责。
-
HDFS使用智能副本放置模型提高可靠性和性能;高效使用网络宽带的,具有机柜意识的副本放置策略能促进优化。
机柜意识:通常,大型HDFS集群跨多个安装点排列,一个安装中的不同节点之间的网络流量通常比跨安装点的网络流量更高效。一个NameNode尽量将一个块的多个副本放置到多个安装上以提高容错能力。但是,HDFS允许管理员决定一个节点属于哪个安装点。因此,每个节点都知道它的机柜ID,即机柜意识。
-
不同安装点中的两个Data Node之间的通信比一个安装点中的两个Data Node之间的通信缓慢,Name Node试图根据机柜ID对Data Node进行优化。
数据组织:
HDFS的一个主要目标是支持大文件。一个典型的HDFS块的大小为64MB。因此,每个HDFS
文件包含一个或多个64MB块,将每个块都放置在独立的DataNode上。
-
文件创建过程
在HDFS上操作文件与其他文件系统类似,但由于HDFS是一个显示为单个磁盘的多机器系统,所有操作HDFS上的文件代码都是用org.apache.hadoop.fs.FileSystem对象的一个子集。
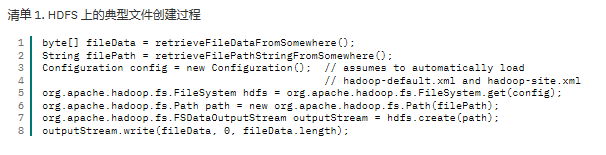
-
提交
当一个客户端在HDFS上创建一个文件是,首先将数据缓存到一个临时本地文件中,然后将后续写入的数据重定向到这个临时文件中。当临时文件积累的数据足以填充一个HDFS块时,客户端向Name Node报告,Name Node将文件转换为一个永久Data Node。然后客户端关闭临时文件,并将剩余的数据注入新创建的Data Node。Name Node然后将Data Node提交到磁盘。 -
复制管道化
当客户端积累了一个完整的用户数据块时,它将从Name Node检索包含那个块的副本的Data Node的列表。然后,客户端将整个数据块注入这个副本列表中指定的第一个Data Node。当Data Node接收数据块时,它将数据块写入磁盘,然后将副本转移到列表的下一个Data Node。管道化过程不断重复,直到复制因子被满足。
数据存储可靠性
HDFS的一个主要目标是可靠存储数据,即使在Name Node、Data Node或网络分区出现
故障,HDFS可以通过心跳消息探测Name Node和Data Node之间的联通性。
-
HDFS心跳:
在一些情况下,Name Node和Data Node之间会丧失联通性。每个Data Node都会定期向Name Node发送心跳信息。如果Name Node不能接收心跳信息,说明Data Node已经死亡,并对此节点标记为死亡Data Node,将来不会向该节点发送请求,并从系统中移除,如果该节点的减少会影响一些数据的复制因子的最小数,则Name Node将启动附加复制,将复制因子带回正常状态。

-
数据块再平衡(保证数据完整性机制):
集群中新增Data Node时需要再平衡,需考虑:块副本写入策略;阻止安装或机柜故障导师的数据丢失;减小跨安装网络IO,跨集群中的Data Node的同一数据分布。 -
数据完整性:
HDFS在文件的内容上使用checksum验证,将计算的checksum保存在实际数据所在的名称空间中的独立隐藏文件里,当客户端检索文件数据时,验证收到的数据是否匹配关联文件中存储的checksum。
HDFS名称空间通过每个 Name node 保存的一个事务日志存储。文件系统名称空间,以及文件块映射和文件系统属性,一并保存在一个名为 FsImage 的文件中。当一个 Name node 初始化时,它读取 FsImage 文件以及其他文件,并应用这些文件中保存的事务和状态信息。 -
同步元数据更新
Name node 使用一个名为 EditLog 的日志文件持久记录对 HDFS 文件系统元数据发生的每个事务。如果 EditLog或 FsImage 文件损坏,它们所属的 HDFS 实例将无法正常工作。因此,一个 Name node 支持多个 FsImage 和 EditLog 文件副本。对于这些文件的多个副本,对任一文件的任何更改都将同步传播到所有副本。当一个 Name node 重新启动时,它使用 FsImage 和 EditLog 的最新统一版本来初始化自身 -
HDFS 的用户、文件和目录权限:
HDFS 对文件和目录实现了一个权限模型,这个模型与 Portable Operating System Interface (POSIX) 模型有很多共同点;例如,每个文件和目录都关联到一个所有者和一个组。HDFS 权限模型支持读取(r)、写入(w)和执行(x)权限。由于 HDFS 中没有文件执行这个概念,x 权限的含义不同。简言之,x 权限表明可以访问一个给定父目录的一个子目录。一个文件或目录的所有者是创建它的客户端进程的身份。组是父目录的组。
参考文献
https://www.ibm.com/developerworks/cn/web/wa-introhdfs/














 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









