






 本文探讨了大模型LLM如何改变推荐系统,对比了传统模型与LLM的优缺点,涉及特征工程、外部知识的利用,以及如何通过LLM进行文本理解和增强推荐效果。文章还提及了大模型在场景迁移和整体流程控制中的潜力,以及预训练与微调策略的应用。
本文探讨了大模型LLM如何改变推荐系统,对比了传统模型与LLM的优缺点,涉及特征工程、外部知识的利用,以及如何通过LLM进行文本理解和增强推荐效果。文章还提及了大模型在场景迁移和整体流程控制中的潜力,以及预训练与微调策略的应用。
大家好,我是kaiyuan。
大模型LLM在越来越多的领域开始崭露头角,比如我们在今年上半年曾在某电商平台落地过较为直观简单的LLMx搜索项目(我们称之为LLM应用的第一阶段),同时拿到线上收益,LLM的潜力可见一斑。
如果你也对LLM颠覆搜推广范式充满期待(虽然可能还要不少时间),持续梳理follow大模型在推荐系统中的应用工作,欢迎一起讨论!
既然是大模型在推荐系统中的应用,那么首先要梳理对比下传统推荐模型和LLM的优缺点,推荐到底在 "馋" LLM的什么?
| 推荐系统 | 大模型 | |
|---|---|---|
| 场景 | 千人千面、领域各异 | 通用模型,one for all |
| 输入 | 物品(百万、千万) | 字词文本(十万) |
| 参数规模 | 亿级别 | 千亿、万亿(计算复杂度高) |
| 学习范式 | Online learning | Pretrain-finetuning Prompt learning |
| 模型能力 | 缺乏语义信息、推理能力、可解释性等;可以充分利用协同信号 | 引入外部世界知识,语义信号丰富;可解释性强;缺少协同信号;冷启动友好 |
| placeholder | placeholder | placeholder |
| challenge | Mismatch between LLM pretrain objective and RS; LLM rely more on semantics, omit collaborative information; |
Mismatch between LLM pretrain objective and RS;
LLM rely more on semantics, omit collaborative information;
从应用视角出发,将LLM应用拆解到传统推荐系统的各个模块。参考自上交和华为合作的工作:How Can Recommender Systems Benefit from Large Language Models: A Survey。
一般推荐系统都包括以下几个关键流程:
用大模型做特征工程:利用LLM的外部通用知识和逻辑推理能力,将原始的输入信息生成额外的辅助信息,可以是对item或user的描述、标签、知识图谱补全等等。
ID-based 推荐系统存在一些问题
GPT4Rec通过用户的商品交互序列(title文本),通过合适的promt方式,生成虚拟query交给搜索引擎,检索出要推荐的商品。
传统新闻推荐系统受限于冷启动、用户特征建模、新闻内容理解等问题,无法很好地捕捉用户兴趣。利用LLM强大的能力,通过prompt的方式丰富新闻数据和理解能力。
GENRE(GEnerative News REcommendation),使用已有新闻数据的标题、摘要、分类等信息,构建合适的prompt喂给LLM,生成更丰富的信息特征。
论文中主要使用了三种利用LLM强化RS特征的方式:
传统推荐系统通常是domain-specific,无法融入世界/外部知识。有两种外部知识有助于推荐系统:
KAR(Knowledge Augmented Recommendation),
Narrative-driven recommendation (NDR) ,叙述驱动推荐系统,指用户通过自然语言的方式描述偏好和需求,推荐系统给出合适的结果。但目前研究大多都是基于用户历史行为数据的推荐,缺乏对NDR场景下长文本的处理能力。
NDR问题定义,给定用户u及其需求表述q,推荐系统f需要从候选集C中推荐出合适结果R。假设候选集和需求是相同领域的。
MINT(Data augMentation with INteraction narraTives),
相当于针对有描述类推荐的场景里(NDR),弥补了传统id-based推荐系统的文本处理能力;有点像推荐搜索化,将用户长本文通过LLM生成搜索query,然后去候选集里检索。
百度和港大合作的工作,用LLM解决推荐系统的数据稀疏性问题(论文讨论对象是基于图神经网络的推荐系统)。传统普遍做法是引入知识图谱、社交关系等,但在引入信息的同时也会引入噪声。
借用LLM的强大世界知识和推理能力,来辅助生成增强信息。包括以下增强方式

图片
使用大模型的通用语义表达能力进行编码,弥补传统推荐系统的信息缺失(例如文本等),进一步丰富user/item侧的语义表征。
场景是百度搜索召回,建模query-doc之间的相关性匹配。
简单说就是用ERNIE替代了传统双塔中的MLP等编码器,更好地建模q-i表征。双塔顶层交互方式参考了poly-encoder的模型,在训练和预测有一些不同,以适应模型上线需求。
更多详细参考:大规模搜索+预训练,百度是如何落地的?
人大和阿里合作的序列表征工作,发表在KDD'22。现有的推荐系统多基于item-id,导致其很难迁移到新场景(需要重训)。作者认为自然语言文本信息可以作为不同领域场景的桥梁,解决上述问题。
UniSRec,通过预训练方式建模通用item表征和通用序列表征,进而学习跨不同推荐场景的可迁移表征。
由于存在域间差异,简单地将不同域序列表征混合起来不会有很好的效果(因为多个域学习到的表征很可能是冲突的,会导致跷跷板现象)。
在传统self-attention网络的基础上,引入两个对比任务:sequence-item and sequence-sequence,缓解多领域序列表征之间的融合。
训练时将两种任务以多任务学习方式进行联合优化:
高效微调 :固定模型主要架构参数,在domain transfer时仅微调MoE的参数。
来自西湖大学SIGIR'23的工作,探索基于多模态大模型的推荐系统能否和经典基于ID范式的推荐系统硬刚【探索讨论向】。
作者指出很多之前的工作有尝试将NLP/CV预训练模型引入推荐系统,但往往都是关注在冷启动和新物品场景。这对于IDRec而言是不公平的,如果在非冷启场景,MoRec也能打败IDRec,那么推荐系统将有望迎来经典范式的变革。
实验设置:MoRec和IDRec唯一的不同之处是使用预训练的模态编码器来替代IDRec中的ID embedding向量。同时使用了两种常用的推荐网络模式,DSSM 和 SASRec。
Q1:在常规场景(非冷启动)MoRec能够打败IDRec吗?A1:与推荐模式有关,SASRec可以,但DSSM不行。意味着MoRec需要一个强大的推荐骨干(SASRec优于DSSM)和训练方法(seq2seq优于 <u,i> pair)才能激发基于模态的项目编码器的优势
Q2:对于推荐场景,NLP、CV的预训练模型产生的表征有足够的通用能力吗?我们应该怎样使用预训练模型生成的表征?A2:尝试两种方案,two-stage(先用预训练模型提取模态表征,然后作为特征加入推荐模型训练)和end2end(同时训练预训练编码器和推荐模型网络)。结果表明,end2end的方式效果更好,说明nlp、cv预训练得到的表征还没有做到真正的通用性和泛化性。
其他:
几个结论:
把大模型作为打分工具,得到最终排序好的候选list。通常是通过在LLM训练中引入相关的任务来实现,可以分为三种研究方向:
亚马逊在KDD'23的工作,针对序列推荐场景的冷启动和场景迁移问题,提出了用自然语言的方式对用户行为和商品进行建模。具体地
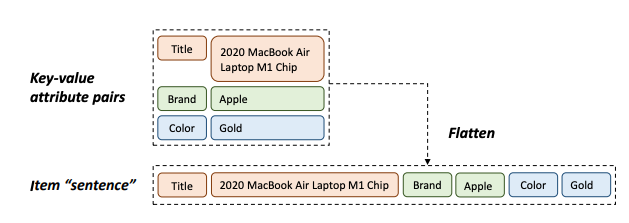
图片
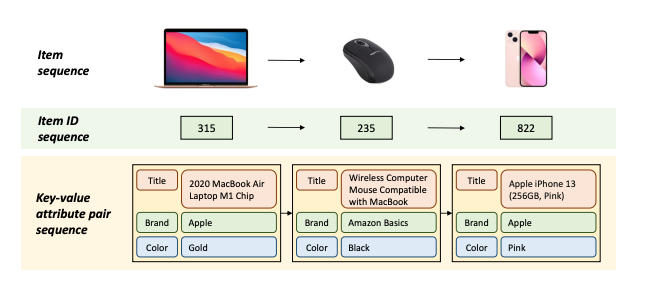
图片
随着LLM参数的越来越大,涌现出小模型所不具有的很多能力(in-context learning 、logical reasoning等),于是可以通过大模型进行推荐系统的整体流程控制。
从大模型训练和推理两个阶段出发,将现有工作分为四个象限


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









