







- 关于网络深度
根据经验,网络层数的增加有利于模型训练的准确率 像上一次我们提到的VGG网络 就是通过增加网络深度来提取更丰富的特征越丰富,从而提高模型的训练精度和泛化能力。但是,当网络层数达到一定时不能单纯通过增加深度来优化网络,简单地增加深度,会导致梯度弥散或梯度爆炸。(反向传播时无法把有效地把梯度更新到前面的网络层,导致前面的层参数无法更新,使浅层次的参数得不到很好的训练,模型训练起来也更加困难)。
反向传播时,如果输入的模值都大于1,那么经过很多层回传,梯度将不可避免地呈几何倍数增长,经过多层,梯度就会变得很大,直到Nan。这就是梯度爆炸现象。反过来,如果输入的模小于1,那么梯度也将呈几何倍数下降,变得很小,直到0。这就是梯度弥散现象。通常梯度更倾向于消失而不是爆炸。
所以在Resnet出现之前,CNN网络都不超过二十几层。
解决这个问题 我们通常用正则化层(Batch Normalization)控制每层输入的模值,这样的话可以训练几十层的网络。
-
网络退化问题
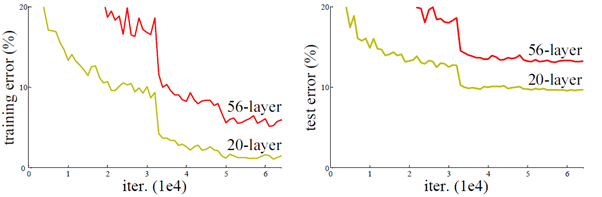
上图中,56-layer层的网络比20-layer的网络在训练集和测试集上的表现都要差(所以这里不是过拟合问题),就说明了不能简单的增加网络深度。当网络深度达到一定程度时准确率会出现饱和甚至退化的问题。为什么会这样?可以这样理解:网络深度越深,它的解空间就越复杂,利用随机梯度下降算法往往得到的是局部最优解,不是全局最优解。所以造成了层数增加准确率反而下降了。 -
残差学习
由于非线性激活函数Relu的存在,从输入到输出的过程都信息都会有损失,这种“非线性”使得神经网络模型越走越远,原来的特征也随着层层向前传播难以得到完整保留。所以,我们也很难从输出反推回完整的输入。
而恒等映射(identify mapping就是让神经网络什么也不做,保留原来的输入的特征。如果深层网络内部结构中加入恒等映射,(相当于给每一个导数就加上了一个恒等项1,此时就算原来的导数很小,这时候误差仍然能够有效的反向传播)这样即使经过多层的堆叠,模型也可以保持原来的特征,不会因为堆叠产生网络退化了。
所以这里加入一个恒等映射作为网络结构的一部分(分枝),就转化成H(X)=F(X)+X
得到残差学习函数F(X)=H(X)-X
残差网络中r残差块Residual block时基本单元,下面就是一个残差块的基本结构。

通过在每一个残差块resnet block中加上一个捷径shortcut connection,如果F(X)=0,就是上面说的恒等映射,使其保留原来的特征,在后传过程中更好地把梯度传到更浅的层次中。这样就可以解决上面的问题。
假设上一层输入为x,经过一个block的多层结构后 输出为F(x),左右两条路线输出的激活值相加得到最终的输出为h(x),即h(x) = F(x) + x,h(x)再作为下一个block的输入。
因为加了这条捷径,深层的梯度能去到上一层,使得浅层的网络层参数等到有效的训练。
所以输入输出的函数就变成
y
=
F
(
x
,
W
i
)
+
x
y=F(x,{W_i})+x
y=F(x,Wi)+x
Resnet的网络结构如下

注意!在一开始时 并没有直接上residual block,而是使用一个7x7的卷积和stride为2 的池化。77这样的大卷积实际上是用来直接对输入图片降采样(early downsampling), (像7x7这样的大卷积核一般只出现在input layer)这样可以尽可能保留图像里更多的features,不需要增加channels数。(因为多channels的非线性激活层代价很大)所以在input layer用大的卷积核换多channels是划算的。
resnet在接入residual block前输入为56x56的layer, channels数才64。
上面的Conv2 - 5 都是一个residualblock,每一个block包含多层卷积和激活。
下面是两种不同的residual block(左边的适用于18 34-layer的网络结构)
我们选50-layer的第一个residual结构如下图:

注意!这里有实线 虚线两种不同的shortcut,
在Block前后的维度不一致时要走虚线分枝。维度不一致包括:空间维度和深度
空间不一致时,给X加一些卷积池化操作。
深度不一致时可以加一个11的卷积层进行升维,或者直接简单粗暴地补零。
如果主分支和shortcut的输出不一致时 要对shortcut进行调整
下面试着写一下这个网络结构
import torch.nn as nn
# 18 layer和34 layer用该残差块类
class BasicBlock(nn.Module):
expansion=1 #对输出通道的放大倍数, 在bottleneck会用上 这里用1
def __init__(self, in_channels, out_channels, stride=1, downsample=None): #downsampe是捷径分枝上的下采样函数,
# 如果主分支和捷径分枝维度不一致就要用这个函数调整维度y=F(xi,Wi)+x 就会变成y=F(xi,Wi)+Wsx
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False) #第一层卷积的步长设为1 BN不需要偏置
self.BN1 = nn.BatchNorm2d(out_channels) #上一层输出的维度做BN
self.relu = nn.ReLU(inplace=True) ##inplace表示对原数据修改, 而非产生新数据, 节省内存
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, 1, False)
self.BN2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
# 如果没有输入下采样函数 捷径上的输出就等于X 恒等映射 走实线,否则走虚线分枝
identity = x if self.downsample is None else self.downsample(x) #shortcut
out = self.conv1(x)
out = self.BN1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.BN2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4 # 每一个stage中最后一层1x1输出的维度是第1(1x1,64), 2(3x3,64)层卷积的4倍, 放大倍率为4
# 主结构变成 1x1, 3x3, 1x1
def __init__(self, in_channels, out_channels, stride=1, downsample=None): # downsampe是捷径分枝上的下采样函数,
# 如果主分支和捷径分枝维度不一致就要用这个函数调整维度y=F(xi,Wi)+x 就会变成y=F(xi,Wi)+Wsx
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False) # 第一层卷积的步长设为1 BN不需要偏置
self.BN1 = nn.BatchNorm2d(out_channels) # 上一层输出的维度做BN
self.relu = nn.ReLU(inplace=True) ##inplace表示对原数据修改, 而非产生新数据, 节省内存
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, 1, False)
self.BN2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels*self.expansion, 1, 1, 1, False) #out_channels放大4倍
self.BN3 = nn.BatchNorm2d(out_channels*self.expansion)
self.downsample = downsample
def forward(self, x):
# 如果没有输入下采样函数 捷径上的输出就等于X 恒等映射 走实线,否则走虚线分枝
identity = x if self.downsample is None else self.downsample(x) # shortcut
out = self.conv1(x)
out = self.BN1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.BN2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.BN3(out)
out += identity
out = self.relu(out)
return out
# 定义ResNet的网络主体
class Resnet(nn.Module):
# nn.Moudle是pytorch中网络的ji'lei重写init和forward方法
def __init__(self, block, block_num, num_classes=5):
super(Resnet, self).__init__()
self.in_channels = 64 # 输入都是64.第一个block的输入通道数一定是64, 因为前面先经过(64, 7, 7)的大卷积
#先使用一个7x7的卷积来直接对输入图片降采样,不要一上来就上block
self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=7, stride=2, padding=3,bias=False) #第一次卷积 让尺寸减半
self.BN1 = nn.BatchNorm2d(self.in_channels)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.relu = nn.ReLU(inplace=True)
# 开始构造每一大块stage
# conv2_x
self.layer1 = self._make_layer(block, 64, block_num[0], stride=1) #第一个只需要调整深度,不需要调整大小,所以stride=1
# conv3_x
self.layer2 = self._make_layer(block, 128, block_num[1], stride=2) #步长为2 图像输出大小减半
# conv4_x
self.layer3 = self._make_layer(block, 256, block_num[2], stride=2) #步长为2 图像输出大小减半
# conv5_x
self.layer4 = self._make_layer(block, 512, block_num[3], stride=2) #步长为2 图像输出大小减半
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) #global average pooling 最后输出为1*1
self.fc = nn.Linear(512*block.expansion, num_classes) #全连接层 输出为分类数
for m in self.modules():
if isinstance(m, nn.Conv2d): # 如果是卷积层,都对weight和bias进行kaiming初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d): # 如果是BN层,都权重初始化为1, bias=0
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 将每一大块stage所需的block作为参数传进去,实现ResNet 的 Conv2-5的每一个stage
def _make_layer(self, block, channel, block_num, stride=1): #channel表示主分支上卷积核的个数 block_num 表示堆叠残差层的个数
downsample = None
if stride != 1 or self.in_channels != channel * block.expansion:
# 利用nn的Sequential这个类,将各种操作封装到一个变量中,快速搭建
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channel * block.expansion))
layers = []
# 第一个block要特殊构造
layers.append(block(self.in_channels, channel, downsample=downsample, stride=stride)) #放入第一个block
self.in_channels = channel*block.expansion #上一次输出作为下一层输入
# 从第二个开始 全部是实线的残差结构
# 每stage多少blocks,就从第二个开始循环再添加剩余的block,
for i in range(1, block_num):
layers.append(block(self.in_channels, channel))
# 完成一个大块儿stage的构造
return nn.Sequential(*layers) #将列表转化为非关键字参数传入
def forward(self, x):
x = self.conv1(x) # 3*224*224--->64*55*55-->64*27*27 输出图像尺寸=(输入-卷积核大小+2*padding)/步长+1
x = self.BN1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x) # 64*27*27-->192*27*27--->192*13*13
x = self.layer2(x) # 192*13*13--->384*13*13 如果stride=1,padding=(kernel_size-1)/2,则图像卷积后大小不变
x = self.layer3(x) # 384*13*13--->256*13*13
x = self.layer4(x) # 256*13*13--->256*13*13--->256*6*6 (池化)
x = self.avgpool(x)
# x = torch.flattern(x,1)
x = x.view(x.size(0), -1) # 将多维度的Tensor展平成一维,才放入全连接层
x = self.fc(x)
return x
def Resnet34(num_classes=5):
return Resnet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes)
def Resnet152(num_classes=5):
return Resnet(Bottleneck, [3, 8, 36, 3], num_classes=num_classes)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









