






 本文探讨了大型语言模型在代理任务中的局限性,提出了Agent-FLAN方法,通过分离训练数据、能力平衡和幻觉评估,显著提高了Llama2模型在代理评估基准上的性能。Agent-FLAN通过改进数据处理和方法设计,有效地解决了模型在理解和执行代理任务中的问题。
本文探讨了大型语言模型在代理任务中的局限性,提出了Agent-FLAN方法,通过分离训练数据、能力平衡和幻觉评估,显著提高了Llama2模型在代理评估基准上的性能。Agent-FLAN通过改进数据处理和方法设计,有效地解决了模型在理解和执行代理任务中的问题。
大型语言模型(LLMs)在自然语言处理(NLP)任务中取得了巨大成功,但在作为代理(agent)时,它们的表现远远落后于基于API的模型。如何将代理能力集成到通用LLMs中,成为一个关键且紧迫的问题。现有的研究主要集中在提示工程或特定任务的框架调度上,但这些方法存在成本高、安全性问题等限制。
目前开源大型语言模型(LLMs)在一般代理任务中典型的两种幻觉的插图:(a) 格式幻觉和 (b) 行为幻觉。

为了解决上述问题,提出了Agent-FLAN方法,该方法基于三个关键观察结果:代理训练数据与预训练数据分布的差异、LLMs在代理任务所需能力上的不同学习速度、以及现有方法在提升代理能力时引入的幻觉问题。
Agent-FLAN通过以下步骤进行:
-
将代理训练语料库中的格式遵循和通用推理分离,使微调过程与语言模型的预训练领域(自然对话)保持一致。
-
明确分解训练数据,根据LLMs的基本能力(如推理、检索、理解、指令遵循)进行数据平衡。
-
构建Agent-H基准测试,从多个角度评估LLMs的幻觉问题,并精心策划多样化的“负面”训练样本以有效缓解这一问题。
通过将原始的代理语料库与自然对话对齐,能够明确地将代理任务分解为不同的能力,从而实现更细致的数据平衡。

Agent-FLAN在开源的Llama2系列模型上的应用,使其在多个代理评估基准测试中的表现比先前的工作提高了3.5%。此外,Agent-FLAN在扩大模型规模的同时,持续提升了LLMs的代理能力,并对LLMs的一般能力有轻微提升。实验结果表明,Agent-FLAN在减少幻觉问题的同时,能够有效提升模型在代理任务上的性能。
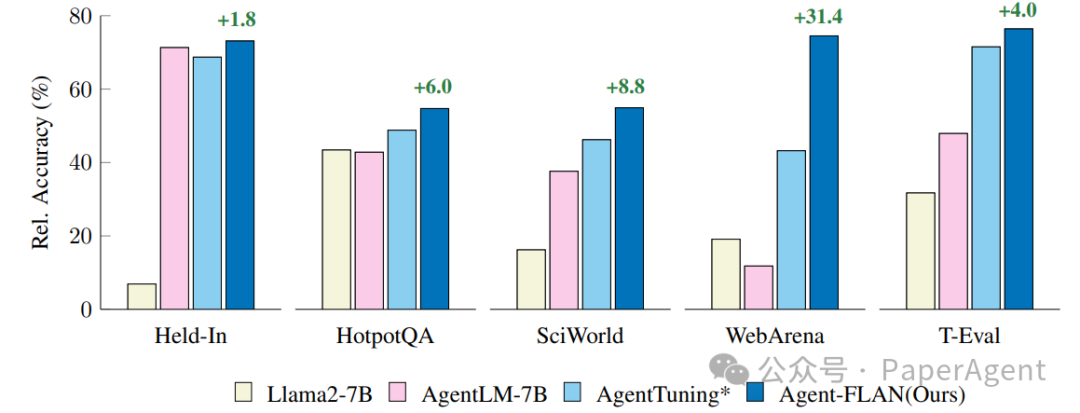
Agent-FLAN在内部保留(Held-In)和外部验证(Held-Out)任务上的比较。为了更好的可视化,性能结果已经与GPT-4的结果进行了标准化。* 表示为了公平比较而重新实现了该方法
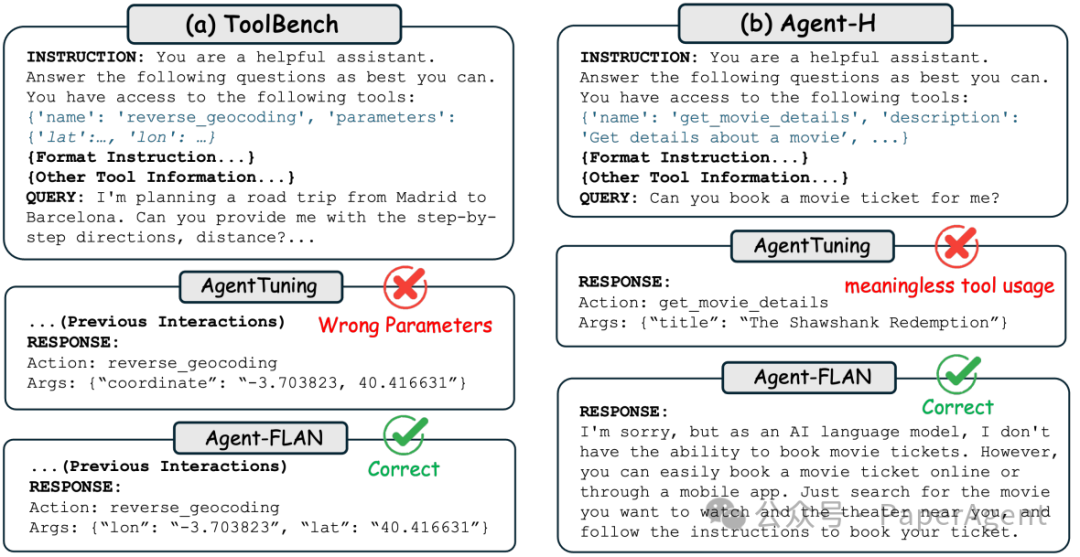
在Toolbench和Agent-H数据集上,使用Llama2-7B模型进行的AgentTuning和Agent-FLAN之间的比较研究。(a) ToolBench:得益于能力分解和对“理解”能力的更多关注调整,Agent-FLAN能够跟上给定的长工具信息内容的具体API信息,而AgentTuning因为幻觉而失败。(b) Agent-H:AgentTuning模型展示了无意义的工具使用,而Agent-FLAN直接给出了首选的响应。
Agent-FLAN: Designing Data and Methods of Effective Agent Tuning for Large Language Modelshttps://arxiv.org/pdf/2403.12881.pdfhttps://github.com/InternLM/Agent-FLAN















 1664
1664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









