






目录
大模型部署背景
模型部署
- 定义
- 在软件工程中,部署通常指的是将开发完毕的软件投入使用的过程
- 在人工智能领域,模型部署是实现深度学习算法落地应用的关键步骤。简单来说,模型部署就是将训练好的深度学习模型在特定环境中运行的过程
- 场景
- 服务器端:CPU部署、单GPU/TPU/NPU部署,多卡/集群部署
- 移动端/边缘端:移动机器人,手机
大模型部署面临的挑战
计算量巨大
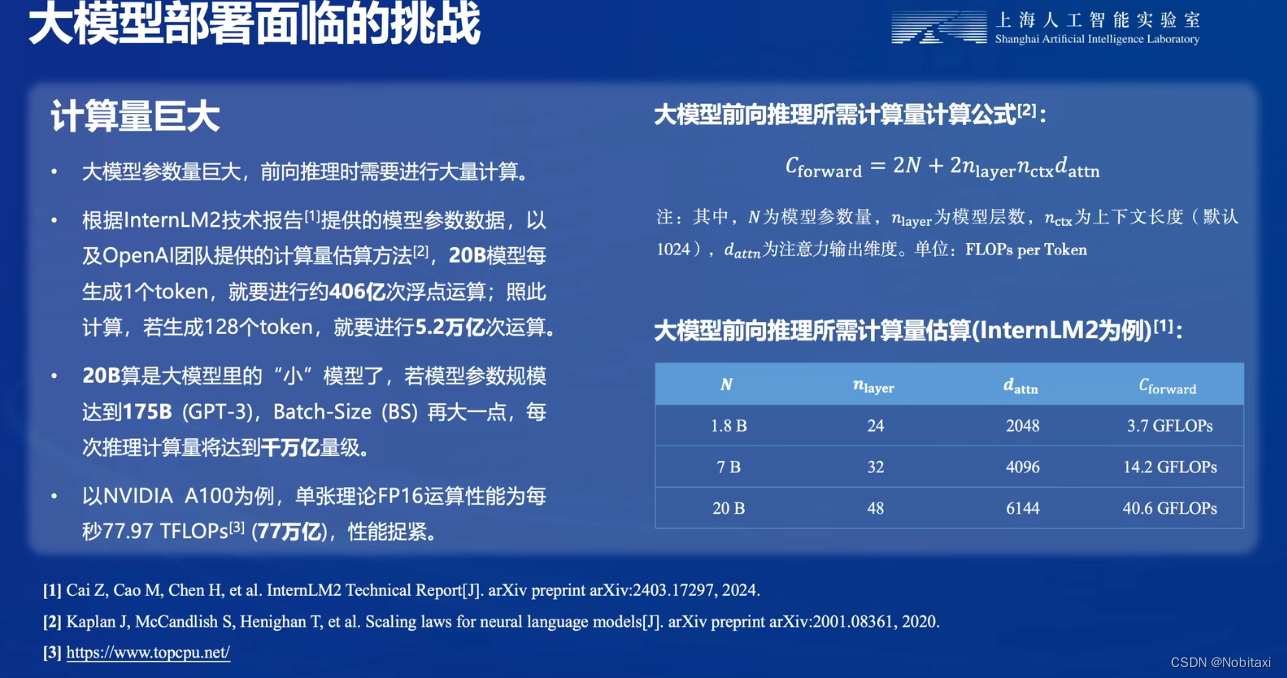
内存开销巨大
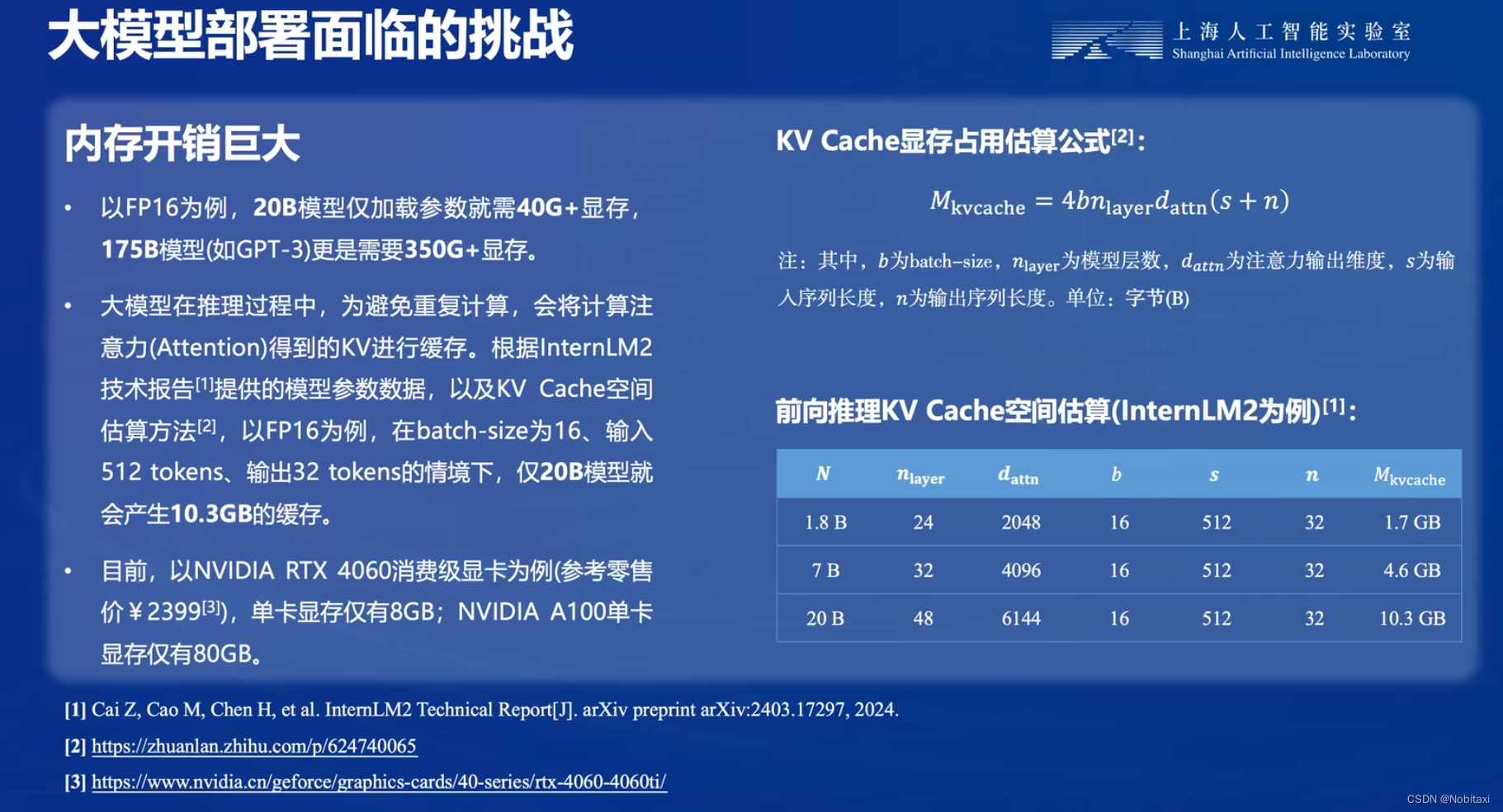
访存瓶颈&动态请求
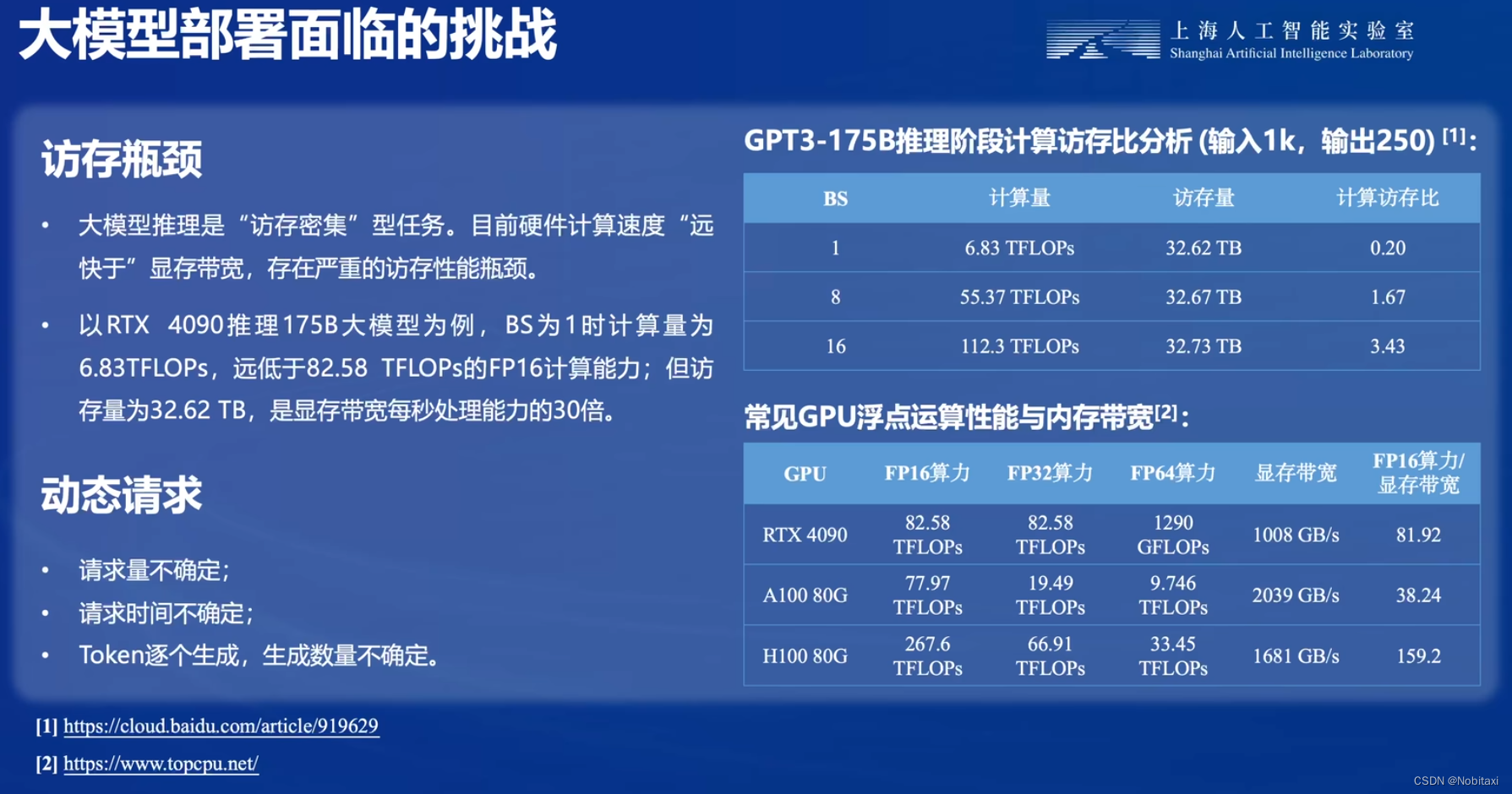 # 大模型部署方法
# 大模型部署方法
模型减枝
剪枝指的是移除模型中不必要或多余的组件,比如参数,以使模型更加高效。通过对模型中贡献有限的冗余参数进行减枝,在保证性能最低下降的同时,可以减小存储需求、提高计算效率。
- 非结构化减枝(SparseGPT、LoRAPrune、Wanda)
指移除个别参数,而不考虑整体网络结构。这种方法通过将低于阈值的参数置零的方式对个别权重或神经元进行处理 - 结构化减枝(LLM-Pruner)
根据预定义规则移除连接或分层结构,同时保持整体网络结构。这种方法一次性地针对整组权重,优势在于降低模型复杂性和内存使用,同时保持整体的LLM结构完整
知识蒸馏
知识蒸馏是一种经典的模型压缩方法,核心思想是通过引导轻量化的学生模型“模仿”性能更好、结构更复杂的教师模型,在不改变学生模型结构的情况下提高其性能。
- 上下文学习(ICL):ICL distillation
- 思维链(CoT):MT-COT、Fine-tune-CoT
- 指令跟随(IF):LaMini-LM
量化

LMDeploy简介
LMDeploy由MMDeploy和MMRazor团队联合开发,是涵盖了LLM任务的全套轻量化、部署和服务解决方案。核心功能包括高效推理、可靠量化、便捷服务和有状态推理
- 高效的推理:LMDeploy开发了Continuous Batch,Blocked K/V Cache,动态拆分和融合,张量并行,高效的计算Kernel等重要特性。IntenLM2推理性能是vLLM的1.8倍
- 可靠的量化:LMDeploy支持权重量化和k/v量化。4bit模型推理效率是FP16下的2.4倍。量化模型的可靠性已通过OpenCompass评测得到充分验证
- 便捷的服务:通过请求分发服务,LMDeploy支持多模型在多机、多卡上的推理服务
- 有状态推理:通过缓存多轮对话过程中Attention的k/v,记住对话历史,从而避免重复处理历史会话。显著提升长文本多轮对话场景中的效率
LMDeploy核心功能

作业
环境部署
conda create -n lmdeploy -y python=3.10
conda activate lmdeploy
pip install lmdeploy[all]==0.3.0
LMDeploy模型对话
下载模型
由OpenXLab平台下载模型
OpenXLab平台支持通过Git协议下载模型。首先安装git-lfs组件。
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | bash
apt update
apt install git-lfs
git lfs install --system
安装好git-lfs组件后,由OpenXLab平台下载InternLM2-Chat-1.8B模型:
git clone https://code.openxlab.org.cn/OpenLMLab/internlm2-chat-1.8b.git
使用Transformer库运行模型
在终端中输入如下指令,新建pipeline_transformer.py
touch /root/pipeline_transformer.py
内容如下:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("/root/internlm2-chat-1_8b", trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and cause OOM Error.
model = AutoModelForCausalLM.from_pretrained("/root/internlm2-chat-1_8b", torch_dtype=torch.float16, trust_remote_code=True).cuda()
model = model.eval()
inp = "hello"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=[])
print("[OUTPUT]", response)
inp = "please provide three suggestions about time management"
print("[INPUT]", inp)
response, history = model.chat(tokenizer, inp, history=history)
print("[OUTPUT]", response)
运行python代码
python /root/pipeline_transformer.py

使用LMDeploy与模型对话
使用LMDeploy与模型进行对话的通用命令格式为:
# lmdeploy chat [HF格式模型路径/TurboMind格式模型路径]
lmdeploy chat /root/internlm2-chat-1_8b
注意:TurboMind推理引擎仅支持推理TurboMind格式的模型。因此,TurboMind在推理HF格式的模型时,会首先自动将HF格式模型转换为TurboMind格式的模型。该过程在新版本的LMDeploy中是自动进行的,无需用户操作

很明显能够感觉到模型推理速度加快了很多
LMDeploy模型量化(lite)
正式介绍 LMDeploy 量化方案前,需要先介绍两个概念:
- 计算密集(compute-bound): 指推理过程中,绝大部分时间消耗在数值计算上;针对计算密集型场景,可以通过使用更快的硬件计算单元来提升计算速度。
- 访存密集(memory-bound): 指推理过程中,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般通过减少访存次数、提高计算访存比或降低访存量来优化。
常见的 LLM 模型由于 Decoder Only 架构的特性,实际推理时大多数的时间都消耗在了逐 Token 生成阶段(Decoding 阶段),是典型的访存密集型场景。
那么,如何优化 LLM 模型推理中的访存密集问题呢? 我们可以使用KV8量化和W4A16量化。KV8量化是指将逐 Token(Decoding)生成过程中的上下文 K 和 V 中间结果进行 INT8 量化(计算时再反量化),以降低生成过程中的显存占用。W4A16 量化,将 FP16 的模型权重量化为 INT4,Kernel 计算时,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本。Weight Only 是指仅量化权重,数值计算依然采用 FP16(需要将 INT4 权重反量化)。
设置最大KV Cache缓存大小
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。理想情况下,KV Cache全部存储于显存,以加快访存速度。当显存空间不足时,也可以将KV Cache放在内存,通过缓存管理器控制将当前需要使用的数据放入显存。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置–cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。
下面通过几个例子,来看一下调整--cache-max-entry-count参数的效果。首先保持不加该参数(默认0.8),运行1.8B模型。
lmdeploy chat /root/internlm2-chat-1_8b

此时显存占用为7816MB,我么改变--cache-max-entry-count参数,设为0.5
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.5

可以看到此时显存占用为6600MB
下面来一波“极限”,把--cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存。
lmdeploy chat /root/internlm2-chat-1_8b --cache-max-entry-count 0.01

可以看到,此时显存占用仅为4560MB,代价是会降低模型推理速度
使用W4A16量化
LMDeploy使用AWQ算法,实现模型4bit权重量化。推理引擎TurboMind提供了非常高效的4bit推理cuda kernel,性能是FP16的2.4倍以上。它支持以下NVIDIA显卡:
- 图灵架构(sm75):20系列、T4
- 安培架构(sm80,sm86):30系列、A10、A16、A30、A100
- Ada Lovelace架构(sm90):40 系列
运行前,首先安装一个依赖库。
pip install einops==0.7.0
仅需执行一条命令,就可以完成模型量化工作。
lmdeploy lite auto_awq \
/root/internlm2-chat-1_8b \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 1024 \
--w-bits 4 \
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit
运行时间较长,请耐心等待。量化工作结束后,新的HF模型被保存到internlm2-chat-1_8b-4bit目录。下面使用Chat功能运行W4A16量化后的模型。
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq

默认参数下的显存占用为7396MB
为了更加明显体会到W4A16的作用,我们将KV Cache比例再次调为0.01,查看显存占用情况。
lmdeploy chat /root/internlm2-chat-1_8b-4bit --model-format awq --cache-max-entry-count 0.01

显存占用变为2350MB
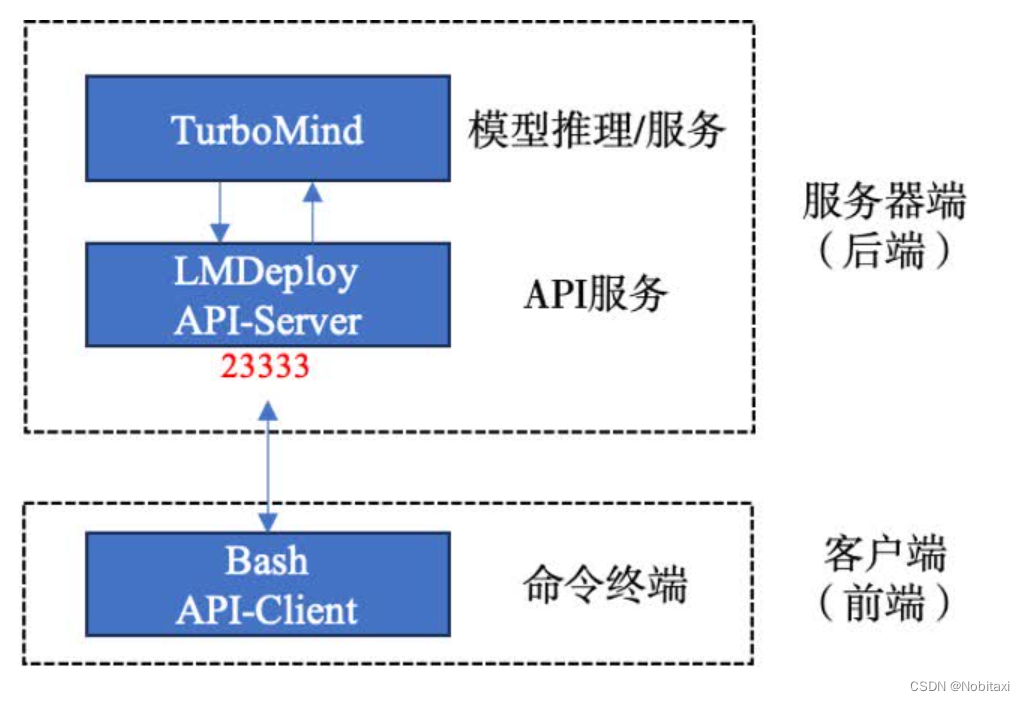
LMDeploy服务(serve)
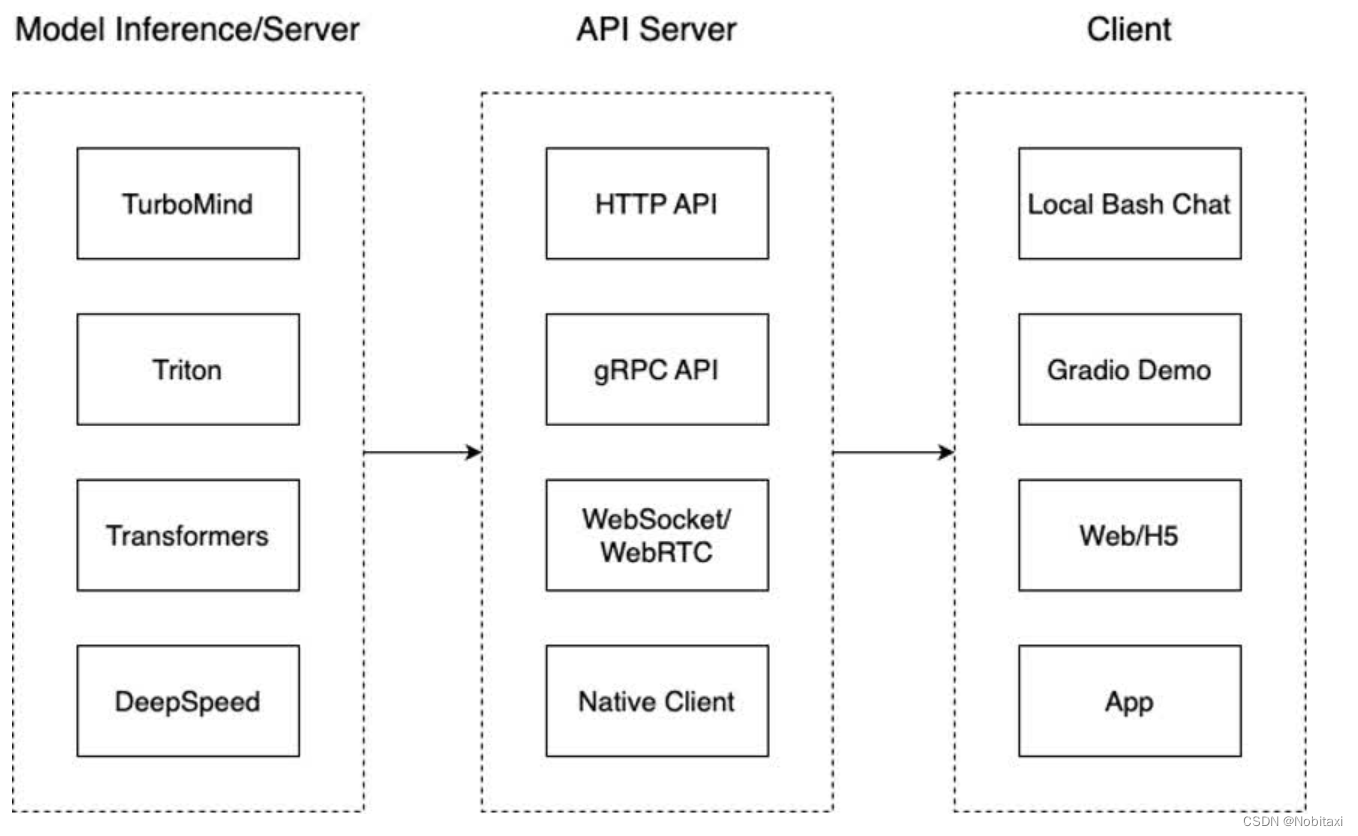
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。中间协议层,把后端推理/服务通过HTTP,gRPC或其他形式的接口,供前端调用。
- Client。可以理解为前端,与用户交互的地方。通过通过网页端/命令行去调用API接口,获取模型推理/服务。
启动API服务器
通过以下命令启动API服务器,推理internlm2-chat-1_8b模型:
lmdeploy serve api_server \
/root/internlm2-chat-1_8b \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)
通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务
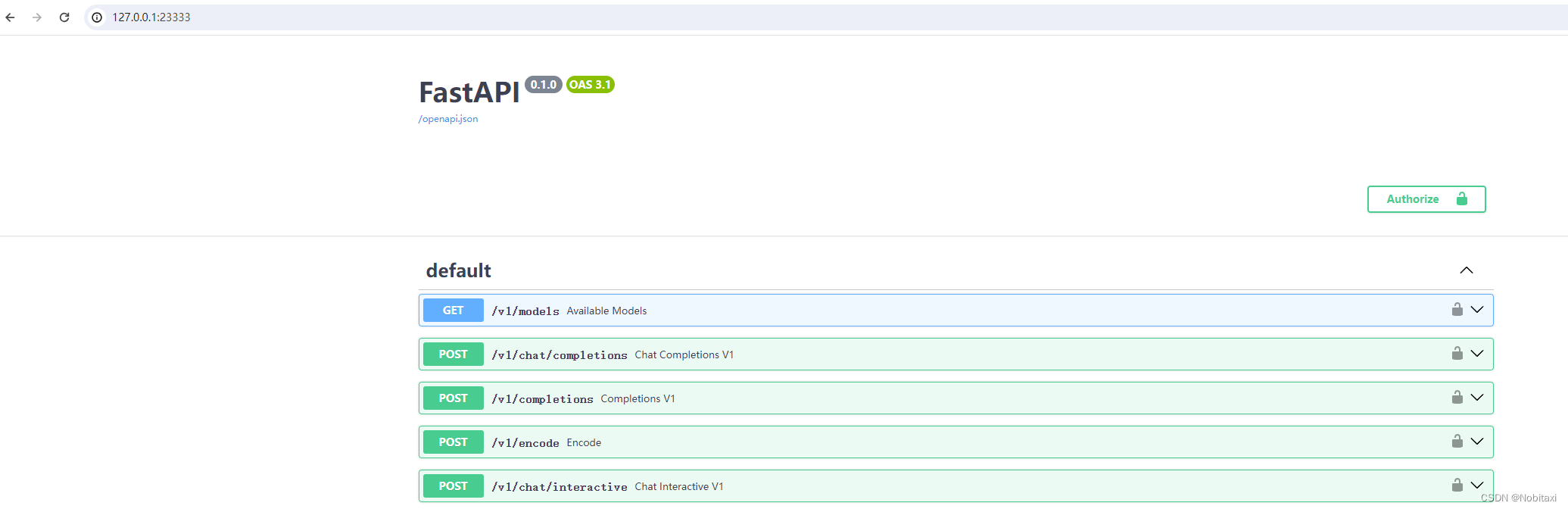
命令行客户端连接API服务器
运行命令行客户端:
lmdeploy serve api_client http://localhost:23333

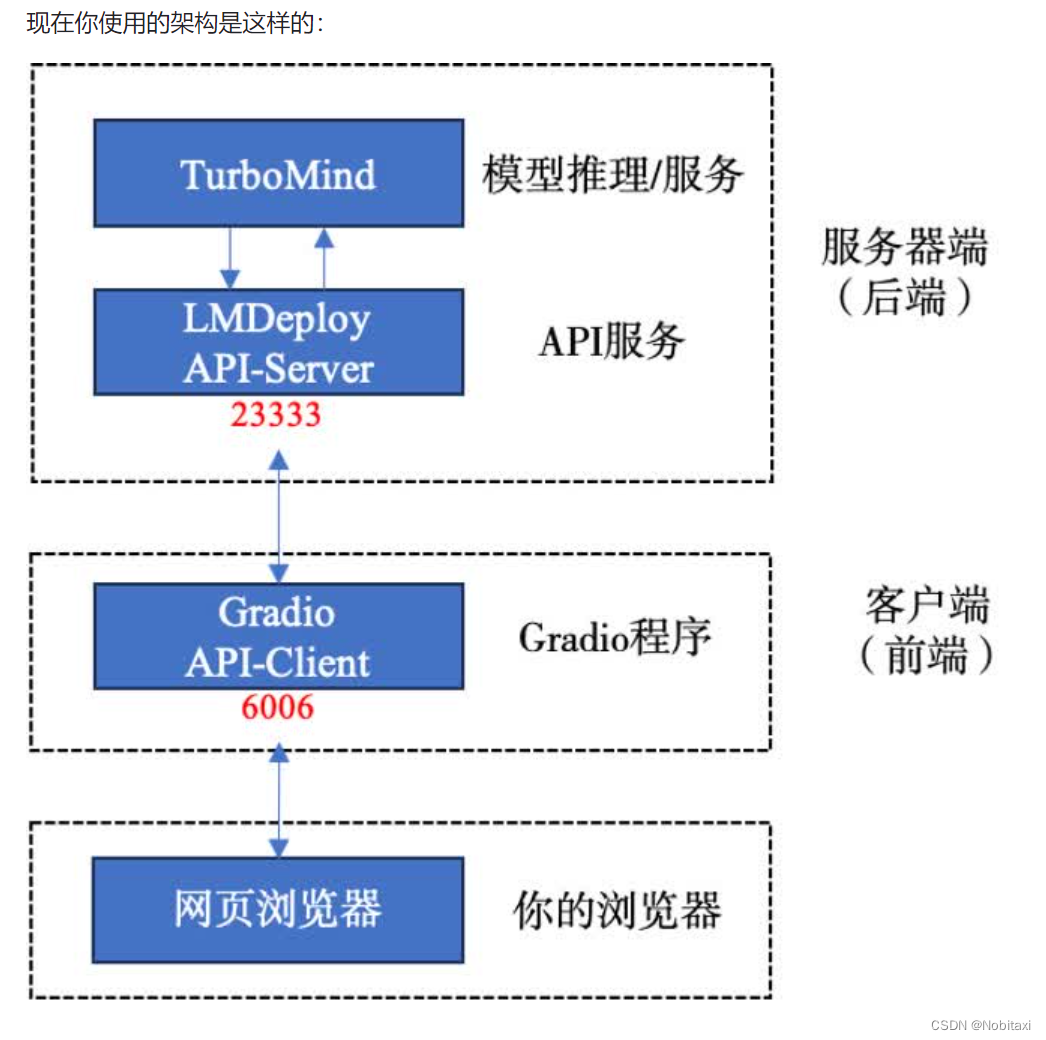
现在你使用的架构是这样的:
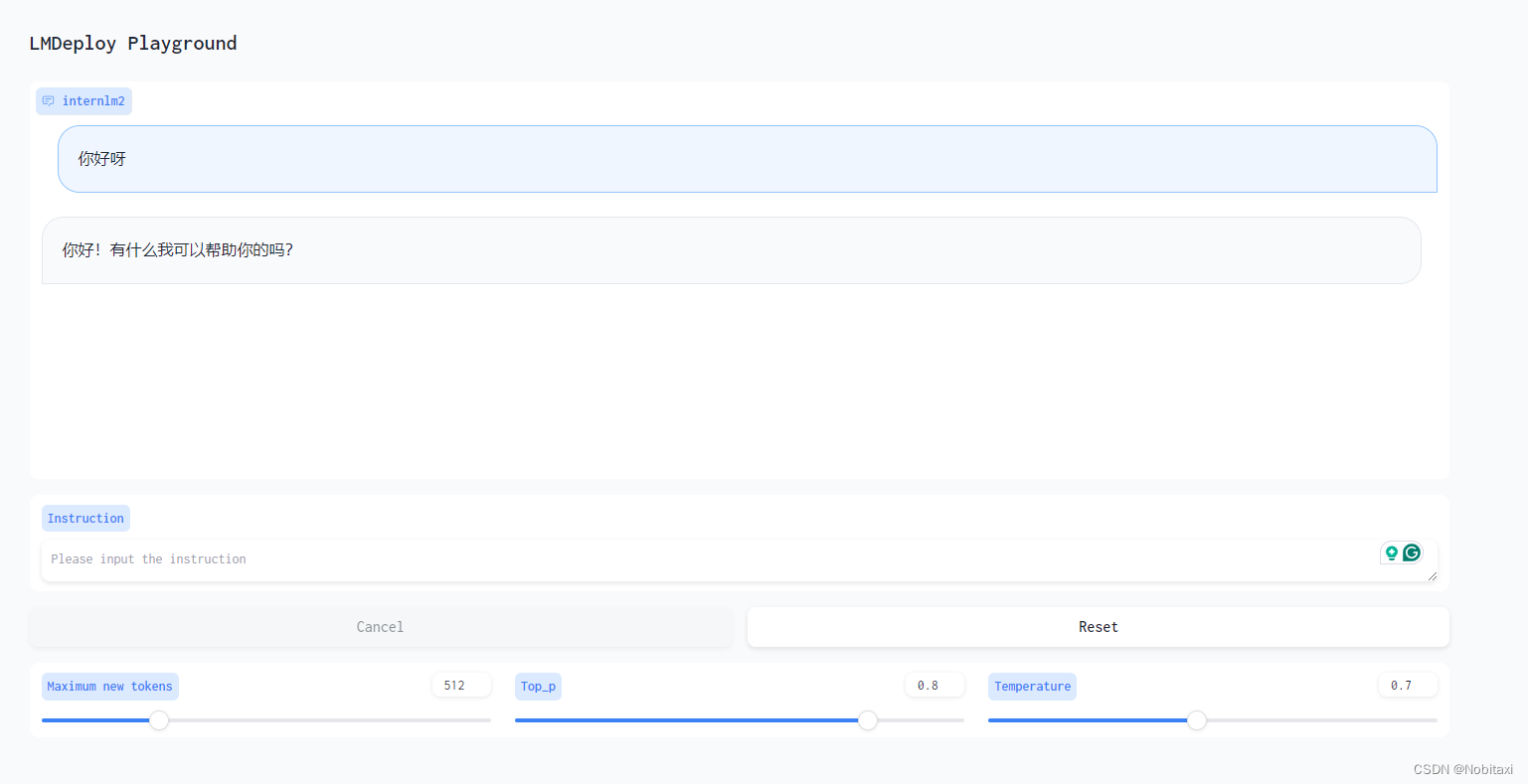
网页客户端连接API服务器
使用Gradio作为前端,启动网页客户端
lmdeploy serve gradio http://localhost:23333 \
--server-name 0.0.0.0 \
--server-port 6006
Python代码集成
在开发项目时,有时我们需要将大模型推理集成到Python代码里面
Python代码集成运行1.8B模型
新建Python源代码文件pipeline.py
touch /root/pipeline.py
打开pipeline.py,填入以下内容。
from lmdeploy import pipeline
pipe = pipeline('/root/internlm2-chat-1_8b')
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
保存后运行代码文件:
python /root/pipeline.py

向TurboMind后端传递参数
在Python代码中,可以通过创建TurbomindEngineConfig,向lmdeploy传递参数。
以设置KV Cache占用比例为例,新建python文件pipeline_kv.py。
touch /root/pipeline_kv.py
打开pipeline_kv.py,填入如下内容:
from lmdeploy import pipeline, TurbomindEngineConfig
# 调低 k/v cache内存占比调整为总显存的 20%
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.2)
pipe = pipeline('/root/internlm2-chat-1_8b',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
保存后运行python代码:
python /root/pipeline_kv.py
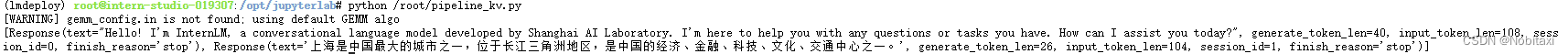














 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









