







在NLP中,分词(tokenization,也称分词)是一种特殊的文档切分(segmentation)过程。而文档切分能够将文本拆分成更小的文本块或片段,其中含有更集中的信息内容。文档切分可以是将文档分成段落,将段落分成句子,将句子分成短语,或将短语分成词条(通常是词)和标点符号。
文章目录
1.简单分词
1.1split分词
对句子进行切分的最简单方法就是利用字符串中的空白符来作为词的“边界”。在python中可以通过标准库方法split来实现这种操作。
sentence = """Thomas Jefferson began building Monticello at the age of 26."""
print(sentence.split())
Out[1]:[‘Thomas’, ‘Jefferson’, ‘began’, ‘building’, ‘Monticello’, ‘at’, ‘the’, ‘age’, ‘of’, ‘26.’]
正如大家看到的那样,split方法已经对这个简单的句子进行了相当不错的分词处理,仅仅在最后那个词上出现一条“错误”,即将句尾的标点符号也归入词条当中而得到“26.”通常来说,我们都希望句子中的某个词条和周围的标点符号及其他有意义的词条分开。“26.”是浮点数26.0的完美表示结果,但是这样的话,它和出现在语料库句子中的“26”及可能出现在问句句尾的"26?"就完全不是一回事了。一个优秀的分词器应该去掉上面词条中的额外的字符而得到“26”,它是词”26,“”26!“”26?“”26.“的等价类表示结果。此外一个更为精确的分词器应该也将句尾的标点符号作为词条输出,这样句子切分工具或者边界检测工具才能确定句子的结束位置。
1.2独热向量
我们构建每个词的数值向量表示,这些向量称为独热向量(one-hot vector)。这些向量构成的序列能够以向量序列(数字构成的表格)的方式完美捕捉原始文本。
sentence = """Thomas Jefferson began building Monticello at the age of 26."""
import numpy as np
token_sequence = sentence.split() # split是当前临时应急的分词器
vocab = sorted(set(token_sequence)) # 列举所有想要记录的独立词条(词)
print(','.join(vocab))
num_tokens = len(token_sequence)
vocab_size = len(vocab)
onehot_vectors = np.zeros((num_tokens, vocab_size), int)
for i, word in enumerate(token_sequence): # 对于句子中的每个词,将词汇表中与该词对应的列标为1
onehot_vectors[i, vocab.index(word)] = 1
print(onehot_vectors)
Out[1]:26.,Jefferson,Monticello,Thomas,age,at,began,building,of,the
Out[2]:
[
[0 0 0 1 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[0 0 1 0 0 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 0 0 0 1]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 0 0 0 1 0]
[1 0 0 0 0 0 0 0 0 0]]
为了让结果看起来更加清晰明朗,我们引入行列,并且将0替换成空格
import pandas as pd
df = pd.DataFrame(onehot_vectors, columns=vocab)
df[df == 0] = ''
print(df)
Out[1]: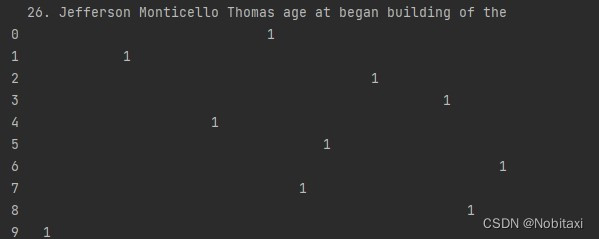
上述表格的每一行都是一个二值的行向量,这就是该向量称为独热向量的原因:这一行的元素除一个位置之外都是0或者空白,而只有该位置上是”热“的(为1)。我们可以在NLP流水线中使用向量[0,0,0,0,0,0,1,0,0,0]来表示词”began“。
1.3词袋向量
上述基于独热向量的句子表示方法保留了原始句子的所有细节,包括语法和词序。但是,相对于上述的短句子而言的整个表格却很大,对长文档来说这种做法不太现实。如果把所有的独热向量加在一起,而不是一次一次地”回放“它们,我们会得到一个词袋向量。这个向量也被称为词频向量,因为它只计算了词的频率,而不是词的顺序。
sentences = """Thomas Jefferson began building Monticello at the age of 26.\n"""
sentences += """Construction was done mostly by local masons and carpenters.\n"""
sentences += """He moved into the South Pavilion in 1770.\n"""
sentences += """Turning Monticello into a neoclassical masterpiece was Jefferson's obsession."""
corpus = {}
for i, sent in enumerate(sentences.split('\n')):
corpus['sent{}'.format(i)] = dict((token, 1) for token in sent.split())
df = pd.DataFrame.from_records(corpus).fillna(0).astype(int).T
print(df)
Out[1]:
2.度量词袋之间的重合度
用点积来判断两个句子的相似度
df = df.T
print(df['sent0'].dot(df['sent1']))
print(df['sent0'].dot(df['sent2']))
print(df['sent0'].dot(df['sent3']))
Out[1]:0
Out[2]:1
Out[3]:1
结果表明有一个词同时出现在sent0和sent2中,同理,某个词同时出现在sent0和sent3中。词之间的重合度可以作为句子相似度的一种度量方法。
下面给出了一种找出sent0和sent3当中那个共享词的方法。
print([(k, v) for (k, v) in (df['sent0'] & (df['sent3'])).items() if v])
Out[1]:[(‘Monticello’, 1)]
3.标点符号的处理
3.1正则表达式
import re
sentence = """Thomas Jefferson began building Monticello at the age of 26."""
pattern = re.compile(r'([-\s.,;!?])+')
tokens = pattern.split(sentence)
print(tokens)
print([x for x in tokens if x and x not in '- \t\n.,;!?'])
Out[1]:[‘Thomas’, ’ ', ‘Jefferson’, ’ ', ‘began’, ’ ', ‘building’, ’ ', ‘Monticello’, ’ ', ‘at’, ’ ', ‘the’, ’ ', ‘age’, ’ ', ‘of’, ’ ', ‘26’, ‘.’, ‘’]
Out[2]:[‘Thomas’, ‘Jefferson’, ‘began’, ‘building’, ‘Monticello’, ‘at’, ‘the’, ‘age’, ‘of’, ‘26’]
3.2NLTK
from nltk.tokenize import RegexpTokenizer
sentence = """Thomas Jefferson began building Monticello at the age of 26."""
tokenizer = RegexpTokenizer(r'\w+|$[0-9.]+|\S+')
print(tokenizer.tokenize(sentence))
Out[1]:[‘Thomas’, ‘Jefferson’, ‘began’, ‘building’, ‘Monticello’, ‘at’, ‘the’, ‘age’, ‘of’, ‘26’, ‘.’]
一个更好的分词器来自NLTK包中的TreebankWordTokenizer分词器,它内置了多种常见的英语分词规则,例如,它从相邻的词条中将短语结束符号(?!.;,)分开,将包含句号的小数当成单个词条。此外,它还包含一些英语缩略语的规则,例如,”don‘t“会切分成[“do”,“n’t”]。该分词器将有助于NLP流水线的后续步骤,如词干还原。
from nltk.tokenize import TreebankWordTokenizer
sentence = """Monticello wasn't designated as UNESCO World Heritage Site until 1987."""
tokenizer = TreebankWordTokenizer()
print(tokenizer.tokenize(sentence))
Out[1]:[‘Monticello’, ‘was’, “n’t”, ‘designated’, ‘as’, ‘UNESCO’, ‘World’, ‘Heritage’, ‘Site’, ‘until’, ‘1987’, ‘.’]
3.3缩略语
对一些应用来说,例如使用句法树的基于语法的NLP模型,将wasn’t分成was和not很重要,这样可以使句法树分析器能够将与已知语法规则保持一致并且可预测的词条集作为输入。存在大量标准和非标准的缩略词处理方法。通过将缩略语还原为构成它的各个词,只需要对依存树分析器或者句法分析器进行编程以预见各词的不同拼写形式,而不需要面对所有可能的缩略语。
NLTK库中包含一个分词器casual_tokenize,该分词器用于处理来自社交网络的非规范的包含表情符号的短文本。
casual_tokenize函数可以剥离文本中的用户名,也可以减少词条内的重复字符数。
from nltk.tokenize.casual import casual_tokenize
message = """RT @TJMonticello Best day everrrrrrr at Monticello.Awesommmmmmeeeeeeee day :*)"""
print(casual_tokenize(message))
print(casual_tokenize(message, reduce_len=True, strip_handles=True))
Out:
4.将词汇表扩展到n-gram
4.1 n-gram
n-gram是一个最多包含n个元素的序列,这些元素从由它们组成的序列(通常是字符串)中提取而成。例如2-gram可以指的是两个词构成的队,如“ice cream”。
当一个词条列向量化成词袋向量时,它丢失了词序中所包含的很多含义。如果不考虑n-gram,那么单词“not”就会自由漂移,而不会固定在某几个词周围,其否定的含义可能就会与整个句子甚至整篇文档,而不是只与某几个相邻词关联。
from nltk.util import ngrams
sentence = """Thomas Jefferson began building Monticello at the age of 26."""
pattern = re.compile(r'([-\s.,;!?])+')
tokens = pattern.split(sentence)
tokens = [x for x in tokens if x and x not in '- \t\n.,;!?']
two_grams = list(ngrams(tokens, 2))
print([" ".join(x) for x in two_grams])
Out[1]:[‘Thomas Jefferson’, ‘Jefferson began’, ‘began building’, ‘building Monticello’, ‘Monticello at’, ‘at the’, ‘the age’, ‘age of’, ‘of 26’]
如果这些n-gram出现得非常少,它们就不会承载太多其他词的关联信息,而这些关联信息可以用于帮助识别文档的主题,这些主题可以将多篇文档或者多个文档类连接起来。
4.2 停用词
在任何一种语言中,停用词(stop word)指的是那些出现频率非常高的常见词,但是对短语的含义而言,这些词承载的实质性信息内容却少得多。一些常用的停用词如下:
- a, an
- the, this
- and, or
- of, on
大家可能会对词汇表大小导致所需的任何训练集的大小表示担心,训练集要足够大以避免对任何具体词或者词的组合造成过拟合。训练集的大小会决定对它的处理量,但是,从20000个词中剔除100个停用词不会显著加快上述处理过程,对2-gram词汇表而言,通过剔除停用词而获得的好处无足轻重。此外,如果不对使用停用词的2-gram频率进行检查就武断地剔除这些停用词的话,可能会丢失很多信息。
因此,如果我们有足够的内存和处理带宽来运行大规模词汇表下NLP流水线中的所有步骤,那么可能不必为在这里或那里忽略几个不重要的词而忧虑不已。如果担心大规模词汇表与小规模训练集之间发生过拟合的话,那么有比忽略停用词更好的方法来选择词汇表或者降维。
5.词表归一化
5.1 大小写转换
将单词或字符的大小写统一是一种减小词汇表规模的方法(case folding)。但是,单词的大写有时候也包含了一些特定的含义,例如"doctor"和’Doctor"往往具有不同的含义。如果命名实体识别对NLP流水线而言很重要的话,我么就希望能够识别出上面那些不同于其他单词的专有名词。然而,如果词条不进行大小写归一处理,那么词汇表的规模就大约是原来的两倍,需要消耗的内存和处理时间也大约是原来的两倍,这样可能会增加需要标注的训练数据的数量以保证机器学习流水线收敛到精确的通用解。
在python中,利用列表解析式能够很方便地对词条进行大小归一化处理:
tokens = ['House', 'Visitor', 'Center']
normalized_tokens = [x.lower() for x in tokens]
print(normalized_tokens)
Out[1]:[‘house’, ‘visitor’, ‘center’]
不幸的是这种做法处理会将我们希望的那些意义不大的句首大写字母归一化,也会将很多有意义的大小写形式给归一化掉,一个更好的大小写归一化方法是只将句首大写字母转成小写。
即使采用这种小心谨慎的大小写处理方法,也会遇到某些情况下专有名词出现在句首而导致的错误。为了避免可能的信息损失,很多NLP流水线根本不进行大小写归一化处理。在很多应用中,将词汇表规模减小一半带来的效率提升(存储和处理)会大于专有名词的信息损失。拥有真正完善手段的流水线会在选择性地归一化那些出现在句首但明显不是专有名词的词之前。
5.2 词干还原
另一种常用的词汇表归一化技术是消除词的复数形式、所有格的词尾甚至不同的动词形式等带来的意义上的微小差别。例如,housing和houses的公共词干是house。词干还原过程会去掉词的后缀,从而试图将具有相似意义的词归并到其公共词干。不一定要求词干必须是一个拼写正确的词,而只需要是一个能够代表词的多种可能拼写形式的词条或者标签。
词干还原的主要好处之一是,机器中的软件或语言模型所需记录其意义的词的个数得以压缩。它在限制信息或意义损失的同时,会尽可能减小词汇表的规模,这在机器学习中称为降维。它能够帮助泛化语言模型,使模型能够在属于同一词干的词上表现相同。
然而,词干还原可能会大幅度降低搜索引擎的正确率得分,这是因为在返回相关文档的同时可能返回了大量不相关文档,例如在搜索“developing houses in Portland”时,返回的页面或者文档可以同时包含"house",“houses”,甚至"housing",因为这些词都会还原成词干"house",同样,返回的页面除了包含"developing",还可以包含"developer"和"development",因为它们都可以还原成词干"develop"。
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
print(' '.join([stemmer.stem(w).strip("'") for w in "dish washer's washed dishes".split()]))
Out[1]:dish washer wash dish
5.3 词形归并
如果知道词义之间可以互相关联,那么可能就能将一些词关联起来,即使它们的拼写完全不一样。这种更粗放的将词归一化成语义词根即词元(lemma)的方式称为词形归并(lemmatization)。由于考虑了词义,相对于词干还原和大小写归一化,词形归并是一种潜在的更具有精确性的词的归一化方法。
设想一下如何使用词性信息从而比使用词干还原更好地识别词的"词根"?考虑词better,词干还原工具可能会去掉better词尾的er,从而得到bett或bet。但是这样做会将better和betting、bets和Bet’s混在一起,而一些更相近的词如betterment、best甚至good却被排除在外。
因此,在很多应用中词形归并比词干还原更有效。词干还原工具实际上仅仅用于大规模信息检索应用(关键词搜索)中。如果我们真的希望在信息检索流水线中通过词干还原工具进行降维和提高召回率,那么可能需要在使用词干还原工具之前先使用词形归并工具。由于词元本身是一个有效的英文词,词干还原工具作用于词形归并的输出会很奏效。这种技巧回避单独使用词干还原工具能够更好地降维和提高信息检索的召回率。
6. 情感
无论NLP流水线中使用的是单个词、n-gram、词干还是词元作为词条,每个词条都包含了一些信息。这些信息中的一个重要部分是词的情感,即一个词所唤起的总体感觉或感情。这种度量短语或者文本块的情感的任务称为情感分析(sentiment analysis),是NLP中的一个常见应用。
有两种情感分析的方法,分别是:
- 基于规则的算法,规则由人来攥写
- 基于机器学习的模型,模型是机器从数据中学习而得到
第一种情感分析的方法使用用户设计的规则(有时也称为启发式规则)来度量文本的情感。一个常用的基于规则的方法是在文本中寻找关键词,并将每个关键词映射到某部字典或者映射上的数值得分或权重。
第二种基于机器学习的方法利用一系列标注语句或者文档来训练机器学习模型以产生规则。需要大量标注好“正确”情感得分的文本数据。
6.1 VADER:一个基于规则的情感分析器
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
sa = SentimentIntensityAnalyzer()
print([(tok, score) for tok,score in sa.lexicon.items()])
Out[1]:[(‘$:’, -1.5), (‘%)’, -0.4), (‘%-)’, -1.5), (‘&-:’, -0.4), (‘&:’, -0.7), (“( ‘}{’ )”, 1.6), (‘(%’, -0.9), (“('-:”, 2.2)…]
这里的分词其最擅长处理标点符号和表情符号,这样VADER才能更好地工作。
print(sa.polarity_scores(text="Python is very readable and it's great for NLP."))
print(sa.polarity_scores(text="Python is not a bad choice for most applications."))
Out[1]:{‘neg’: 0.0, ‘neu’: 0.661, ‘pos’: 0.339, ‘compound’: 0.6249}
Out[2]:{‘neg’: 0.0, ‘neu’: 0.737, ‘pos’: 0.263, ‘compound’: 0.431}
VADER算法用3个不同的分数(正向、负向和中立)来表达情感极性的强度,然后将它们组合在一起得到一个复合的情感倾向性得分。
corpus = ["Absolutely perfect! Love it! :-) :-) :-)","Horrible!Completely useless. :(","It was OK.Some good and some bad things."]
for doc in corpus:
scores = sa.polarity_scores(doc)
print('{:+}:{}'.format(scores['compound'],doc))

VADER的唯一不足在于,它只关注其词库中的7500个词条,而非文档中的所有词。
6.2朴素贝叶斯
from nlpia.data.loaders import get_data
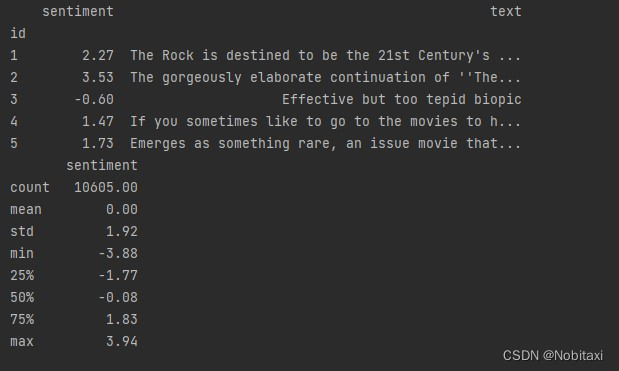
movies = get_data('hutto_movies')
print(movies.head().round(2))
print(movies.describe().round(2))
import pandas as pd
pd.set_option('display.width', 75)
from nltk.tokenize import casual_tokenize # 相对于TreebankWordTokenizer分词器或者其它分词器,NLTK的casual_tokenize可以更好地处理表情符号、不寻常的标点符号以及行业术语
bags_of_words = []
from collections import Counter # python内置的Counter的输入是一系列对象,然后对这些对象进行计数,并返回一部字典,其中键是对象本身(这里是词条),值是这些对象计数后得到的整数值
for text in movies.text:
bags_of_words.append(Counter(casual_tokenize(text)))
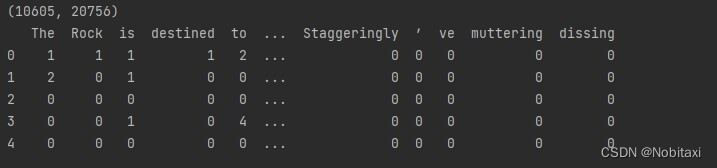
df_bows = pd.DataFrame.from_records(bags_of_words) # DataFrame构造器from——records()的输入是一个字典的序列,它为所有键构建列,值被加入合适的列对应的表格中,而缺失值用NaN进行填充
df_bows = df_bows.fillna(0).astype(int) # Numpy和Pandas只能用浮点对象来表示NaN,因此一旦将所有NaN填充为0,可以将DataFrame转换为整数,这样在内存存储和显示上可以紧凑的多
print(df_bows.shape)
print(df_bows.head())
现在我们拥有了朴素贝叶斯模型所需要的所有数据,利用这些数据可以从自然语言文本中寻找那些预测情感的关键词:
from sklearn.naive_bayes import MultinomialNB
nb = MultinomialNB()
nb = nb.fit(df_bows,movies.sentiment > 0) # 朴素贝叶斯是分类器,因此需要将输出的变量(代表情感的浮点数)转换成离散的标签(整数、字符串或者布尔值)
movies['predicted_sentiment'] = nb.predict(df_bows).astype(int) * 8 - 4# 将二值的分类结果变量(0或1)转换到-4到4之间,从而能够和标准情感得分进行比较。利用np.predict_proba可以得到一个连续值
movies['error'] = (movies.predicted_sentiment - movies.sentiment).abs()
print(round(movies.error.mean(), 1))
movies['sentiment_ispositive'] = (movies.sentiment > 0).astype(int)
movies['predicted_ispositive'] = (movies.predicted_sentiment > 0).astype(int)
print(movies['''sentiment predicted_sentiment sentiment_ispositive predicted_ispositive'''.split()].head(5))
print((movies.predicted_ispositive == movies.sentiment_ispositive).sum() / len(movies))

平均预测错误绝对值(也称为MAE)是2.4
点赞评级的正确率是93%
另外,朴素贝叶斯模型没有像VADER一样处理否定词。我们必须要将n-gram放到分词器中才能够将否定词(如“not”和“never”)与其修饰的可能要用的正向词关联起来。

















 9413
9413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









