






本文章可以作为一个 Spark 数据分析应用的示例,展示了如何从 HDFS 读取数据、处理数据、对结果进行排序和输出。
文章目录
一、什么是spark
Spark是一个开源的大数据处理框架,由Apache软件基金会开发和维护。它提供了高速、通用的数据处理能力,能够在分布式环境中处理大规模数据集。Spark支持多种编程语言,如Scala、Java、Python和R,并提供了丰富的API供开发者使用。它可以以批处理或流处理的方式对数据进行分析、处理和计算,并具备分布式机器学习和图处理的能力。通过内存计算和弹性计算资源的利用,Spark能够实现高效的数据处理和快速的计算速度,已经成为大数据领域的重要工具之一。
二、什么是scala
Scala 是一种多范式编程语言,设计初衷是为了集成面向对象编程和函数式编程的特性。以下是 Scala 的一些关键特点:
多范式: Scala 支持面向对象编程和函数式编程,允许开发者根据需求选择合适的编程范式。
静态类型: Scala 是一种静态类型语言,即在编译时检查类型。这有助于提高代码的可读性和性能。
表达力强大: Scala 具有简洁而表达力强大的语法,允许开发者使用更少的代码表达相同的功能。
运行于 Java 虚拟机: Scala 代码可以在 Java 虚拟机(JVM)上运行,这意味着可以与现有的 Java 代码和库进行互操作。
并发支持: Scala 提供了并发编程的支持,通过 Actor 模型和其他工具,使得编写并发程序更加容易。
不可变性: Scala 鼓励使用不可变对象,这有助于编写线程安全的代码。
类型推断: Scala 具有强大的类型推断功能,有时候可以省略变量的类型声明。
总体而言,Scala 旨在提供一种灵活、表达力强大且与 Java 兼容的编程语言,适用于各种应用场景,从 Web 开发到大规模分布式系统。
三、目的
这段代码是用 Apache Spark 编写的,主要用于处理和分析大规模数据集。这段代码的主要功能是从 HDFS(Hadoop分布式文件系统)中读取数据文件,然后按照商品 ID 对数据进行归并和计算总销售额。最后,对总销售额进行降序排序,并输出销售额最高的前三个商品及其销售额。
四、实现流程
- 导入必要的 Spark 相关类,如 RDD(弹性分布式数据集)和 SparkContext。
- 创建一个 SparkConf 对象,用于设置应用名称、运行模式等配置信息。同时创建一个 SparkContext 对象,用于与 Spark 集群进行通信。

代码示例:
val conf = new SparkConf().setAppName("CitySellTop5").setMaster("local[*]") // 创建 SparkConf 对象,设置应用名称和运行模式
val sc: SparkContext = new SparkContext(conf)
- 指定 HDFS 中的数据文件路径。

代码示例:
val hdfsFilePath = "hdfs://192.168.226.03:9000/datas" // 替换为你的数据文件路径
- 从 HDFS 中读取数据文件,并将每一行数据按制表符(\t)切分为一个字符串数组。

代码示例:
val ListRdd: RDD[Array[String]] = sc.textFile(hdfsFilePath)
.map(line => line.split("\t").map(_.trim))
- 提取特定列数据,例如商品 ID 和总价格,并将结果转换为一个 RDD(弹性分布式数据集)对象。

代码示例:
val ProductRdd: RDD[(String, Float)] = ListRdd.map(
data => (data(4), data(6).toFloat) // 使用索引 4(商品 ID)和 6(总价格)提取数据
)
- 对商品 ID 进行归并并计算总销售额,结果仍是一个 RDD 对象。

代码示例:
val reduceRDD: RDD[(String, Float)] = ProductRdd.reduceByKey(_ + _)
- 对总销售额进行降序排序,得到一个新的 RDD 对象。

代码示例:
val sortASCRDD: RDD[(String, Float)] = reduceRDD.sortBy(_._2, ascending = false)
- 获取前三个商品和其销售额,将结果存储在一个数组中。

代码示例:
val resultArray1: Array[(String, Float)] = sortASCRDD.take(3)
- 打印结果,包括前三个商品的 ID 和销售额。

代码示例:
print(resultArray1.mkString("\n"))
- 最后,关闭 SparkSession。
代码示例:
sc.stop()
五、完整代码
// 导入必要的 Spark 相关类
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} // 导入 Java 转 Scala 集合的库
object ProductSellTop3 {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkConf 并设置应用名称
val conf = new SparkConf().setAppName("CitySellTop5").setMaster("local[*]") // 创建 SparkConf 对象,设置应用名称和运行模式
val sc: SparkContext = new SparkContext(conf)
// 2. 指定 HDFS 中的数据文件路径
val hdfsFilePath = "hdfs://192.168.226.03:9000/datas" // 替换为你的数据文件路径
// 3. 从 HDFS 中读取数据并切分为数组
val ListRdd: RDD[Array[String]] = sc.textFile(hdfsFilePath)
.map(line => line.split("\t").map(_.trim))
// 提取特定列数据,例如商品 ID 和总价格
val ProductRdd: RDD[(String, Float)] = ListRdd.map(
data => (data(4), data(6).toFloat) // 使用索引 4(商品 ID)和 6(总价格)提取数据
)
// 对商品 ID 进行归并并计算总销售额
val reduceRDD: RDD[(String, Float)] = ProductRdd.reduceByKey(_ + _)
// 对总销售额进行降序排序
val sortASCRDD: RDD[(String, Float)] = reduceRDD.sortBy(_._2, ascending = false)
// 获取前三个商品和其销售额
val resultArray1: Array[(String, Float)] = sortASCRDD.take(3)
// 打印结果
print(resultArray1.mkString("\n"))
// 停止 SparkSession
sc.stop()
}
}
六、结果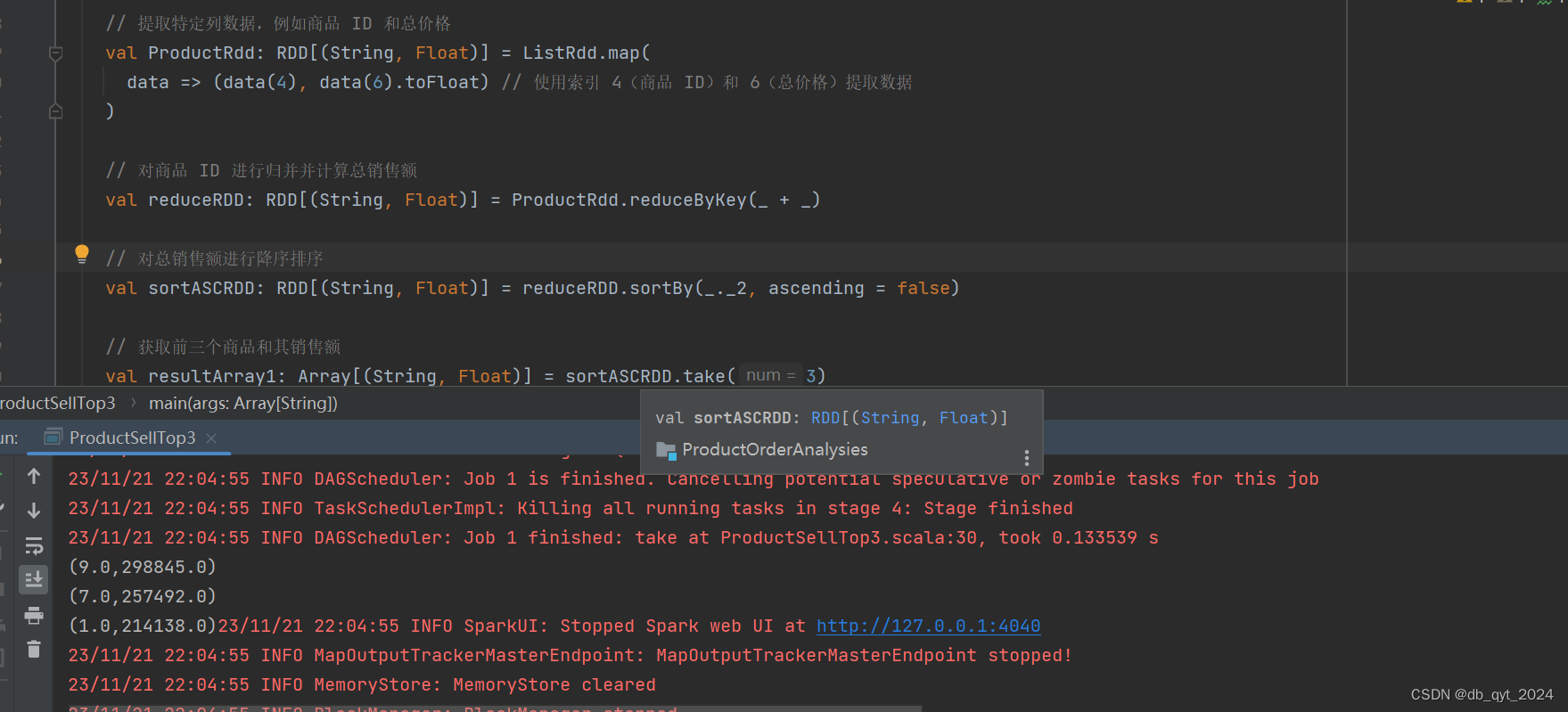
七、总结
本文通过一个实际示例展示了如何使用 Apache Spark 分析 HDFS 数据,并输出前三个销售额最高的商品。文章介绍了代码的五个部分,包括 SparkConf 创建、数据读取、数据处理、排序和输出结果。此示例代码适用于销售数据分析等大规模数据处理场景,并可进一步优化以提高性能。写的不好,情多多指教
















 4633
4633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











