






SSD(Single-shot detectors)
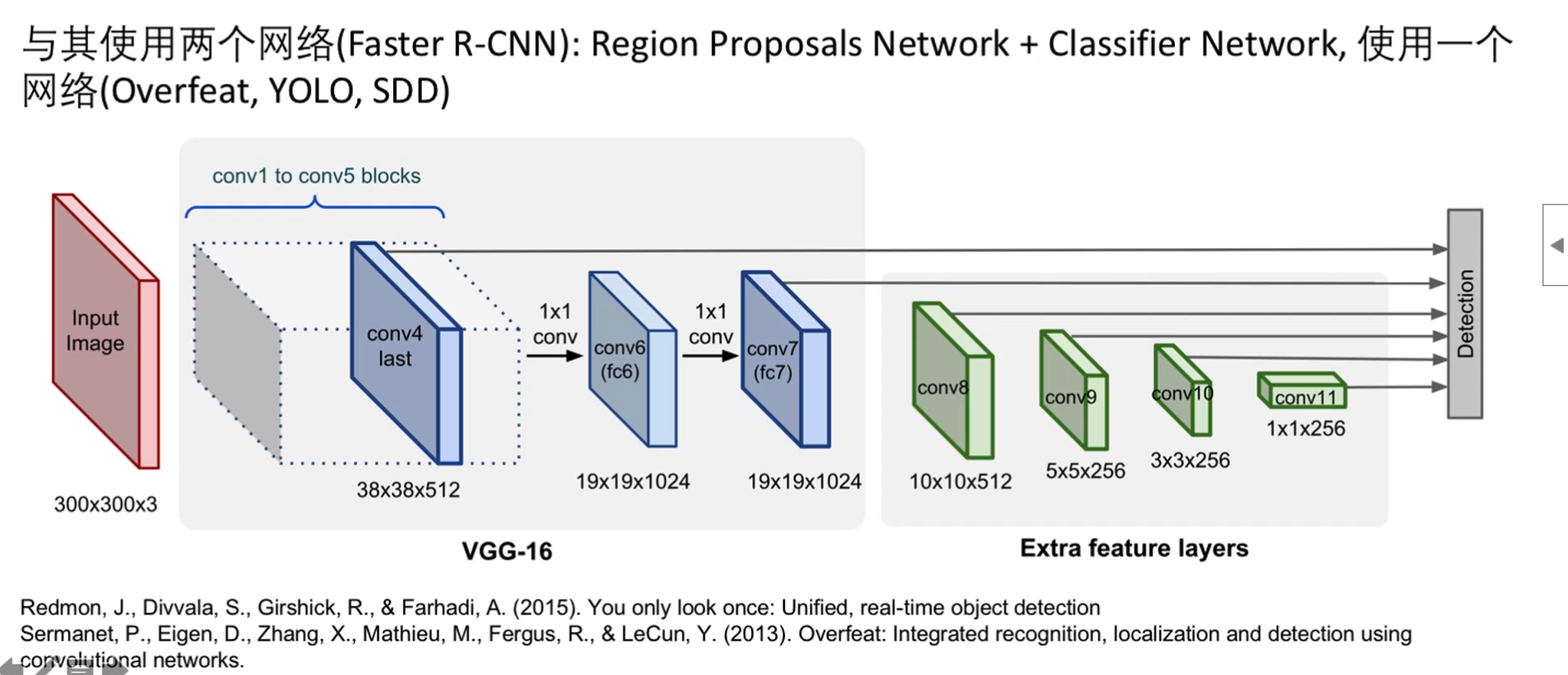
- SSD是一个没有全连接层的网络
- 借鉴了VGG-16的网络模型
- 将VGG-16的第一个和第二个全连接层替换为卷积层
- 去掉了最后一个全连接层
- 加上了4组卷积层(conv8,conv9,conv10,conv11)
- Conv4的输出特征图用于检测最小的物体
- Conv11的输出特征图用于检测最大的物体
Single-shot V.S. R-CNN家族
- R-CNN家族基于候选区域做预测,预测分为两步:
- 使用Selective Search 或者 RPN 选出候选区域,候选区域的数量不大,减少后续的计算量
- 使用分类器和回归器在候选区域上面做分类和边界预测
- Single-shot家族不做候选区域选择,直接对所有可能的区域预测类别和边界
优点
- 比Faster R-CNN更快,比YOLO更准确
- 根据预定义的anchor,使用卷积层的输出,预测anchor对应区域包含的物体类别,边界位置和大小
- 使用不同的卷积层输出预测不同尺寸的物体,为不同的长宽比的物体做单独做预测
- 端到端的训练
什么是目标识别
- 分类:所有类别的概率
- 定位:4个值(中心位置,x,y,宽w,高h)
- 需要为每一个位置的预测(4 + 总的类别数)个值
- 每一个预测器预测一个值,那么对应每次一预测,需要(4 + 总的类别数)个预测器
网络结构
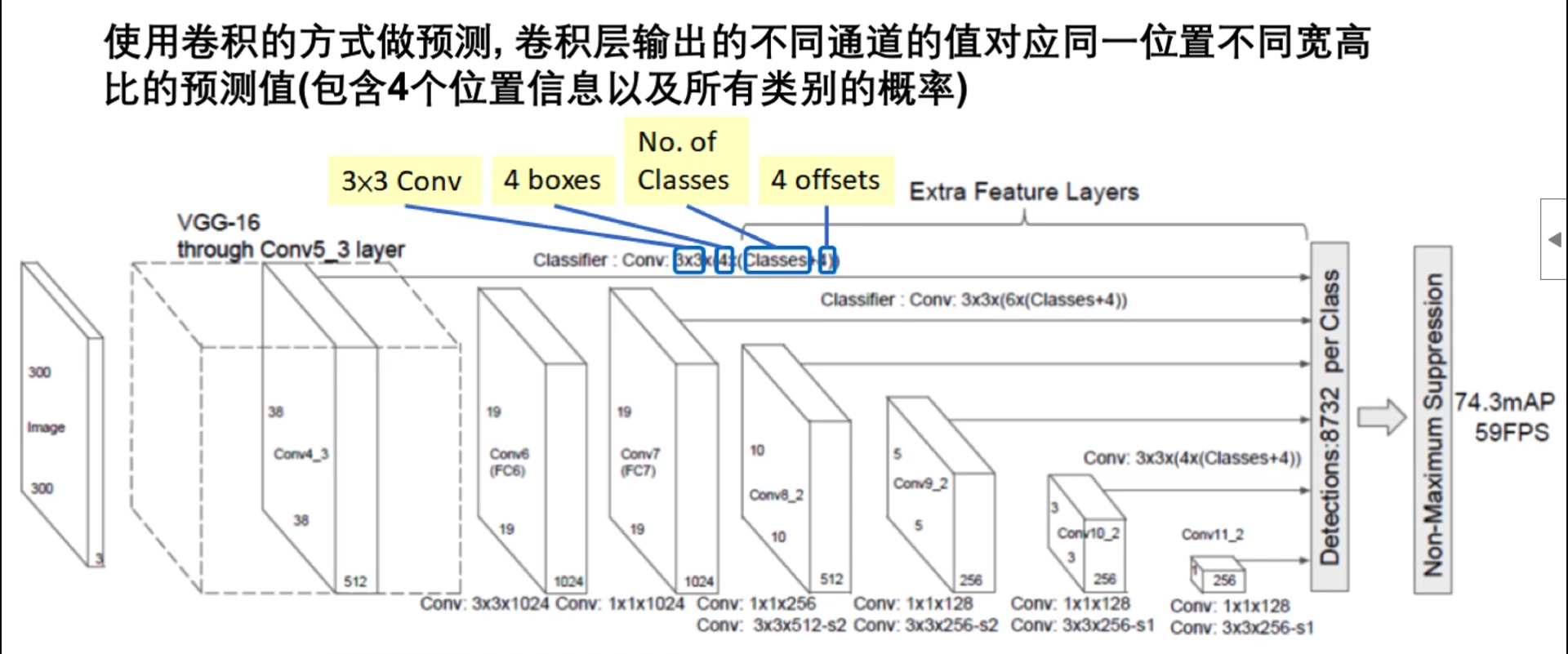

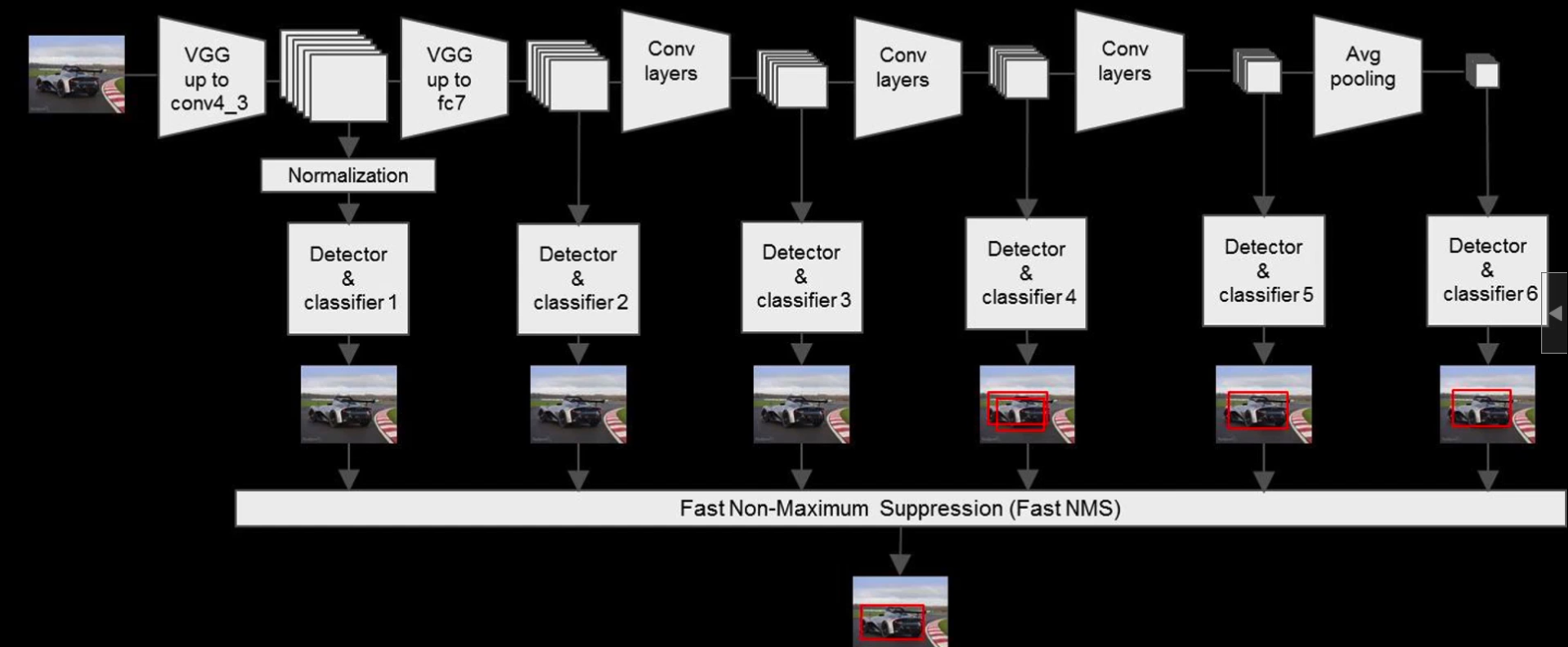
把每一组卷积层的输出都做一次预测

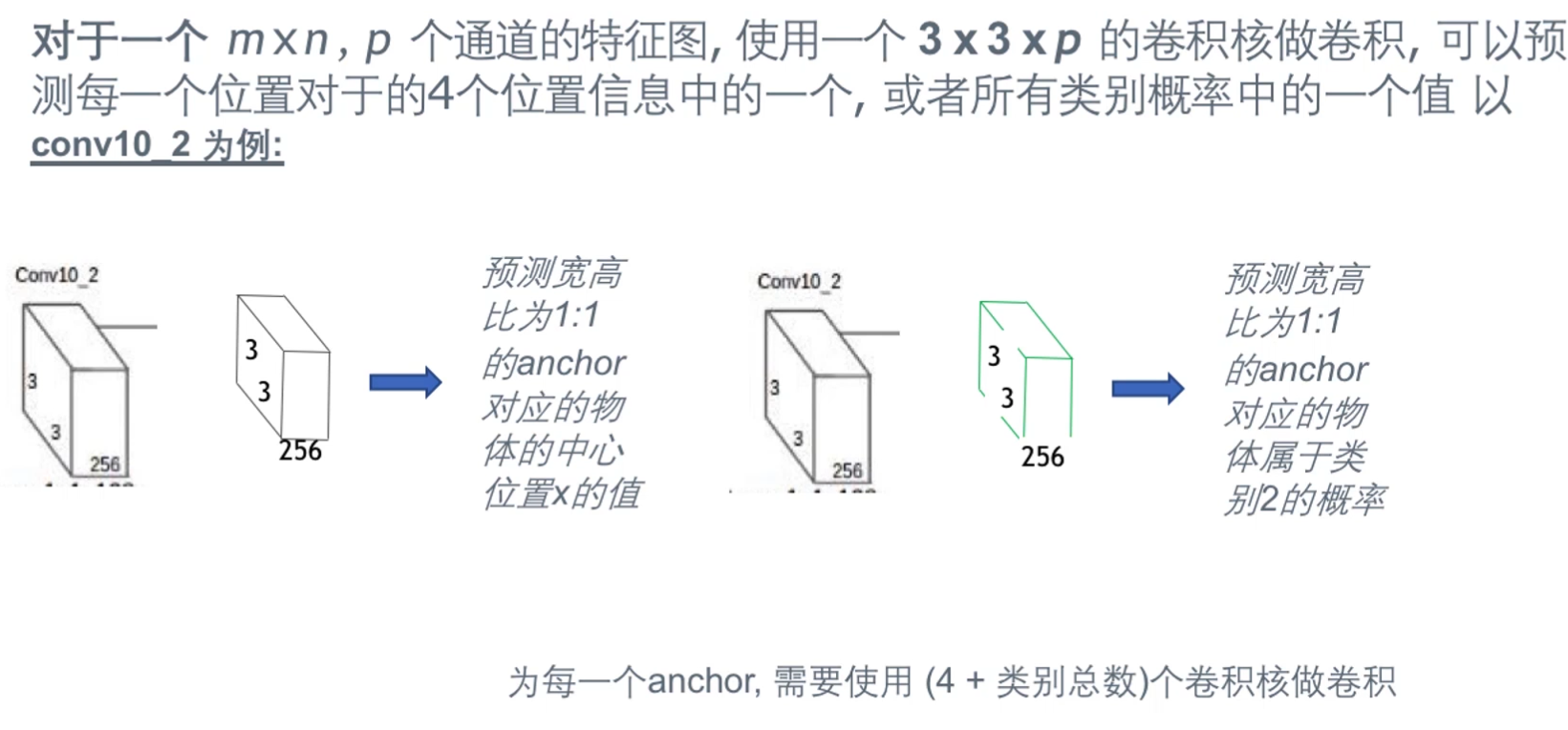
使用卷积做预测
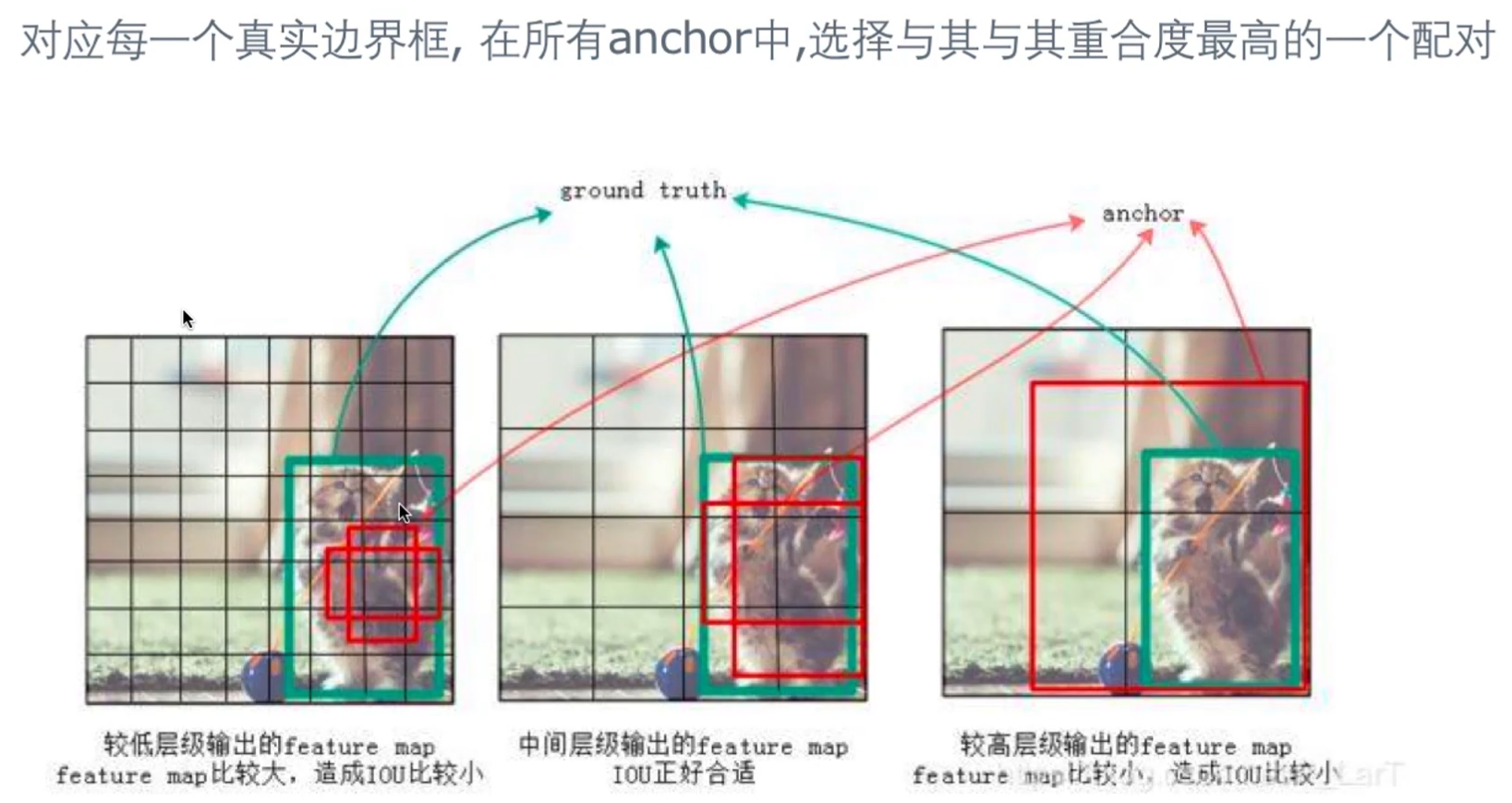
标注的真实边界框与anchor配对
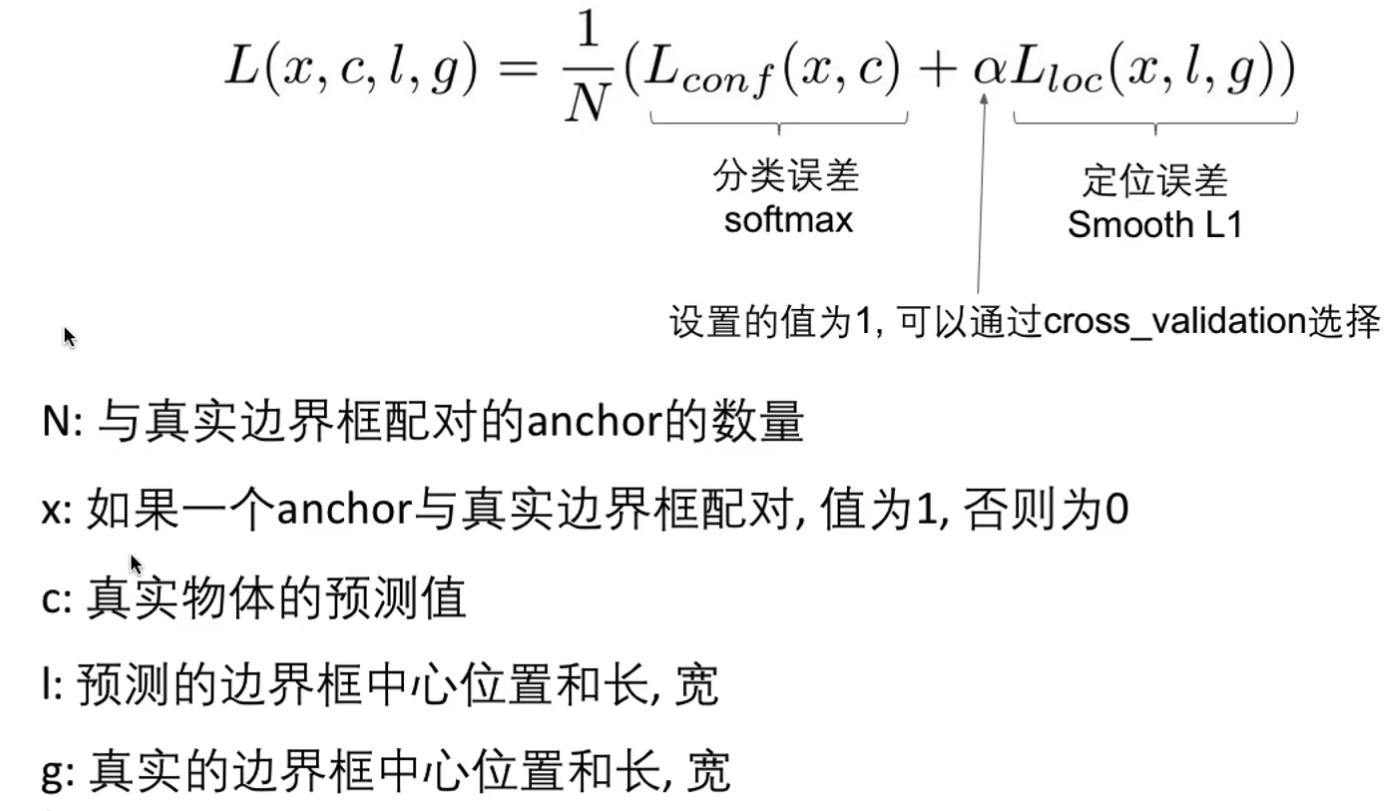
loss损失函数
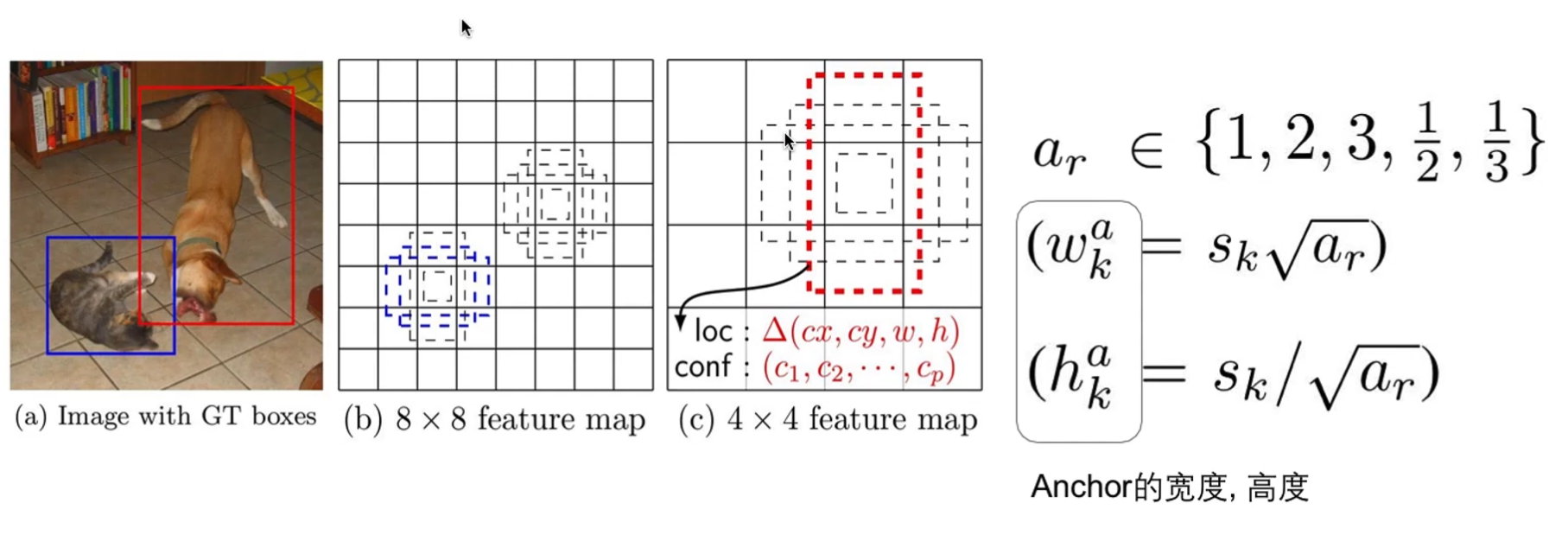
选择anchor的大小

Smin = 0.1 就是卷积层输出像素大小的0.1
选择anchor的宽高比
在每一个特征图的每一个像素点上,选择多个宽高比、
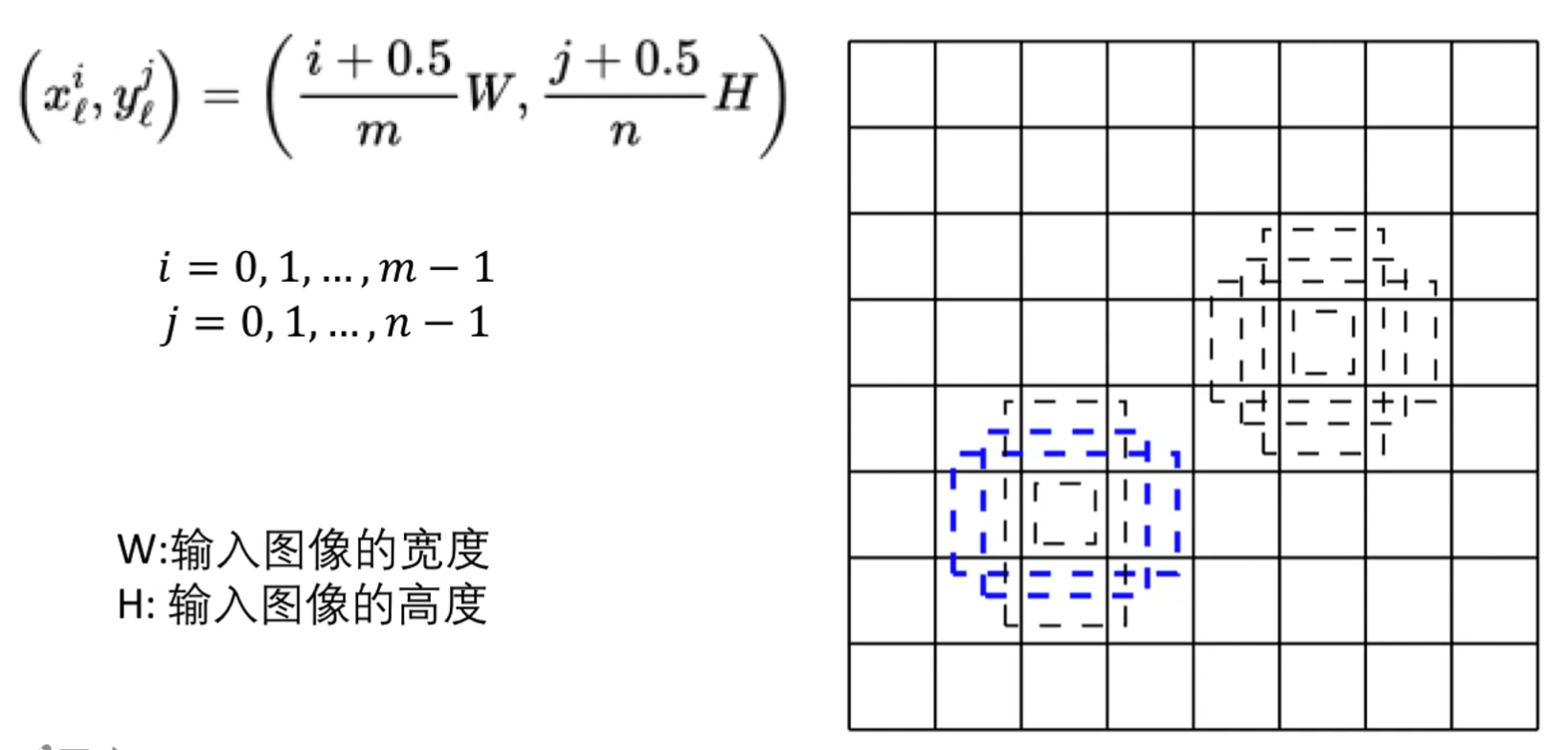
确定anchor的中心位置
使用Hard negative mining生成负样本
产生负样本的方式:所有没有与标注边界框匹配的anchor对应的区域都是负样本
负样本的数量非常大(大于2000),大大超过正样本的量,会造成数据不平衡,可以使用Hard negative mining选择负样本:
- 选择被误认为正样本的负样本中概率值大的那些样本
- 使得正负样本的比率为3:1左右
数据增强

Atrous Convolution(Dilated Convolution)带洞卷积

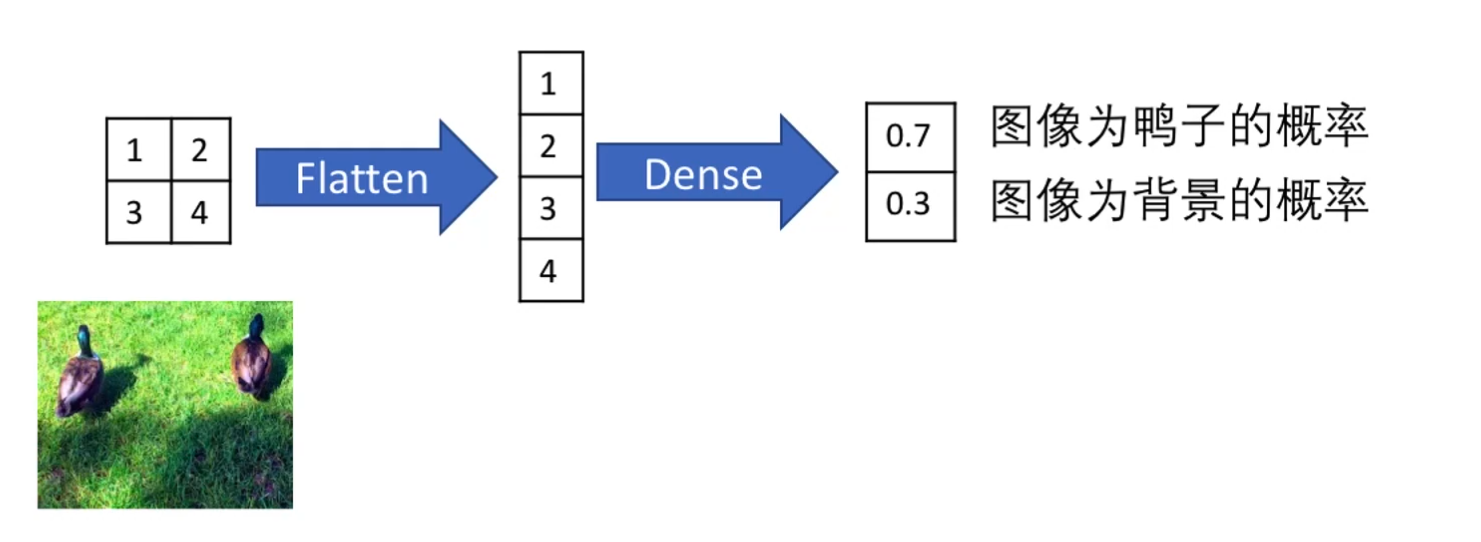
卷积层 + 全连接层预测类别
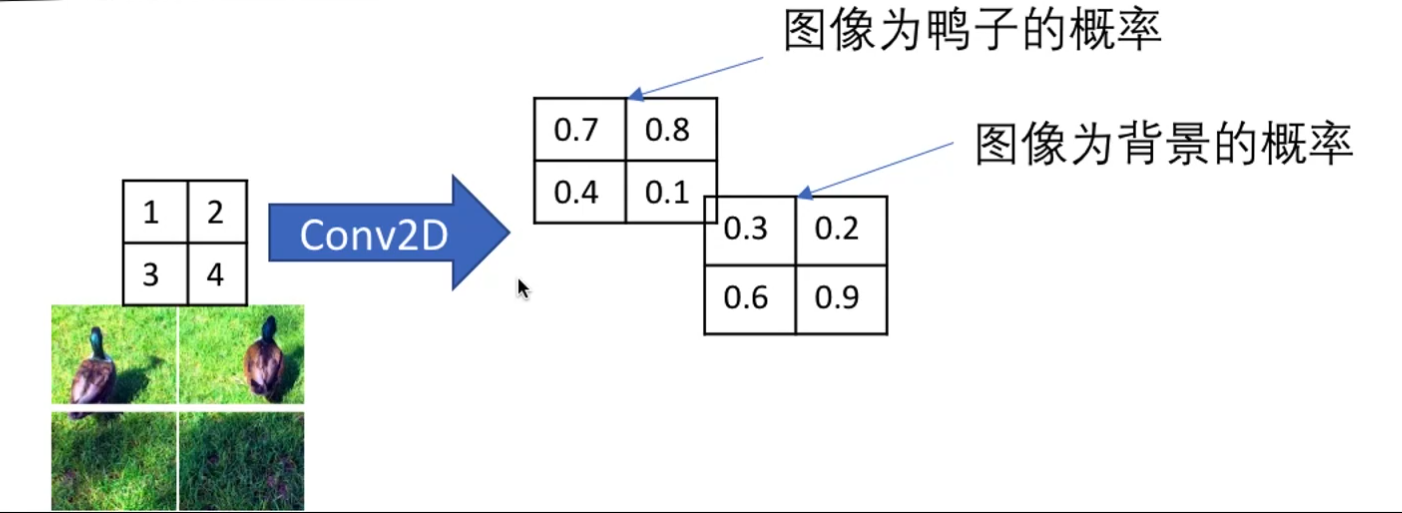
卷积层 + 卷积层预测类别
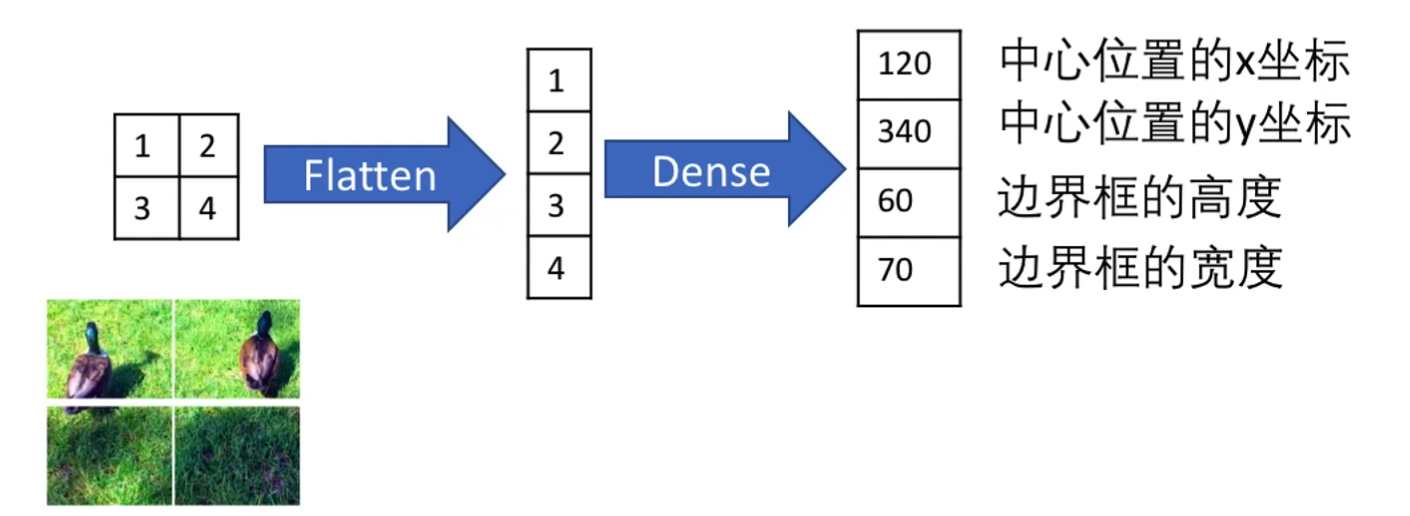
卷积层 + 全连接层预测物体中心位置和高宽
卷积层 + 卷积层预测物体中心位置和高宽
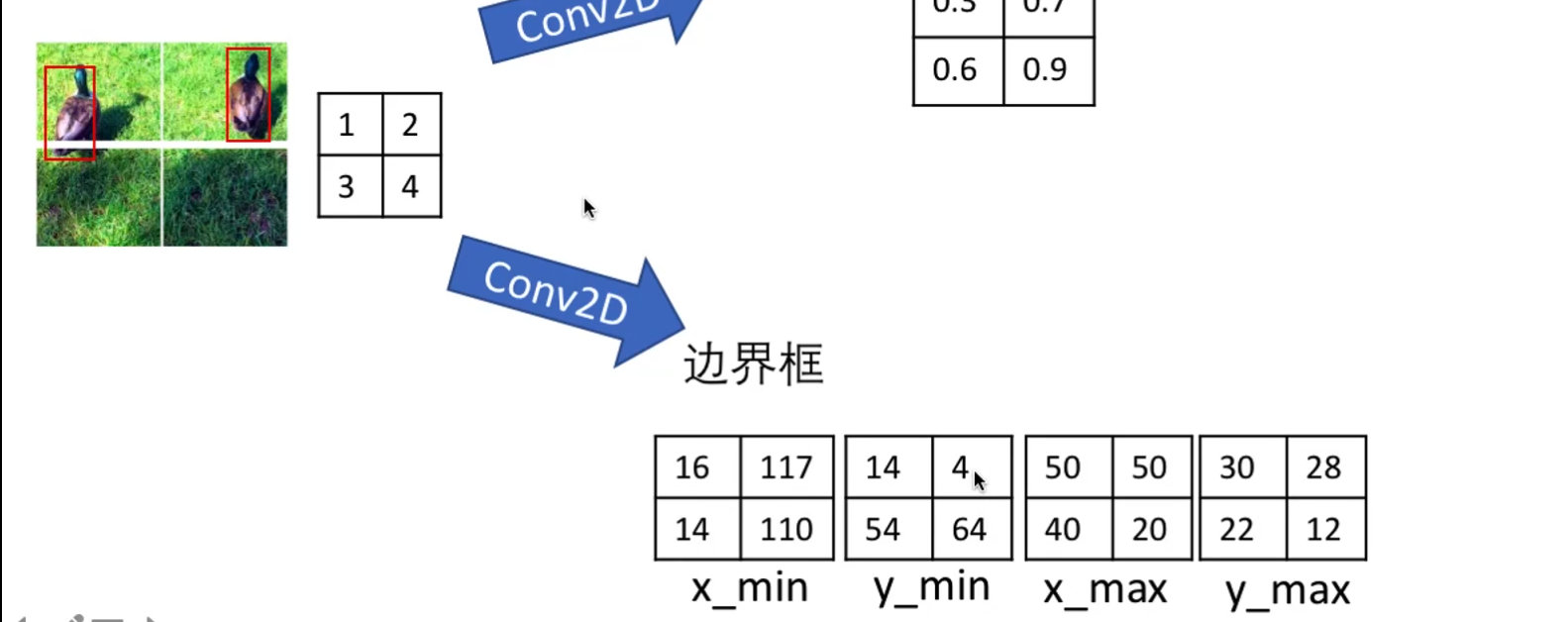
边框的预测使用相对值

Smooth L1 Loss
结合L1的优势(随着x的值增大,梯度的增长是恒定的),L2的优势(当x特别小的时候,梯度迅速减小,减少震荡
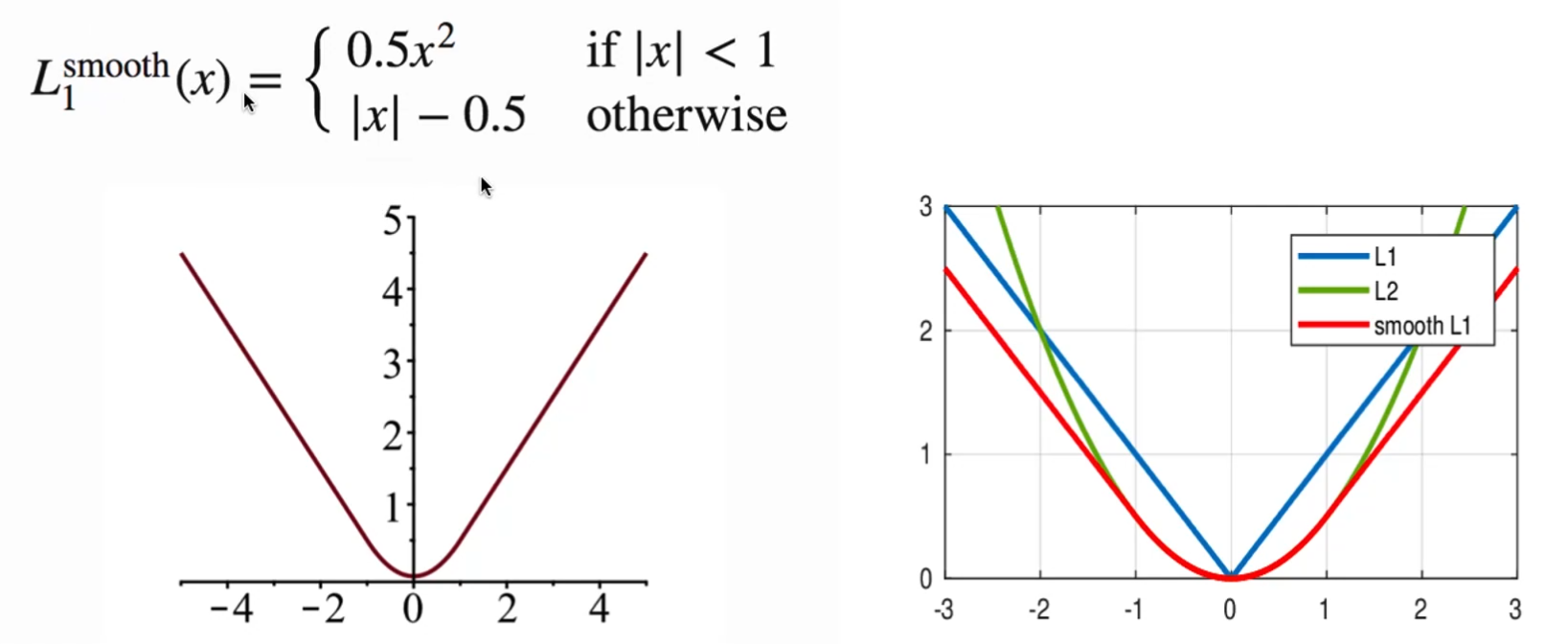
定位的损失函数使用smooth L1 loss来衡量(预测的边界框与anchor的相对值)与[预测的边界框与anchor的相对值]的误差

根据预测的相对值,求预测的绝对值

预测层的滤波器数量
- 预测层的宽和高,等于输入特征图的宽高
- 对应特征图的每一个像素点,需要预测4个包含位置信息的值,加上c个包含类别概率的值,c为总的类别数量(包含背景类别)
- 每一个卷积核为3 x 3 x p 的tensor,其中p为输入特征图的通道数量
- 如果输入的特征图设定为k个anchor boxes,对于m x n像素的特征图,需**k x m x n x (c + 4)**个卷积核
分类损失函数

总的loss

SSD总结
- 多个类别同时定位
- 使用多个卷积层的输出特征图为不同的尺度目标做检测
- 使用的Anchor越丰富,效果越好















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









