






前言:欢迎关注我们的中文大语言模型开源项目Firefly(流萤)。目前我们的项目支持对baichuan、ziya、bloom、llama等主流大模型进行指令微调,同时支持全量微调和QLoRA高效微调。我们整理并开源了多个主流的高质量的中英文指令数据集,读者可以快速上手微调自己的大模型。
项目地址:https://github.com/yangjianxin1/Firefly
此前,Firefly项目依次开源了firefly-bloom-1b4、firefly-bloom-2b6、firefly-bloom-7b1和firefly-baichuan-7b等中文大模型,这些模型也见证了我们项目的迭代历程。
此次,我们将开源Firefly项目的第一个百亿参数规模的中英文大模型firefly-ziya-13b,该模型基于ziya-13b的预训练权重,使用百万中英文指令数据进行微调。
接下来的章节主要介绍firefly-ziya-13b的基座模型、训练策略、模型效果等。模型权重和训练数据等,详见文末链接。

图片
01
Ziya模型简介
此次我们开源的firefly-ziya-13b模型,正如其名称所示,我们选择了IDEA团队的Ziya-LLaMA-13B-Pretrain-v1作为基座模型。本章节主要对该基座模型进行介绍。
Ziya-LLaMA-13B-Pretrain-v1 是基于LLaMA的130亿参数大规模预训练模型,针对中文分词优化,并完成了中英文 110B tokens 的增量预训练,进一步提升了中文生成和理解能力。
原始数据包含英文和中文,其中英文数据来自openwebtext、Books、Wikipedia和Code,中文数据来自清洗后的悟道数据集、IDEA自建的中文数据集。在对原始数据进行去重、模型打分、数据分桶、规则过滤、敏感主题过滤和数据评估后,最终得到125B tokens的有效数据。
为了解决LLaMA原生分词对中文编解码效率低下的问题,IDEA在LLaMA词表的基础上增加了7k+个常见中文字,通过和LLaMA原生的词表去重,最终得到一个39410大小的词表,并通过复用Transformers里LlamaTokenizer来实现了这一效果。
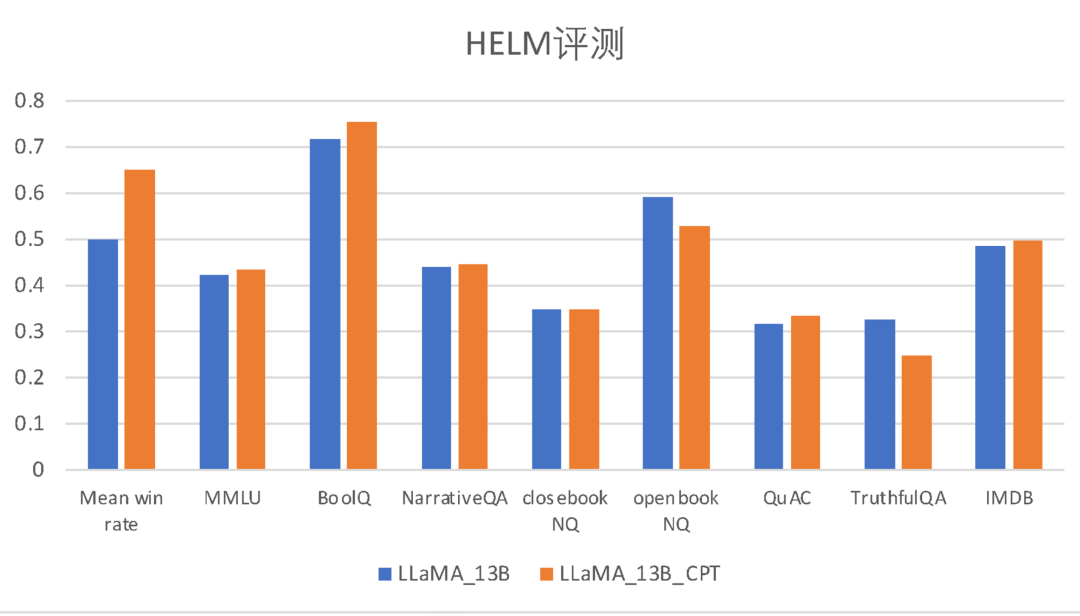
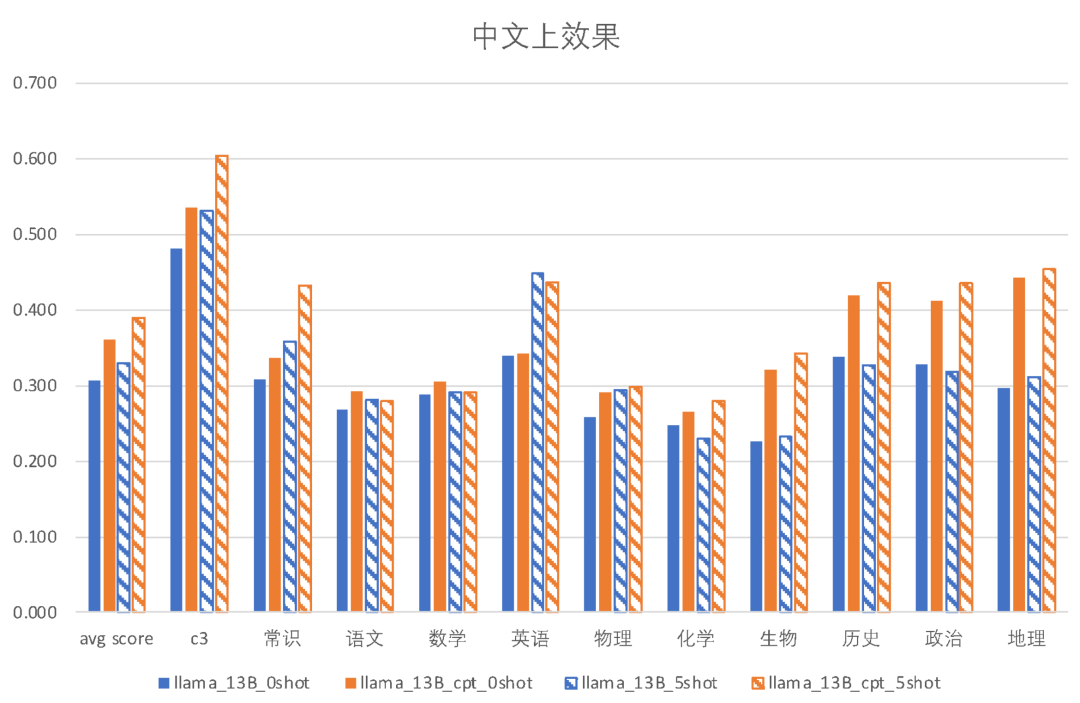
以下是Ziya-LLaMA-13B-Pertrain-v1 和原始的LLaMA 模型分别在中英文评测集上的表现。
图片
图片
可以看到,相比于LLaMA模型,Ziya-LLaMA-13B-Pertrain-v1在中文评测集上的0-shot与5-shot效果都更优秀,证明了其在中文能力上有显著的提升。且两者在英文评测集HELM上的效果基本上持平,在部分子任务上互有胜负,表明其英文能力没有受到较大的损失。
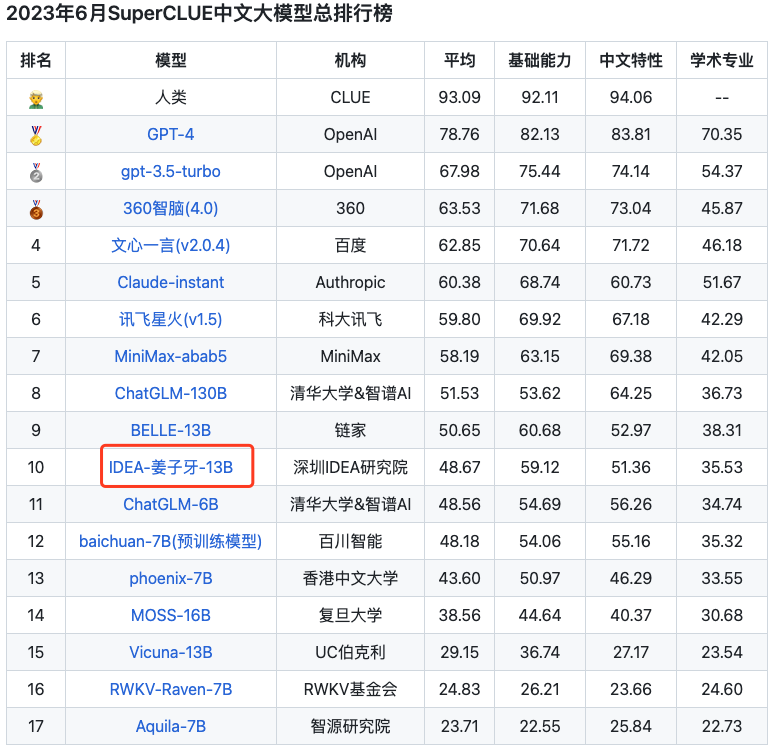
除此之外,我们关注到Ziya官方的sft模型在SuperCLUE中文大模型榜单上的表现也不错。
图片
Ziya-LLaMA-13B-Pertrain-v1在增量预训练时,采用的是全量参数训练,而不是LoRA等轻量级微调的方式,理论上来说会比LoRA增量预训练的模型效果更好。
基于上述分析,我们项目选择了Ziya-LLaMA-13B-Pertrain-v1作为13b的基座模型。
02
训练策略
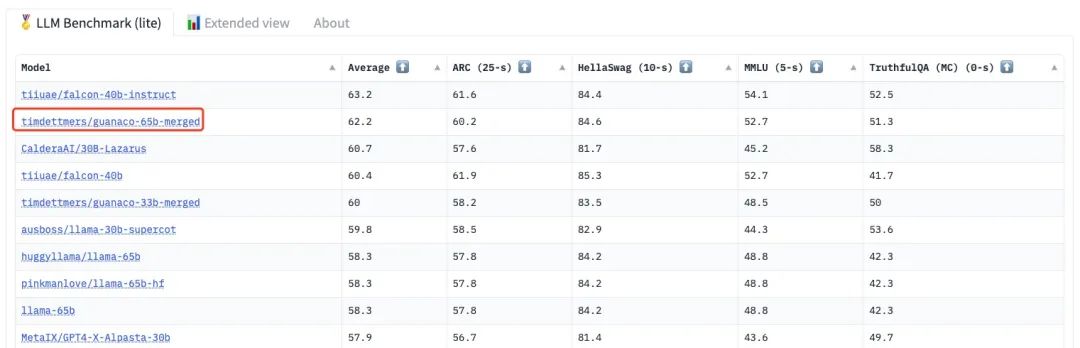
QLoRA是一种可以使用较低成本对大模型进行微调的技术,该方法具有非常不错的效果。QLoRA官方的Guanaco-65b模型在LLM Leaderboard中目前排名第二(注:该模型仅使用了9千多条OASST1的数据进行微调)。
图片
Firefly项目中集成了QLoRA训练流程,并且我们已经多次使用QLoRA训练模型,开源了firefly-bloom-7b1和firefly-baichuan-7b模型,获得了不错的效果。基于上述原因,我们依旧采用QLoRA技术训练firefly-ziya-13b模型。
对于QLoRA的原理和训练流程尚不熟悉的同学,可参考我们的往期文章:
【QLoRA实战】使用单卡高效微调bloom-7b1,效果惊艳
Firefly | QLoRA+百万数据,多卡高效微调bloom-7b1模型。
Firefly|百川baichuan-7B实测,QLoRA+百万指令数据微调
训练数据方面,我们依旧使用moss-003-sft-data数据,并且从BELLE项目的数学数据中,随机采样了5000条数据。合并之后数据量为100万+,训练一个epoch。
训练时,我们将多轮对话拼接成如下格式,然后进行tokenize。
在计算loss时,我们通过mask的方式,input部分的loss不参与参数更新,只有“target</s>”部分的loss参与参数更新。这种方式充分利用了模型并行计算的优势,训练更加高效,且多轮对话中的每个target部分都参与了训练,训练更充分。否则,就需要把一个n轮对话,拆分成n条数据,且只计算最后一个target的loss,大大降低了训练效率。
loss计算的实现方式可参考以下代码:
https://github.com/yangjianxin1/Firefly/blob/master/component/loss.py#L3
对于QLoRA,除了embedding和lm_head外,我们在所有全连接层都插入adapter,其中lora_rank为64,lora_alpha为16,lora_dropout为0.05。最终参与训练的参数量约为2.5亿。
训练超参数如下所示:
| max length | 1024 |
| lr_scheduler_type | constant_with_warmup |
| batch size | 64 |
| lr | 1e-4 |
| warmup step | 3000 |
| optimizer | paged_adamw_32bit |
| training step | 15k |
在单张V100上,使用QLoRA技术并且开启gradient_checkpointing后,可以将batch size设为8,长度设为1024,对13b的模型进行训练,所以读者可以低资源复现我们的模型效果。
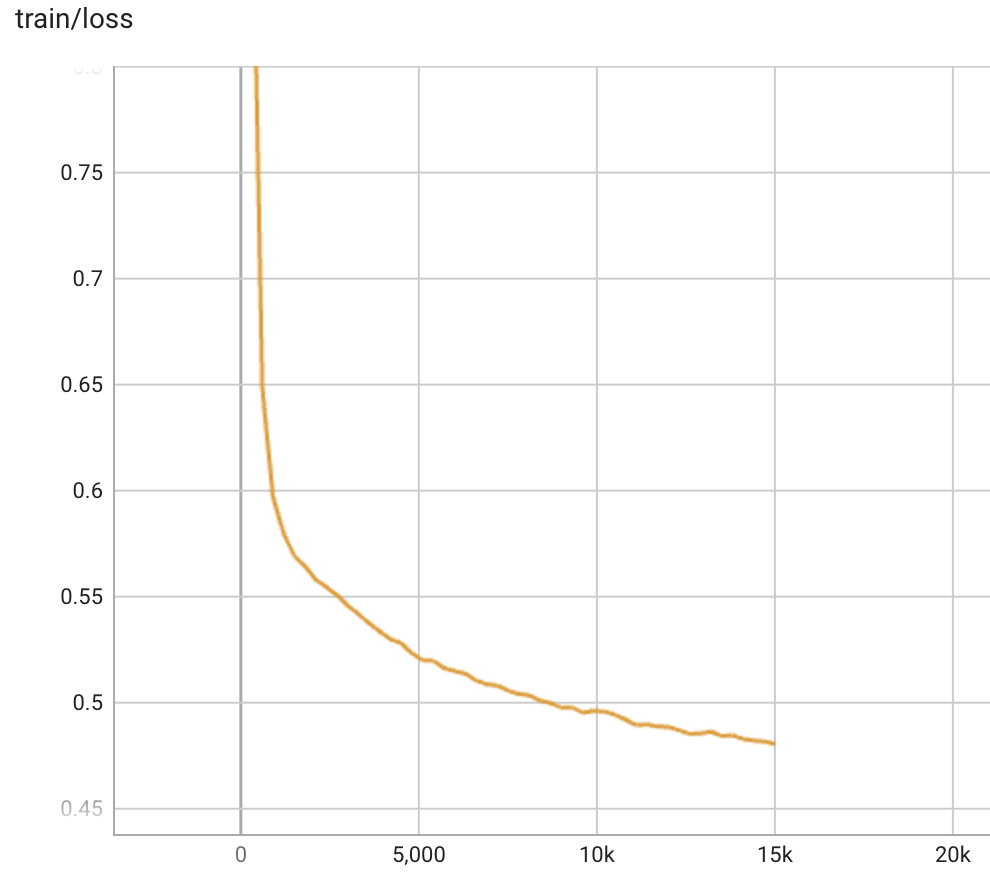
模型的训练损失的变化趋势如下图所示,训练损失的下降比较平滑,且比我们之前训练baichun-7b和bloom-7b1时的loss下降得更快更低。训完一个epoch之后,loss尚未有收敛的趋势。
图片
03
使用方式
模型的用法非常简单,直接运行下面的脚本即可,我们提供了单轮对话和多轮对话的脚本。该脚本兼容多模型,只需要修改model_name,即可使用我们之前开源的firefly-bloom-7b1和firefly-baichuan-7b模型。
使用firefly-ziya-13b进行单轮对话的方式如下:
使用firefly-ziya-13b进行多轮对话的方式如下:
04
模型效果
下面的样例均为firefly-ziya-13b模型所生成,未经修改,可能存在事实性错误,仅供参考。由于图片中的字体过小,建议放大图片后进行阅读。
更好的阅读效果,以及更丰富的生成样例,请查看文末的共享文档链接。
多轮对话
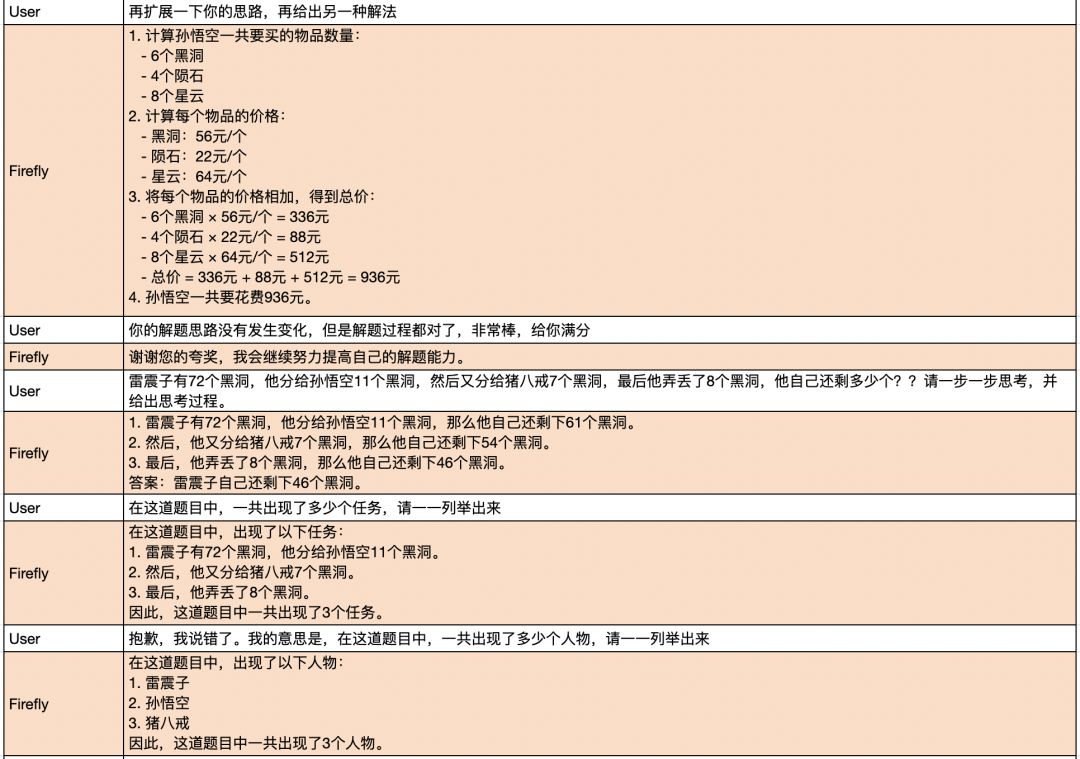
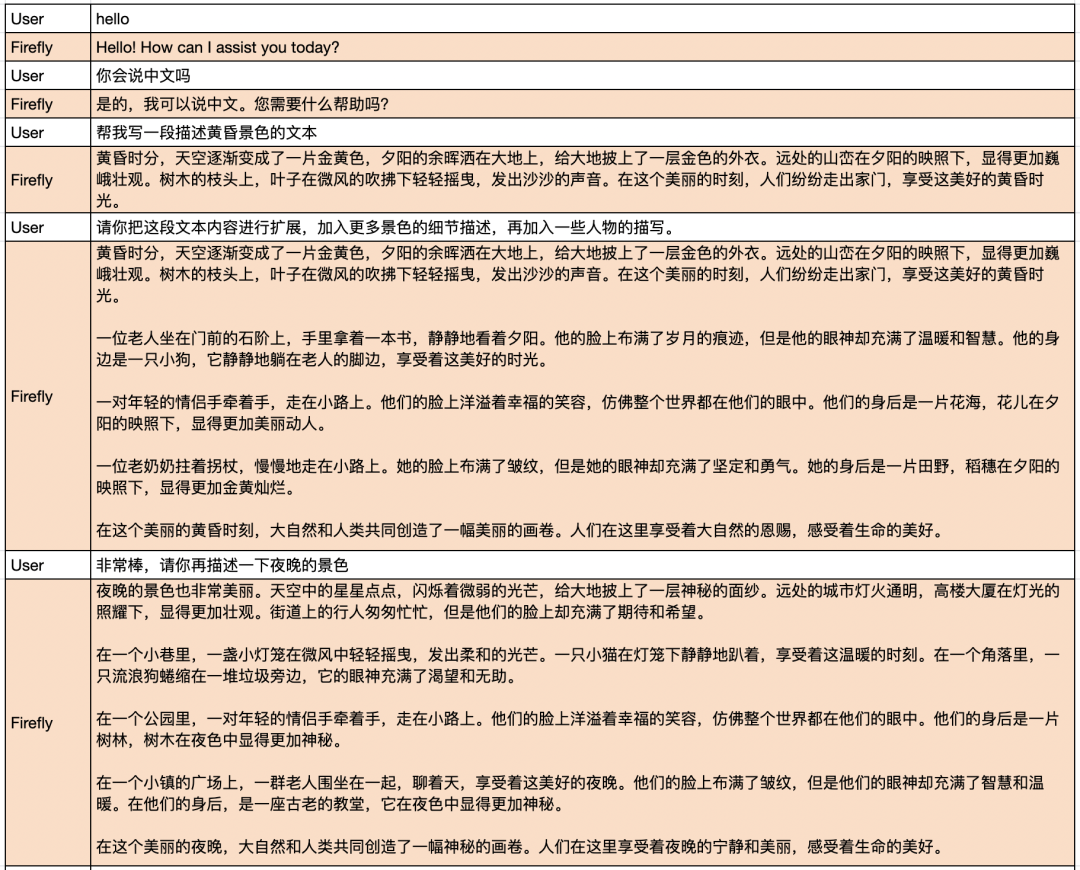
我们测试了模型的多轮对话能力,效果远超出了我们的预期,非常惊艳。模型在上下文理解、指代消歧方面的能力都非常优秀。即使是非常长的对话历史,模型也能正确地理解用户当前对话意图。
对话示例1:

图片
图片

图片
对话示例2:
图片

图片

图片

图片
数学题
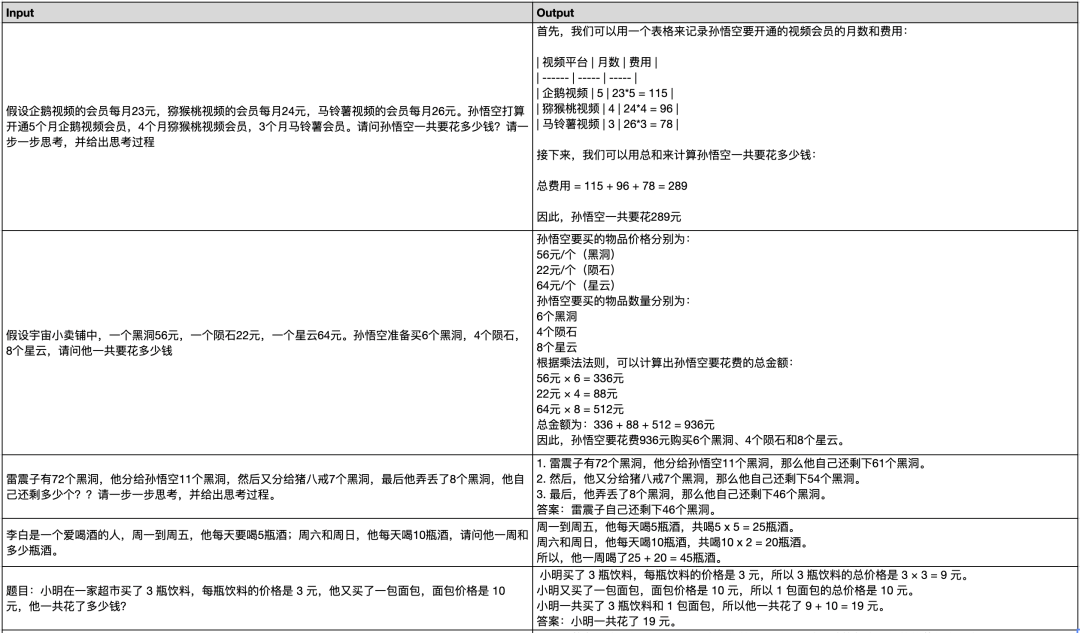
尽管我们只在训练语料中加入了5000条数学题的数据,但是模型依然给了我们很大的惊喜。这5000条数据,激活了模型的数学推理能力,在做一些常见的加减乘除数学题时,大多数情况下,模型能够清晰地给出解题步骤,并给出正确的答案。
仅用5000条数学数据激活模型的数学推理能力,这与LIMA和Guanaco,以及近来的研究结论相契合:知识来源于预训练,指令微调更多是与人类指令对齐,少数高质量的指令数据,即可很大程度激活模型的能力。
由于topp解码方式中带有一定的随机性,有时可能会采样到错误的解题思路,从而得到错误的结果。在解数学题的时候,可以尝试beam search或者贪婪解码等确定性解码策略。
为了避免数学题在训练集中出现过,下面的测试题目均为我们大开脑洞,随机书写的。
图片

图片
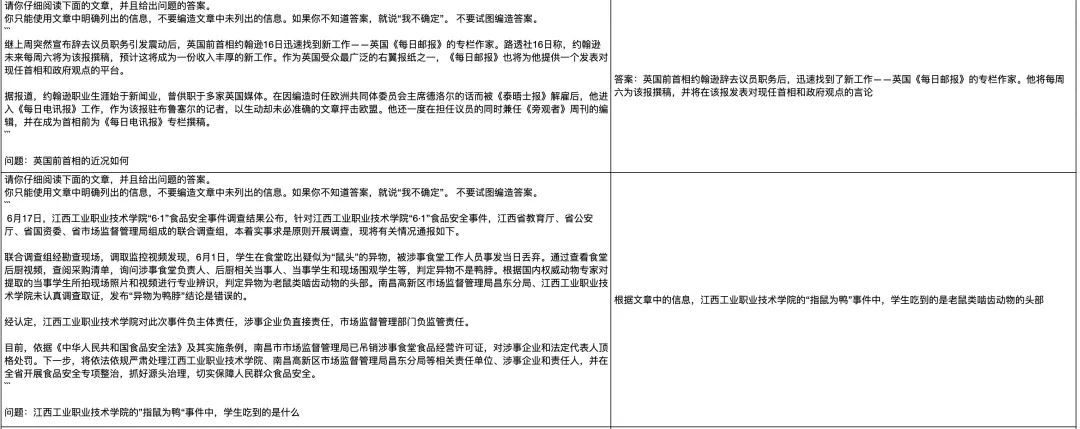
知识库问答
我们从网上找了一些近期的新闻片段,来测试模型的知识库问答能力。模型的表现也相当不错,基本上都能够根据给定的文章内容,生成合适的答案,这在知识库问答场景中有非常大的实用价值。

图片

图片
图片

图片

图片

图片

图片
医疗问答

图片

图片
中英翻译
我们测试了一些常规的中英翻译case,以及将古诗词翻译成英文的能力,表现也不错,翻译结果与古诗词表达的意境相近。

图片

图片
邮件生成

图片

图片
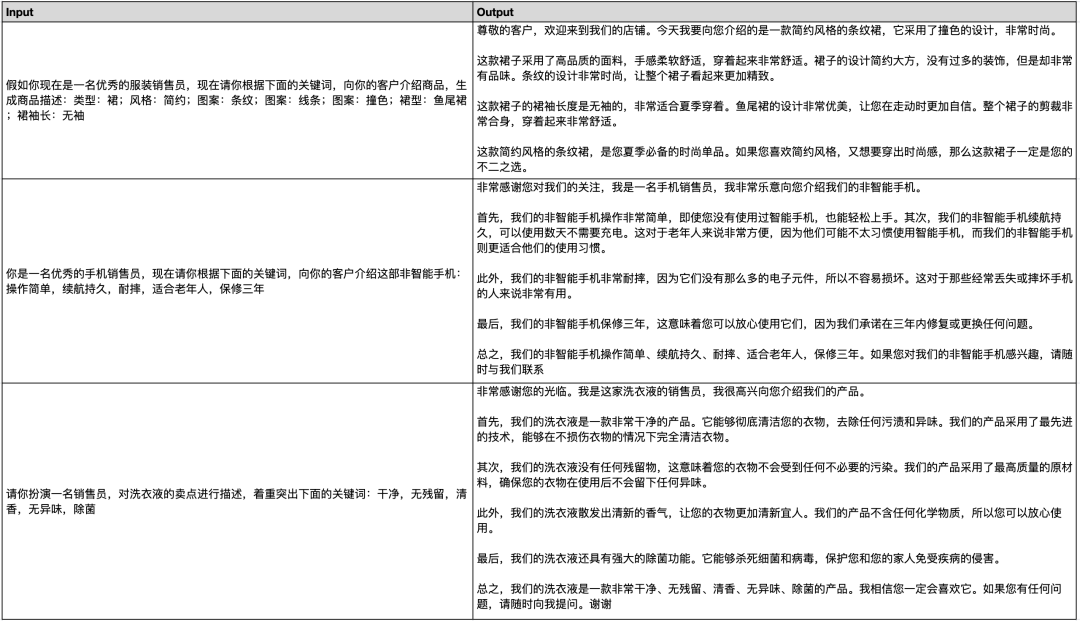
商品文案生成
图片
其他示例

图片

图片

图片

图片
更多生成示例,请扫描下面的文档二维码,查看共享文档的内容:
图片
05
结语
从有限的评测case来看,firefly-ziya-13b具有十分优秀的指令遵从能力,且Ziya-LLaMA-13B-Pretrain-v1+QLoRA的方式,值得在中英文下游任务中进行尝试。
由于尚未在开源测试集或LLM榜单上进行评测,客观的评测结果尚不得知。后续若有时间精力,将会对评测部分的工作进行补充。
后续我们将会在模型量化、推理加速、模型评测等方面对项目进行优化,欢迎大家持续关注Firefly项目:
https://github.com/yangjianxin1/Firefly
欢迎大家到知乎评论区一起讨论交流,点击阅读原文即可跳转到知乎文章。
firefly-ziya-13b权重:
https://huggingface.co/YeungNLP/firefly-ziya-13b
Ziya-LLaMA-13B-Pretrain-v1权重:
https://huggingface.co/YeungNLP/Ziya-LLaMA-13B-Pretrain-v1
moss数据集:
https://huggingface.co/datasets/YeungNLP/moss-003-sft-data
math数据集:
https://huggingface.co/datasets/YeungNLP/school_math_0.25M















 1668
1668











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









