







在知乎上写的内容越来越多,于是也想导出来看看是什么情况,结果还真的可以导出成功。于是将过程记录如下。
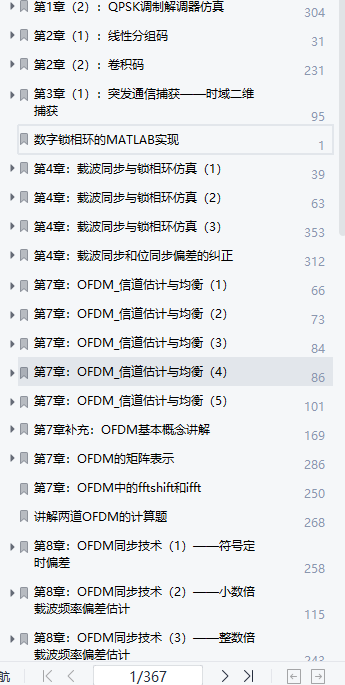
相比手动一篇篇把文章拷贝下来,那肯定枯燥无味,又非常累,像这种重复性的工作,由计算机程序来完成最为合适。
在github上面一搜,果然有程序帮助实现这个功能,代码是python,代码下载地址:https://github.com/ronething/ZhiHuZhuanLanToPDF
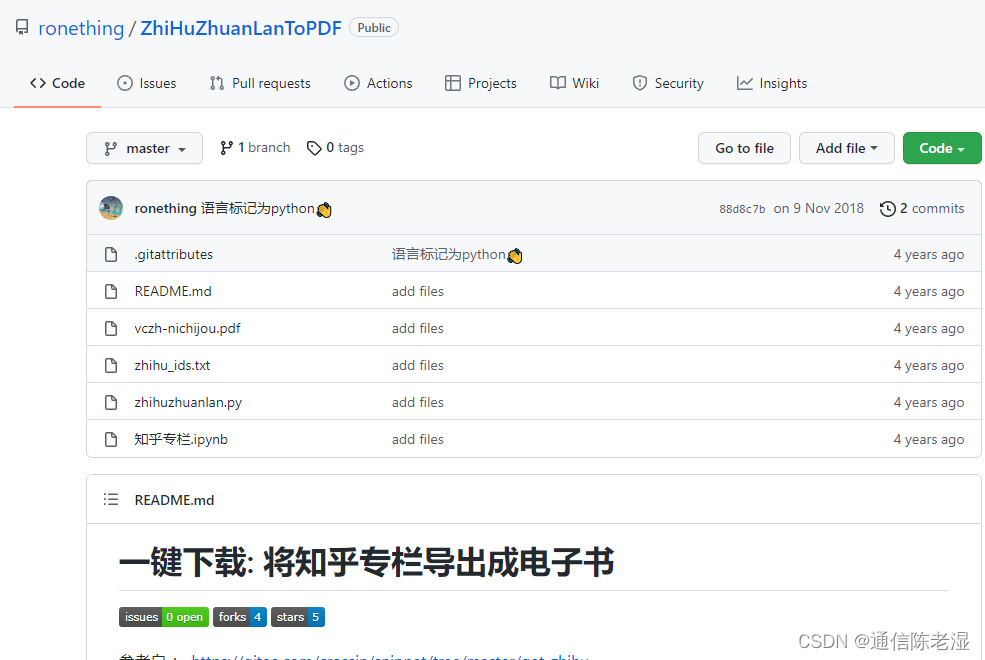
我之前没太用过python,所以下面就从最开始安装python说起。
一、安装python环境
人家是python代码,那我肯定有一个软件来执行这个代码,我下的是visual studio 2019,学习怎么运行python。
Visual Studio 中的 Python 教程步骤 1,创建项目 | Microsoft Docs
Visual Studio 中的 Python 教程步骤 2,编写和运行代码 | Microsoft Docs
然后把下载来的python代码,放到同一个项目中。

点击左下角的python环境,安装三个包:requests、bs4、pdfkit
二、适当修改
1、将author中的单引号内容,换成自己的专栏名字
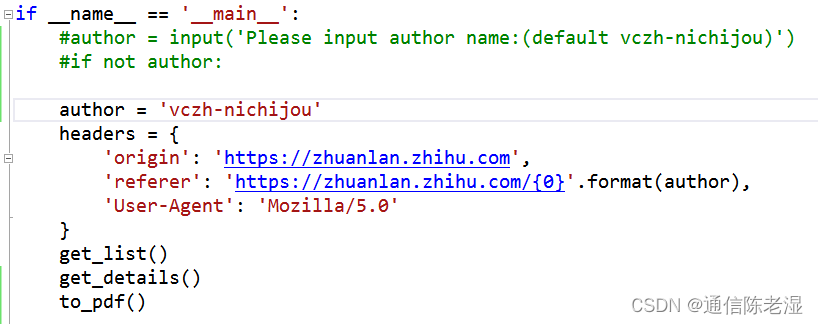
2、修改get_html
要将soup = BeautifulSoup(html, 'lxml')这一行换成soup = BeautifulSoup(html, 'html.parser'),原因如下:Python3.6爬虫报错处理bs4.FeatureNotFound: Couldn't find a tree builder wi_夏草v的博客-CSDN博客_bs4.featurenotfound
3、用wkhtmltopdf转成pdf

代码中给出了两种由html转pdf的函数,一个是to_pdf(),一个是get_args(),都需要用到wkhtmltopdf,在下面这个网址也给出了下载链接。
https://github.com/ronething/ZhiHuZhuanLanToPDF
安装完wkhtmltopdf后,需要添加到环境变量。
(1)电脑->属性->高级系统设置->环境变量->点击系统变量的Path
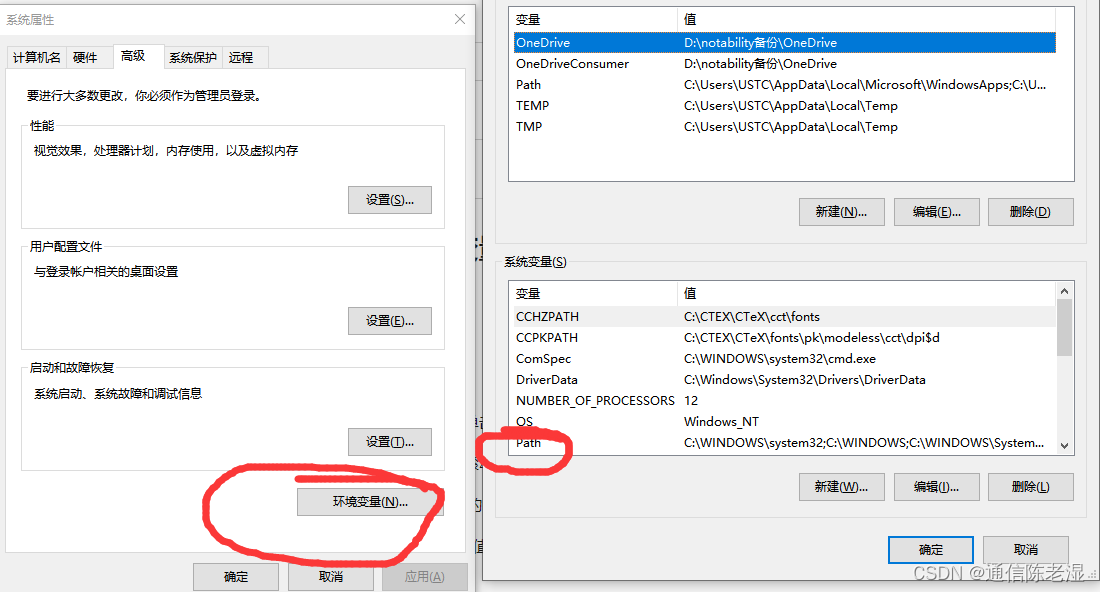
(2)再点击编辑->编辑文本->然后把wkhtmltopdf安装的位置放进变量值里面,注意前后有分号“;”
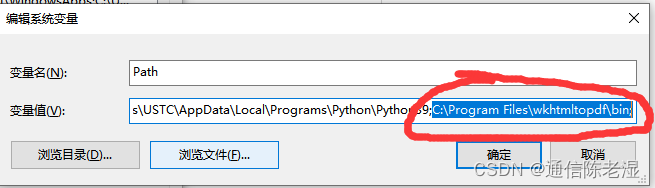
4、to_pdf
需要在to_pdf中的import,后面增加一行。
def to_pdf():
import pdfkit
config=pdfkit.configuration(wkhtmltopdf=r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe")
print('exporting PDF...')
htmls = []
for root, dirs, files in os.walk('.'):
print(root)
print(dirs)
print(files)
htmls += [name for name in files if name.endswith(".html")]
print(htmls)
pdfkit.from_file(sorted(htmls), author + '.pdf',configuration=config)
print("done")5、右键zhihuzhuanlan.py将其设置为启动文件
6、点击“启动”

7、在PythonApplication1相同路径位置处,就出现了一份pdf。
三、留有问题
1、上面我只将to_pdf试验成功了,get_args没有试验成功。
2、导出来的Pdf,优点:文章链接还保存,文字都有。缺点:文字偏小,原文中图片较大的有的放不下,想数学公式不能正常显示。


针对图片显示和文字排版的问题,增加下面几行代码:
content = '<!DOCTYPE html><html><head><meta charset="utf-8"></head><body><h1>%s</h1>%s%s</body></html>' % (
title, content,strmath)
str = """
<style>
body {
margin: 0 50px;
}
p {
text-indent: 2em;
} # 文字首行缩进2em
img {
width: 100%;
} # 图片显示中间 不超出
pre {
white-space: pre-wrap;
word-wrap: break-word;
} # 代码段自动换行
.ztext-math {
display: inline-block;
}
</style>
"""
content = content + str
with open(file_name, 'w', encoding='utf-8') as f:
f.write(content)
time.sleep(2)针对数学公式显示的问题,讲下面这一句放入到Content之前:
strmath = '<script src="https://cdn.staticfile.org/mathjax/2.7.1/MathJax.js?config=TeX-AMS-MML_HTMLorMML" ' \
'async></script>' #解析数学公式在解析公式的时候需要有一定的时间,'javascript-delay':'10000'。
config = pdfkit.configuration(wkhtmltopdf=r"D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe")
optionstemp = {
'enable-local-file-access': '--enable-local-file-access',
'enable-internal-links': '--enable-internal-links',
'enable-javascript':'--enable-javascript',
# 'javascript - delay' :'--javascript - delay < 300 >',
'javascript-delay':'10000',
'no-stop-slow-scripts':'--no-stop-slow-scripts',
'debug-javascript':'--debug-javascript',
'enable-forms':'--enable-forms',
'disable-smart-shrinking':'--disable-smart-shrinking'
}
print('exporting PDF...')
htmls = []
for root, dirs, files in os.walk('.'):
print(root)
print(dirs)
print(files)
htmls += [name for name in files if name.endswith(".html")]
print(htmls)
# pdfkit.from_file(sorted(htmls), author + '.pdf', configuration = config, options={"enable-local-file-access":True})
pdfkit.from_file(sorted(htmls), author + '.pdf', configuration=config,
options=optionstemp)
print("done")较为完整的关键代码如下:
def get_html(aid, title, index):
title = re.sub('[\/:*?"<>|]', '-', title) # 正则过滤非法文件字符
print(title)
file_name = '%03d. %s.html' % (index, title)
if os.path.exists(file_name):
print(title, 'already exists.')
return
else:
print('saving', title)
url = 'https://zhuanlan.zhihu.com/p/' + aid
html = requests.get(url, headers=headers).text
# 知乎图床重处理(此处储存的是品质略差的图片)
# html = re.sub(r'<noscript>.*?</noscript>', '', html)
# ImgObj = re.findall(r'<img .*?/>', html)
# for item in ImgObj:
# if r'data-actualsrc' in item:
# srcObj = re.findall(r'src="(.*?)"', item)[0]
# actualObj = re.findall(r'data-actualsrc="(.*?)"', item)[0]
# html = html.replace(srcObj, actualObj, 1)
#soup = BeautifulSoup(html, 'lxml')
soup = BeautifulSoup(html, 'html.parser')
try:
content = soup.find("div", {"class": "Post-RichText"}).prettify()
except:
print("saving", title, "error")
return
content = content.replace('data-actual', '')
content = content.replace('h1>', 'h2>')
content = re.sub(r'<noscript>.*?</noscript>', '', content)
content = re.sub(r'src="data:image.*?"', '', content)
# strmath = '''
# <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS-MML_HTMLorMML"></script>
# <script type="text/x-mathjax-config"> MathJax.Hub.Config({ tex2jax: {inlineMath: [['$', '$']]}, messageStyle: "none" });</script>
# '''
# strmath = '<script src="https://cdn.staticfile.org/mathjax/3.2.2/MathJax.js?config=TeX-AMS-MML_HTMLorMML" ' \
# 'async></script>' #错误不能运行
strmath = '<script src="https://cdn.staticfile.org/mathjax/2.7.1/MathJax.js?config=TeX-AMS-MML_HTMLorMML" ' \
'async></script>' #解析数学公式
# strmath = '<script src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.5/MathJax.js?config=TeX-AMS_HTML" ' \
# 'async></script>'
# strmath = '<script src="https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.2/MathJax.js?config=TeX-AMS-MML_HTMLorMML" ' \
# 'async></script>'
# strmath = '<script src="https://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS_HTML,http://myserver.com/MathJax/config/local/local.js" ' \
# 'async></script>' #html不正确
content = '<!DOCTYPE html><html><head><meta charset="utf-8"></head><body><h1>%s</h1>%s%s</body></html>' % (
title, content,strmath)
str = """
<style>
body {
margin: 0 50px;
}
p {
text-indent: 2em;
} # 文字首行缩进2em
img {
width: 100%;
} # 图片显示中间 不超出
pre {
white-space: pre-wrap;
word-wrap: break-word;
} # 代码段自动换行
.ztext-math {
display: inline-block;
}
</style>
"""
content = content + str
with open(file_name, 'w', encoding='utf-8') as f:
f.write(content)
time.sleep(2)
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









