







在数据科学领域,客户细分是理解和分析客户群体的重要步骤。最近,我发现了一个名为“Clustering with LLM”的GitHub仓库,它由Damian Gil Gonzalez创建,专门针对这一领域提供了一些先进的聚类技术。在这篇文章中,我将概述这个项目的核心内容和方法,以及它如何帮助数据科学家们提升他们的技能。
项目简介
“Clustering with LLM”项目旨在探索定义聚类和分析结果的高级技术。这个仓库是为那些希望扩展其处理聚类问题的工具箱并朝着成为高级数据科学家迈进的数据科学家们准备的。
覆盖内容
该项目将涵盖三种处理客户细分项目的方法:
- K-means:一种常用的聚类方法,项目中将深入探讨它以展示高级分析技术。
- K-Prototype:当数据集包含混合类型特征(分类和数值)时,这种方法可以用来创建聚类。
- LLM + K-means:项目中的亮点,展示了如何应用LLM(Large Language Model,大型语言模型)在聚类项目中获得卓越结果。
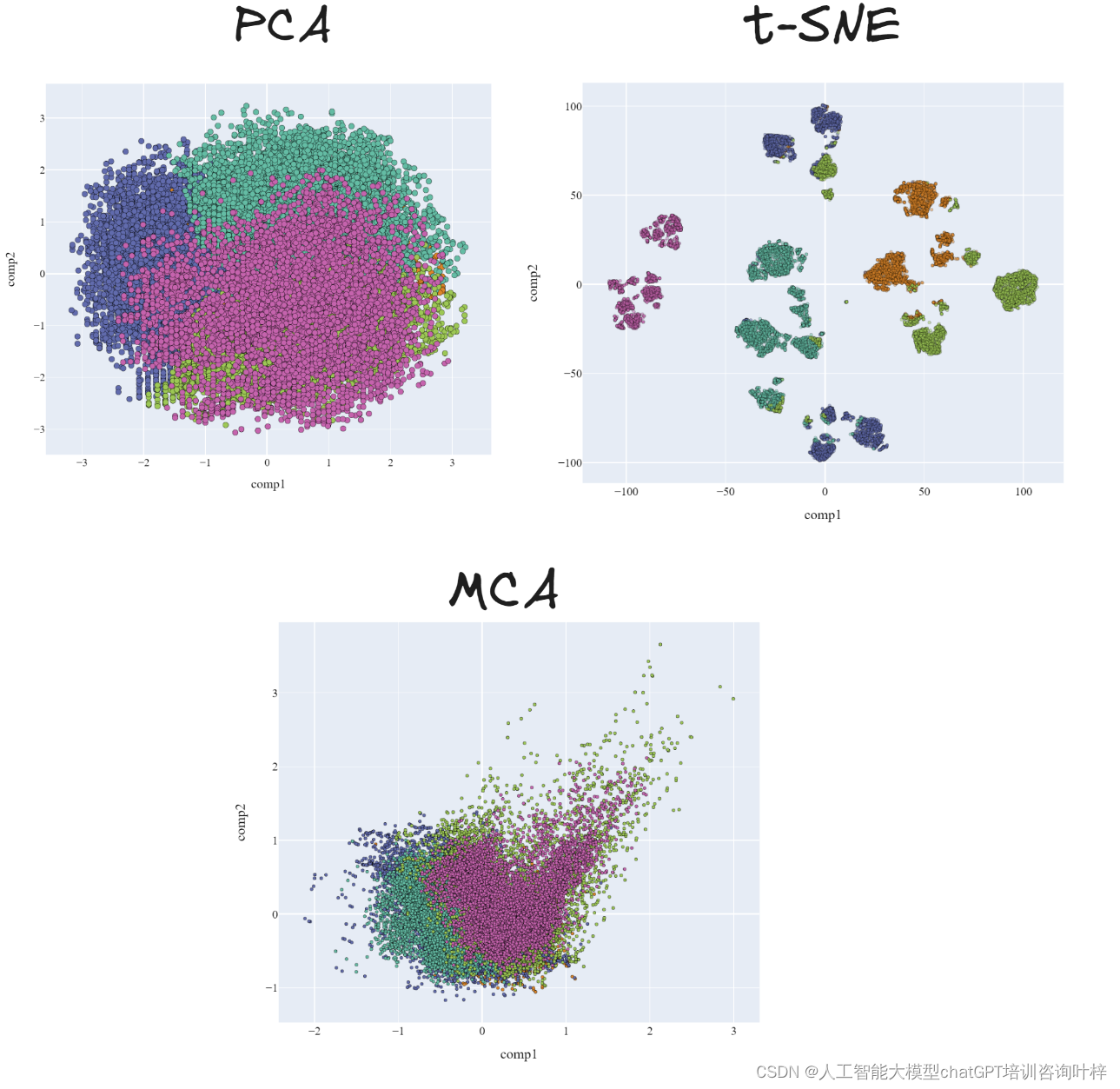
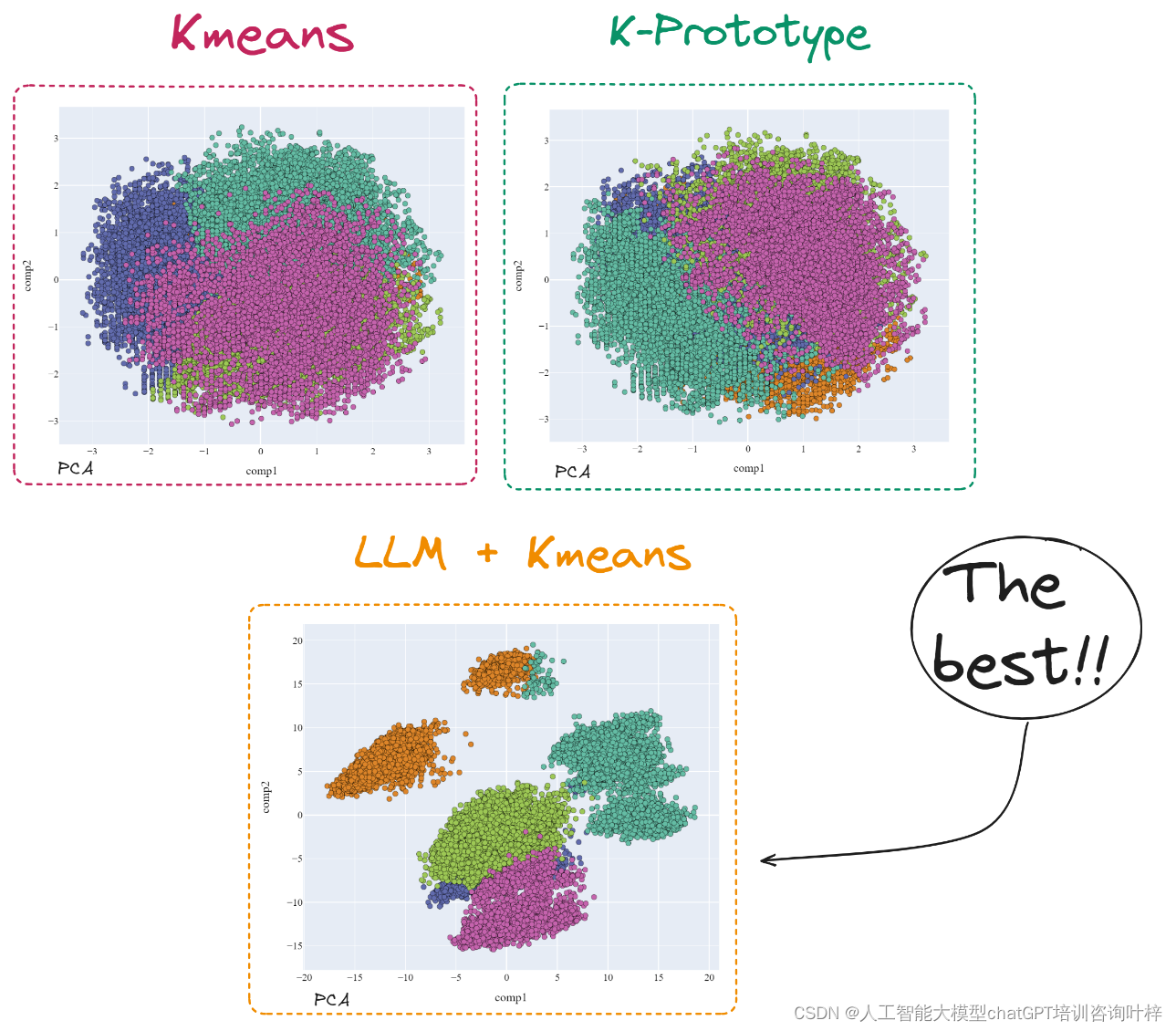 此外,项目还提供了使用PCA(主成分分析)、t-SNE(t分布随机邻域嵌入)和MCA(多重对应分析)等降维技术的结果,以及不同模型的2D表示(PCA)的比较。
此外,项目还提供了使用PCA(主成分分析)、t-SNE(t分布随机邻域嵌入)和MCA(多重对应分析)等降维技术的结果,以及不同模型的2D表示(PCA)的比较。
数据集
项目使用了来自Kaggle的公开数据集“Banking Dataset - Marketing Targets”。数据集的每一行都包含了公司客户的信息,包括数值和分类字段。项目特别关注数据集的前8列,包括年龄、工作类型、婚姻状况、教育水平、信用违约、年均余额、住房贷款和个人贷款等。
项目结构
项目的目录结构如下所示:
clustering_llm
├─ data
│ ├─ data.rar
├─ img
├─ embedding.ipynb
├─ embedding_creation.py
├─ kmeans.ipynb
├─ kprototypes.ipynb
├─ README.md
└─ requirements.txt其中,data.rar压缩文件包含了原始的训练数据集train.csv和经过嵌入处理后的embedding_train.csv。
方法详解
- K-means方法:在名为
kmeans.ipynb的Jupyter笔记本中,可以找到完整的K-means聚类过程。 - K-Prototype方法:在名为
kprototypes.ipynb的Jupyter笔记本中,可以找到创建混合特征聚类的方法。 - LLM + K-means方法:在名为
embedding.ipynb的Jupyter笔记本中,可以找到如何应用LLM以在聚类项目中获得卓越结果的详细说明。
注意事项
值得注意的是,该项目不包括探索性数据分析(EDA)阶段或变量选择,而这些步骤在此类项目中是至关重要的。
通过这个项目,数据科学家们不仅能够学习到如何应用高级聚类技术,还能了解到如何使用大型语言模型来增强聚类分析的准确性。如果你对客户细分或聚类分析感兴趣,这个GitHub仓库是一个宝贵的资源。
项目地址:https://github.com/damiangilgonzalez1995/Clustering-with-LLM



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











