






贝叶斯分类
贝叶斯分类是一类分类算法的总称,以贝叶斯定理为基础。其中我们较为熟悉的朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
贝叶斯网络
贝叶斯网络是一种概念图模型。概率图模型就是用图论和概率论的知识,利用图来表示变量之间概率依赖关系。(变量的联合概率分布)
其中,
图的节点对应随机变量
边对应随机变量的相关关系(依赖)。
有向边表示单向的依赖,无向边表示变量相互依赖。贝叶斯网络的网络结构是一个有向无环图。朴素贝叶斯就是一个只有节点,没有边的特殊的图。
概率图模型包括除了贝叶斯之外,还有最大熵模型等等其他的模型。
朴素贝叶斯算法中的原理简单理解
机器学习中处处可见概率论、微积分、线性代数的知识。在学习贝叶斯的过程中需要大量概率论的知识,结合概率论知识可以更好的理解算法原理。
原理简单介绍
先要掌握几个基本概念:随机变量,联合概率,条件概率,独立性,贝叶斯公式。
随机变量:样本空间在实数集R上的映射。常用大写字母X,Y表示。
联合概率 P(AB)表示A和B都发生的概率。
条件概率 P(B|A)在A发生的概率下,B再发生的概率。其中P(A)>0.
乘法公式: P(AB)=P(B|A)*P(A)
第一步:先让A发生,第二步:A发生的情况下,再让B发生。合起来就是A,B都发生。
全概率公式: P(B)=
∑
i
=
1
n
P
(
B
∣
A
i
)
∗
P
(
A
i
)
\displaystyle \sum_{i=1}^n P(B|A_i)*P(A_i)
i=1∑nP(B∣Ai)∗P(Ai)
将样本空间划分为一个个独立的小块儿,反映到集合上就是A={
A
1
A_1
A1U
A
2
A_2
A2U
A
3
A_3
A3U…} ,其中
A
i
A_i
Ai可以看作某个特征A的某个取值,B可以看作标签。
贝叶斯公式:
P
(
A
i
∣
B
)
=
P
(
A
i
∣
B
)
P
(
B
)
=
P
(
B
∣
A
i
)
∗
P
(
A
i
)
∑
i
=
1
n
P
(
B
∣
A
i
)
P
(
A
i
)
\displaystyle {P(A_i|B)}={\frac{P(A_i|B)}{P(B)} }= { \frac{P(B|A_i)*P(A_i)}{\sum_{i=1}^n P(B|A_i)P(A_i)}}
P(Ai∣B)=P(B)P(Ai∣B)=∑i=1nP(B∣Ai)P(Ai)P(B∣Ai)∗P(Ai)
全概率公式和贝叶斯公式是一种关系的反转。全概率可以看作 已知某个特征 A i A_i Ai 求标签为B的概率 。贝叶斯可以看作 :已知标签为B的前提下 求具有某个特征 A i A_i Ai的概率(即影响将结果划为某一类别的因素)
贝叶斯公式是一切贝叶斯算法的理论依据。当把B理解为标签Y, A i A_i Ai理解为特征X对应的取值时,P( A i A_i Ai|B)可以看作分类为Y(Y取一个特定的值),特征为 X i X_i Xi的概率——这称为先验概率(已经知道分类的标签,求对应特征的概率。反之,为再特征 X i X_i Xi下标签为Y(Y=0,1,2,…)的概率,即后验概率。
朴素贝叶斯方法有一个重要假设:——各特征(属性)之间是有条件独立*。
即两者的取值完全无影响,这样可以在计算概率的时候简化了很多计算,这也是为什么叫做朴素的原因。但实际应用中,很多时候各个特征之间不是独立的。
机器学习中的朴素贝叶斯
分类算法总是先从训练集中学习,获取某种信息来建立模型,然后用测试集进行预测。朴素贝叶斯是从一张有标签的表中,计算各种概率,再直接放到测试集上,没有建模求参的过程。
朴素贝叶斯是真正的概率模型,而其他一些分类算法,如决策树,随机森林,逻辑回归,都是通过取平均或少数服从多数的比例,或者归一化和sigmod函数将最后的结果压缩到区间0-1之间从而获得分类为Y(Y取特定值)的一种概率,不是真正意义上的概率。
现实中的大多数标签还是连续型变量,要处理连续型变量的概率,就不是单纯的数样本个数的占比的问 题了。求解连续型变量的概率,需要引入各种概率论中的数字分布,使用各种分布下的概率密度曲线来估计一个概 率。其中涉及的数学原理极其复杂的,必须要熟悉概率论和微积分。
利用sklearn实现一个简单的朴素贝叶斯算法
- sklearn.naive_bayes
- 高斯朴素贝叶斯 naive_bayes.GaussianNB
- 假设P( X i X_i Xi|Y)服从高斯分布(即正态分布)
- 多项式朴素贝叶斯 naive_bayes.MultinomialNB
- 假设P( X i X_i Xi|Y)服从多项式分布
- 伯努利贝叶斯 naive_bayes.BernoulliNB
- 假设P( X i X_i Xi|Y)服从伯努利分布。(通俗的讲,假设抛一枚一硬币为正面朝上的概率为a,则反面朝上的概率为1-a,这样的概率分布就是服从伯努利分布)
- 高斯朴素贝叶斯 naive_bayes.GaussianNB
利用高斯贝叶斯实例化
我这里用的开发环境是Jupyter Notebook
//导入相关库和数据
from sklearn.naive_bayes import GaussianNB
from sklearn datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import brier_score_loss #导入布里尔分数
data = load_digits()
X, Y = data.data, data.target
Xtrain, Xtest, Ytain, Ytest = train_test_split(X, Y, test_size=0.3,random_state=90)
gnb = GaussianNB()
gnb = gnb.fit(Xtrain,Ytrain)
score = gnb.score(Xtest,Ytest) #查看在测试集上的预测准确率
pre = gnb.predict(Xtest) #查看预测结果
pre.shape
pre_pro = gnb.predict_prob(Xtest) #查看预测为Y的概率
brier_score_loss(Ytest,prob[:,0],pro_label) #查看第一个类别下的布里尔分数
#布里尔分数用来衡量概率预测的准确程度,表示的是概率预测相对于测试样本的均方误差,所以分数越高,模型预测效果越差
半朴素贝叶斯
前面我们说到了朴素贝叶斯的前提假设是:各特征之间相互独立,而在实际模型中我们并不满足这样的假设,因为很多样本之间的各个特征有各种关联关系,并不独立。半朴素贝叶斯放宽了这个假设,允许一些特征之间拥有依赖关系。
常用的半朴素贝叶斯模型
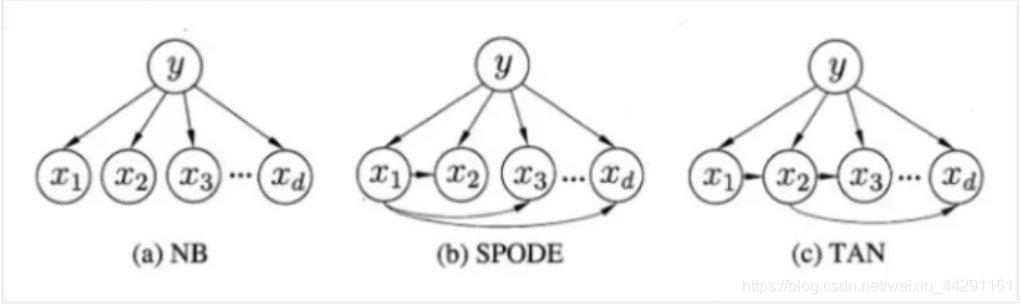
从上面的图中 我们可以看出,第一种是朴素贝叶斯分类中各特征之间的依赖关系——各属性之间是相互独立的。
2. SPODE
假设各属性都依赖一个“超级属性”,
x
d
x_d
xd就是超父属性。
3. AODE
先将所有属性都作为超父属性,建立SPODE模型,然后从中选出较好的属性集成作为最终的模型。(感觉和集成算法有点像。。。)
4. TAN
假设每个属性只依赖一个属性,但并不是统一的超父。它是将每个属性看成一个** 无向完全图**,每条边的权重就是两条边的相关性(对应属性的相关性就出来了)。这里涉及了概率图模型。
具体的计算公式的推导过程很复杂 需要花时间去了解。
在机器学习的过程中会发现很多算法或者概念需要大量的数学知识作为基础,特别是概率论和数理统计方面的许多知识,许多算法公式的推导需要掌握一些概念如:概率公式,贝叶斯,协方差,期望,极大似然, 比如PCA降维中就要了解协方差,EM算法就是最大期望算法,通过极大似然估计参数等等。因此要打好数理基础,才能将算法的原理理解的更为透彻。














 2044
2044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









