






大模型在垂直领域的应用落地是目前工业界的关注重点,针对知识密集型的垂直领域业务场景,除了大模型之外,往往还需要垂直领域的知识图谱(KG)作为外部知识源辅助。
本文提出了一个大模型知识偏好对齐框架 KnowPAT,实现大模型偏好与人类偏好对齐,同时将作为垂直领域知识图谱引入到了模型对齐的过程中,以提升答案生成的质量。

图片
论文地址:https://arxiv.org/pdf/2311.06503.pdf
Github地址:https://github.com/zjukg/KnowPAT
摘要
本文介绍了一种新的流程,将大型语言模型(LLMs)应用于领域特定的问答(QA),并结合领域知识图谱(KGs)解决了LLMs应用中的两个主要难点:生成用户友好的内容和正确利用领域知识。作者提出了知识偏好对齐(KnowPAT)方法,通过构建风格偏好集和知识偏好集来解决这两个问题,并设计了新的对齐目标来训练更好的LLMs。实验结果表明,KnowPAT是一种优秀的流程,可用于实际场景中的领域特定问答。
简介
互联网的快速发展催生了许多新的商业模式,如电子商务和云服务。针对特定领域的智能问答服务是提高服务质量的关键任务。传统深度学习模型在领域专业知识方面仍有不足,因此领域知识图谱成为存储和查询领域特定知识的重要媒介。大语言模型在自然语言处理领域取得了显著进展,应用于各种下游任务成为互联网行业的主要方向。将知识图谱作为外部知识源与大型语言模型结合,进行领域特定的智能问答仍有待进一步探索。
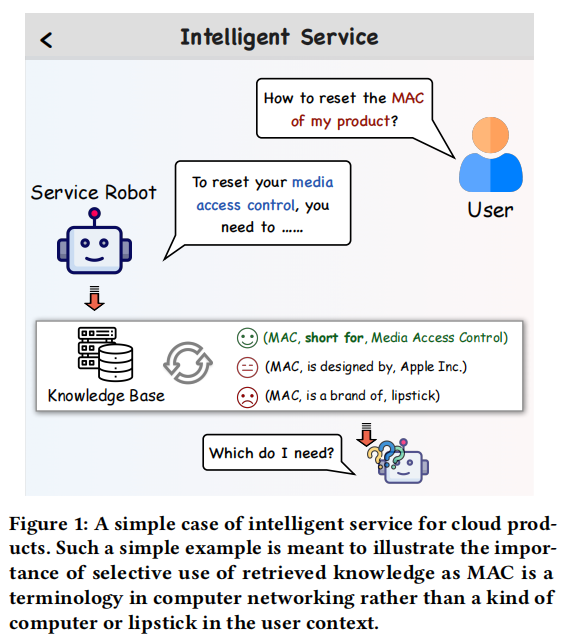
图片
本文介绍了一个名为KnowPAT的新颖框架,用于解决基于领域知识图谱的实际场景下的问答问题。该框架通过构建领域知识图谱来获得领域知识,并设计了一种新的对齐目标来优化LLM模型。实验证明,KnowPAT是一个优秀的框架,相比于15个现有的基线模型,在实际应用中具有更好的效果。
相关工作
知识图谱增强问答系统
我们提出了一种基于知识偏好的框架,用于增强知识图谱感知的问答系统。该框架适用于云服务产品的领域特定问答场景。与其他基于知识图谱的问答系统不同,该框架不需要使用大型语言模型进行对话,而是通过知识偏好来提高问答的准确性。
LLMs的偏好对齐
我们提出了一种基于领域知识图谱的偏好对齐框架,通过构建知识偏好集,训练LLMs以与人类偏好对齐,并选择更好的事实知识来解决问答任务。同时,文章还介绍了其他PA方法,如RRHF、RAFT、SLiC-HF、PRO、DPO和AFT等。
问题定义
本文介绍了使用偏好数据fine-tune LLMs的一般流程,目标是fine-tune一个LLM M,使用QA数据集D,其中每个数据点包含一个问题和一个答案。对于vanilla fine-tuning(VFT),首先将QA对包装在一个prompt模板I中,然后使用自回归损失函数进行优化。
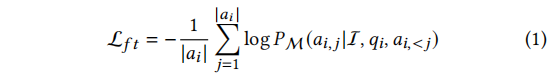
图片
然而,对于特定领域的QA来说,这种VFT方法并不能取得很好的效果。一方面,现实场景中的应用需要用户友好,否则不会带来商业价值;因此,生成的响应的文本样式应该更容易被用户接受。另一方面,知识检索过程是无监督的,检索到的知识的有效性难以保证,这意味着模型M需要具备判断和选择性利用知识三元组的能力。因此,要解决这两个问题,就要对基础VFT进行改进。
实际上,这两个问题都可以总结为模型偏好。LLM M有其生成文本的风格偏好和有选择地利用检索到的知识的知识偏好。为了使模型实际适用,模型偏好应与人类偏好保持一致,旨在生成人类偏好的高质量答案。偏好对齐(Preference alignment, PA)是LLMs的一个重要课题。为了在LLM微调期间应用PA,我们采样了一个偏好集P ={𝑏1,𝑏2,…,𝑏𝑙},每个问答对有𝑙不同的答案(𝑞,𝑎)。我们表示𝑟𝑖为每个答案的偏好分数𝑏𝑖,更高的𝑟𝑖表示人类更喜欢这个答案。在训练过程中,我们将定义另一个目标L𝑎𝑙𝑖𝑔𝑛以使模型M与偏好集P对齐,旨在增加人类首选答案出现的概率,同时减少非首选答案的概率。人类对每个答案的偏好是偏好得分𝑟。那么整体的培训目标就变成:
![]()
图片
在这样的多任务目标下,模型M被微调以拟合黄金答案,同时避免不理想的结果。接下来的问题是如何生成既能反映风格偏好又能反映知识偏好的偏好集。在下一节中,我们将提出一个知识丰富的偏好对齐管道。
知识偏好对齐流程
图片
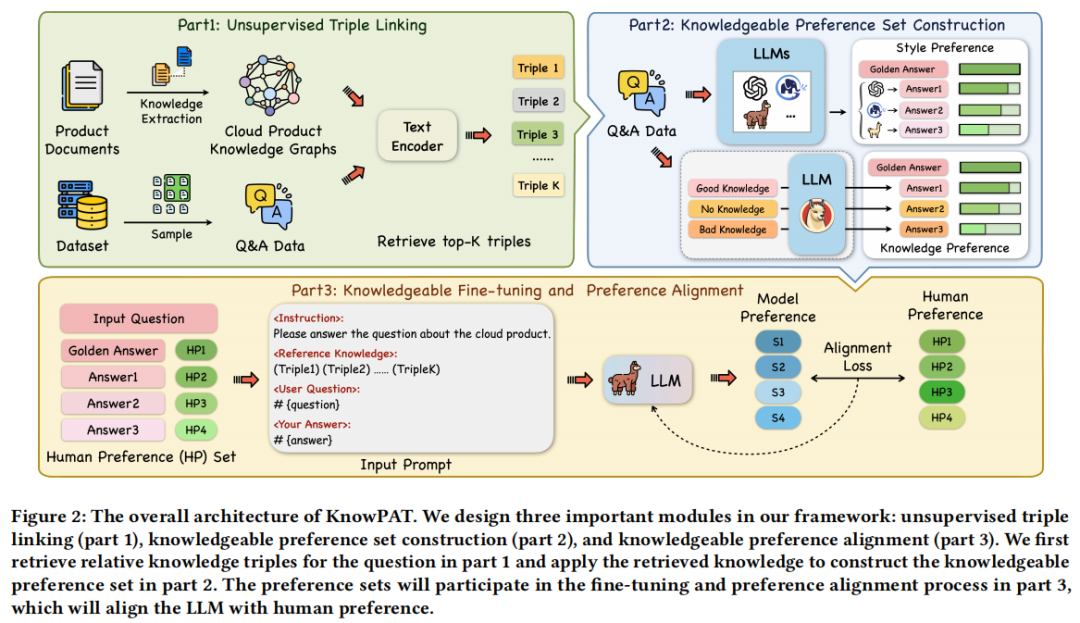
知识偏好对齐(KnowPAT)流程包括三个关键部分:无监督三元组链接、知识偏好集构建、微调和训练。图2展示了我们管道中三个部分的直观视图。
无监督三元组连接
无监督三元链接是将CPKG G中的三元组与每个问题𝑞𝑖进行链接的关键部分。我们设计了一个简单的基于语义相似度的检索器H来实现这个目标。第𝑖个问题𝑞𝑖与第𝑗个三元组(ℎ𝑗, 𝑟𝑗, 𝑡𝑗)之间的相似度为
![]()
图片
其中,检索器H作为文本编码器,我们将问题和知识三元组都视为文本序列,以获取它们的句子表示。相似度基于两个表示的余弦相似度。我们检索每个问题𝑞𝑖中与之相似度最高的𝑘个三元组,并将检索到的知识(K)作为背景知识添加到输入提示中,用于当前问题的解答。这个过程是无监督的,因为我们没有手动标记的问题-知识对。此外,我们的模型将用于实际场景使用,因此它还需要对新问题具有强大的零样本泛化能力。出于这两个原因,检索到的知识K可能是嘈杂和无用的,无法为问题解答提供背景知识。我们认为LLM M应该学习知识偏好,从检索到的知识K中选择有用的信息。
知识偏好集的构造
本文提出了一种知识偏好集构建方法,包括风格偏好集和知识偏好集。风格偏好集由多个不同的LLM模型生成,能够产生不同的文本风格。知识偏好集则包含人工标注的黄金答案和LLM模型生成的答案,用于检索知识。这种方法旨在提高文本摘要的质量和效率。
知识偏好集(KPS)是根据知识三元组的相似度来确定知识的有用性。我们通过检索一些相对较差的知识,并提示模型使用不同质量的知识生成回答,从而得到不同质量的偏好集。在我们的设计中,我们从CPKG中检索到三组知识三元组K1、K2、K3。K1代表检索到的前k个三元组,K2是一个空集,没有检索到知识。K3代表相似度在k+1到2k之间的三元组,我们认为这些知识容易被误用,具有相对较高的语义相似度。然后,我们将不同的知识Ki与输入提示I一起传入LLM M,并生成不同的答案。这些生成的三个答案和黄金答案构成一个风格偏好集Pk={c1,c2,c3,c4}。
通过对每个QA对进行两个偏好集的构建,设计了基于规则的策略来决定每个答案的偏好分数。其中,高质量的黄金答案被分配最高分数,其他LLMs的答案则根据其一般能力确定。同时,作者选择了三个不同的LLMs来进行评估,分别是ChatGPT、ChatGLM-6B和Vicuna-7B。经过人工专家的验证,这三个模型的答案质量也符合这个规则。最终,作者提出的方法可以有效地评估语言模型的质量。
通过构建两个偏好集合,分别控制风格和知识偏好,可以简化代码实现。其中,对于知识偏好集合,根据不同的知识来源,设置了不同的偏好得分,以控制模型对不同知识的使用。同时,为了避免知识与问题不匹配导致模型误判,设置了空知识得分高于不匹配知识得分。最终,通过对2N个偏好集合进行微调,可以控制模型的风格和知识偏好。
微调和偏好对齐
除了传统的fine-tuning loss外,偏好数据也参与了训练过程。作者设计了一个新的偏好分数来表示模型的偏好程度,并提出了一个对齐目标来使模型的偏好与人类期望一致。该方法可以提高模型的性能和可解释性。
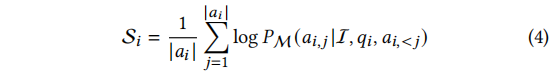
图片
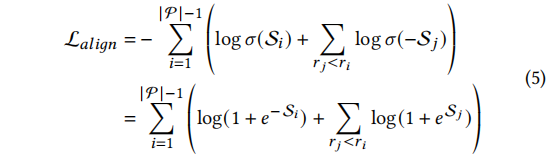
图片
我们介绍了一种新的训练目标,用于实现偏好对齐过程。该目标通过比较优选答案和非优选答案来对模型进行优化。现有的方法使用边际排名损失来实现偏好对齐,但这些方法只在模型偏好得分低于非优选答案时进行优化。作者认为即使在这种情况下,偏好仍然应该进行优化,并提出了一种训练目标来不断降低非优选答案的出现概率。此外,作者还设计了自适应权重来控制每个优选答案的影响力。最终的训练目标是一个多任务目标,其中包含一个超参数作为对齐损失的系数。
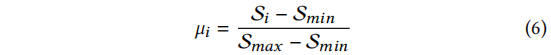
图片
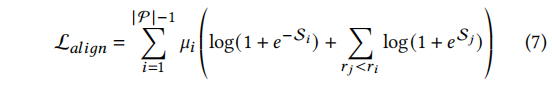
图片
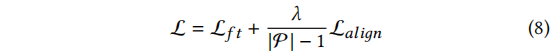
图片
实验设置
数据集
实验使用了两部分数据集。第一部分是CPKG,包含13995个实体,463个关系和20752个三元组。QA数据集包含8909个问答对,我们将数据集划分为7909/500/500用于训练/验证/测试。对于训练中的每个数据实例,我们构建了两个偏好集,并最终得到了15818个每个集合中包含4个答案的偏好集。
基线模型
为了证明本方法的有效性,我们选择了四种不同的基准方法进行比较,包括零样本学习、上下文学习、微调和其他偏好对齐方法。作者认为,偏好对齐是比其他方法更好的LLM应用框架。同时,作者还选择了五种最先进的偏好对齐方法作为基准,以证明该方法的优越性。
评估指标
我们使用了三种不同层次的评估指标,包括传统的文本生成指标、基于模型的指标和人工评估指标。这些指标分别从文本相似度、语义相似度和人类偏好等方面评估生成答案的质量。其中,基于模型的指标包括BERTScore、perplexity和偏好分数。人工评估指标则通过单盲测试来评估不同方法的效果。
实现细节
选择Atom-7B-chat作为骨干LLM,该模型是Llama2的开源版本,具有中文词汇扩展。使用开源Llama架构模型增强方法的通用性,同时在云产品文档上对Atom-7B-chat进行微调。使用BGE-base-zh-v1.5作为检索器H进行无监督三元链接。在训练过程中,使用bf16浮点精度调整骨干模型,训练时代数为3,梯度累积步骤为8。使用AdamW优化器进行模型优化,学习率固定为3e-4,使用默认调度程序。超参数λ在{1,0.1,0.01,0.001}中搜索。
我们在知识预训练模型的基础上,使用零样本学习、上下文学习和参数适应等方法来提高问答系统的性能。作者选择了多个预训练模型作为基线,并使用了不同数量的样本来进行上下文学习。作者还实现了多种参数适应方法,并使用Atom-7B-CP作为基础模型。作者在GitHub上发布了训练和评估代码,但由于商业机密原因,数据集无法公开。
实验结果
本文研究了四个问题:
提出的方法KnowPAT与基线方法相比表现如何;
KnowPAT中的模块是否真正有益于性能;
是否有直观的案例证明KnowPAT的有效性;
LLM是否仍然具有一般能力而不是灾难性遗忘。
这四个问题从性能、设计合理性、直观性和在实际场景中的可用性四个方面评估了我们的方法。
主要结果
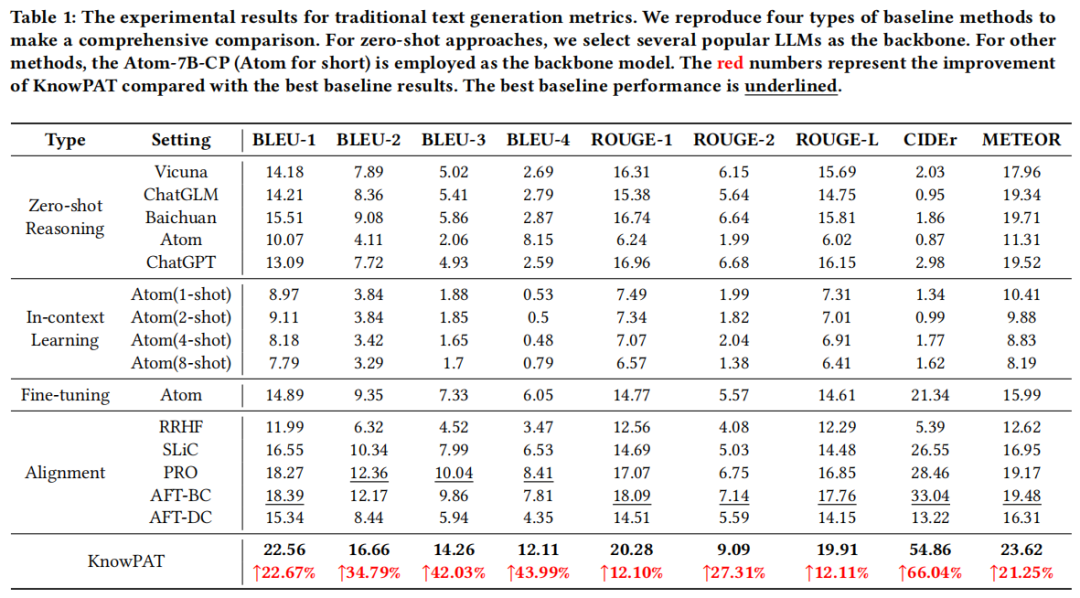
图片
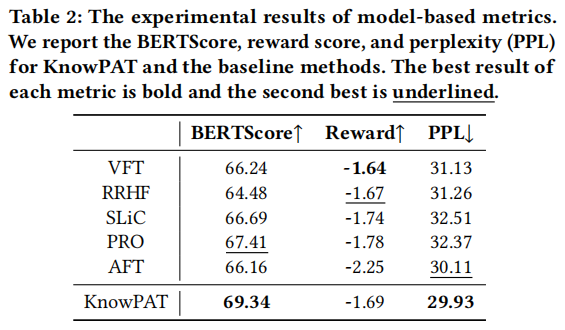
图片
通过传统指标、模型指标和人工评估三个角度对KnowPAT进行了评估。结果表明,KnowPAT在BLEU-3和BLEU-4指标上表现更好,能更好地捕捉复杂短语和语篇,适用于云产品问答场景。同时,KnowPAT在模型指标和人工评估中也表现出色,生成的答案更符合语言模型和人类的期望。
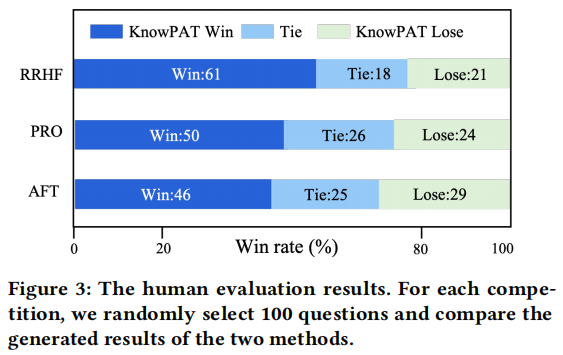
图片
消融分析
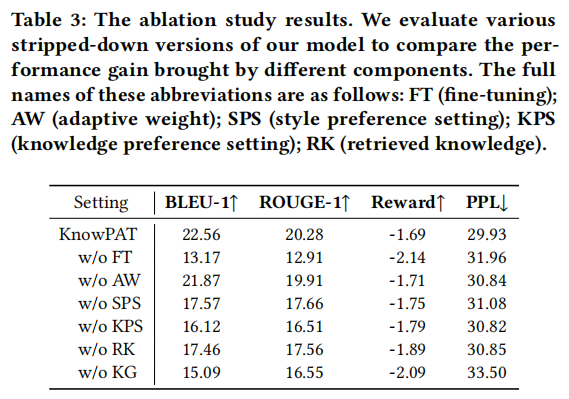
图片
我们进行了消融实验来验证每个模块设计的有效性。我们验证了我们的KnowPAT中设计组件的有效性。我们发现微调目标L𝑓𝑡和对齐目标L𝑎𝑙𝑖𝑔𝑛都对模型性能有贡献。没有进行微调(FT),模型性能会严重下降,因为LLM没有调整到适应黄金答案。此外,KnowPAT中的两个偏好集(SPS和KPS)都对性能有贡献。自适应权重(AW)可以控制不同质量样本在损失中的参与,这在KnowPAT中也是有效的。此外,我们通过两组实验证明了CPKG的必要性。w/o RK表示在微调和偏好对齐过程中删除输入提示中检索到的知识的实验。w/o KG表示在整个过程中没有使用KG的实验,这意味着输入提示中的KPS和RK都被删除了。对于这两组实验的结果,我们可以观察到CPKG在KnowPAT中起到了显著的作用。在KnowPAT的设计中,CPKG不仅在训练过程中作为外部知识源,还参与了偏好集构建过程,这对模型性能很重要。总之,我们方法KnowPAT中的每个详细设计都有其独特的作用,并对整体性能有贡献。
案例分析
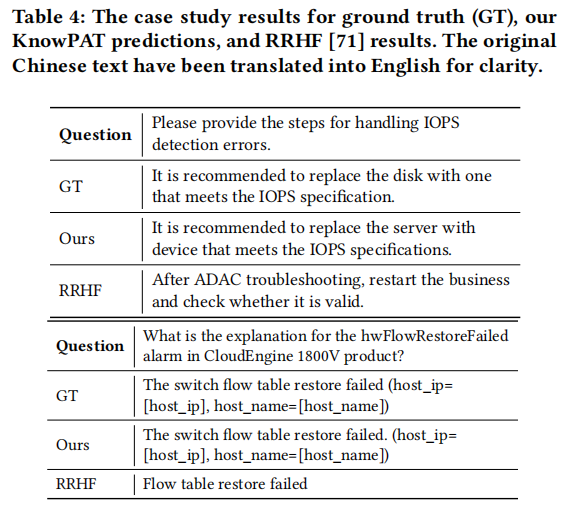
图片
通过案例研究,我们发现KnowPAT生成的答案更接近黄金答案,同时保持了用户友好的语气,并提供了足够的信息,比如第二个案例中的主机参数。这表明模型学会了适当的风格偏好。此外,在第一个案例中检索到的知识是(EIP, 用于, IP绑定),(选择框, 属于, 告警管理组件)等,这些都无法回答这个问题。然而,KnowPAT并没有被这些无用的知识所误导,生成了正确的答案,而RRHF则陷入了困境。
知识保持分析
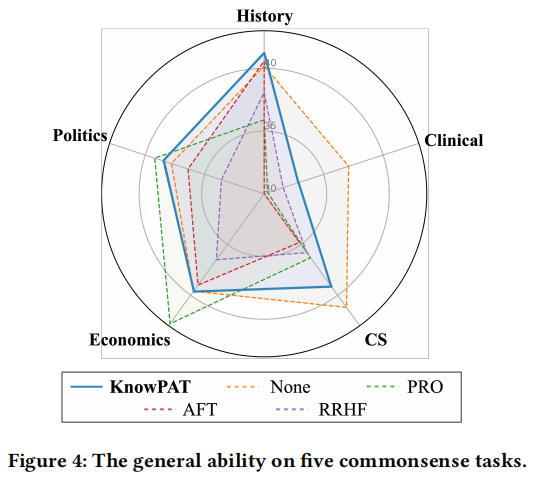
图片
我们通过对CMMLU数据集进行常识评估,展示了KnowPAT和其他PA方法在历史、临床、政治、计算机科学和经济等领域的一般能力。结果显示,KnowPAT在医学领域的能力有所下降,但在政治、历史和经济领域仍保持了原始模型的能力甚至有所提升。与此相比,PRO在经济问题上表现出了显著的改进,但在其他领域的性能下降更为明显。总的来说,KnowPAT在一般能力上的变化对于云产品的问答场景是可以接受的。
总结
本文介绍了一种新的框架——知识偏好对齐(KnowPAT),用于云产品服务中的领域特定的问答任务,利用LLMs和KGs在实际应用中。该方法通过检索和利用知识三元组构建知识偏好集,生成不同数量的答案。设计了一个新的对齐目标来释放偏好集的力量。全面的实验表明,我们的方法超越了现有的解决方案,适用于这个真实世界的挑战。展望未来,我们的目标是将KnowPAT应用于其他业务场景,并进一步研究KG增强LLMs的潜力。
灵度智能,我们致力于提供优质的AI服务,涵盖人工智能、数据分析、机器学习、深度学习、强化学习、计算机视觉、自然语言处理、语音处理等领域。提供AI课程、AI算法代做、论文复现、远程调试等服务。如有相关需求,请私信与我们联系。
我们的愿景通过创新创意和智能技术为客户提供卓越的解决方案,助力产业升级和数字化转型。我们的产品和服务将引领行业标准,创造卓越的用户体验。我们的团队致力于创造更智能、更便捷和更高效的生活方式,推动社会进步,致力于创造更美好的未来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









