







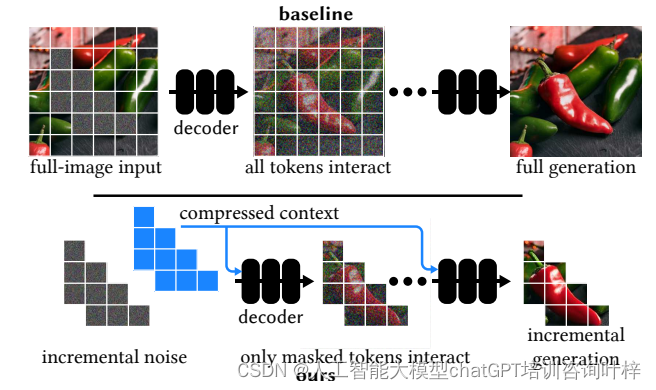
Adobe Research和特拉维夫大学的研究人员联合开发了一种名为LazyDiffusion的新型扩散变换器,它能够高效地生成部分图像更新,特别适用于交互式图像编辑。该模型通过创新的编码器-解码器架构,显著提升了图像编辑的效率,同时保持了与全尺寸图像生成相媲美的质量。
技术突破:
LazyDiffusion的核心在于两个阶段的工作流程:首先,上下文编码器处理当前画布和用户遮罩,生成一个紧凑的全局上下文;其次,扩散解码器基于这个上下文“懒惰”地合成遮罩像素,即仅生成遮罩区域的像素。这种方法避免了传统扩散模型在每次迭代中处理整个图像的需要,从而显著减少了计算量和时间。
上下文编码器(Context Encoder)
全局上下文生成:
- 上下文编码器的目的是将当前画布的全局信息和用户的编辑意图(通过遮罩定义)整合起来。
- 输入包括两部分:一是用户希望修改的图像区域(通过遮罩表示),二是遮罩外的背景或上下文区域。
- 编码器处理这两部分信息,生成一个包含整个图像上下文的紧凑表示,但重点是为遮罩区域生成内容。
信息压缩:
- 为了减少计算量,上下文编码器将丰富的图像信息压缩成一个较小的上下文码。
- 这个上下文码是编码器输出的一组特征或“tokens”,它们高效地编码了遮罩区域需要的全局信息。
- 通过这种方式,上下文编码器确保了后续的解码器只需要关注小范围的遮罩区域,而不是整个大尺寸的图像。
扩散解码器(Diffusion Decoder)
遮罩区域生成:
- 扩散解码器的任务是根据上下文编码器提供的全局上下文码来生成遮罩区域内的像素。
- 与传统的扩散模型不同,解码器不需要对整个图像进行迭代处理,而是只关注用户指定的遮罩区域。
- 这种“懒惰”的生成方式显著减少了不必要的计算,从而加快了图像编辑的速度。
迭代去噪:
- 扩散解码器采用迭代去噪的方法,逐步精细化遮罩区域的像素。
- 在每次迭代中,解码器都会使用当前的上下文码来指导遮罩区域内像素的生成,确保新生成的像素与整体图像风格一致。
- 这个过程从一个噪声图像开始,逐步去除噪声,直到生成高质量的图像内容。
LazyDiffusion模型在计算效率方面的显著提升,主要得益于其对遮罩大小的依赖性以及上下文编码器的一次性编码特性。在传统的扩散模型中,每次迭代都需要处理整个图像,这不仅增加了计算负担,也延长了处理时间。与之相对,LazyDiffusion的解码器仅针对用户定义的遮罩区域进行像素生成,这意味着运行时间与遮罩区域的大小成正比,而非整个图像的尺寸。对于局部编辑任务,这种设计大幅减少了不必要的计算,使得模型能够快速响应用户的编辑需求。
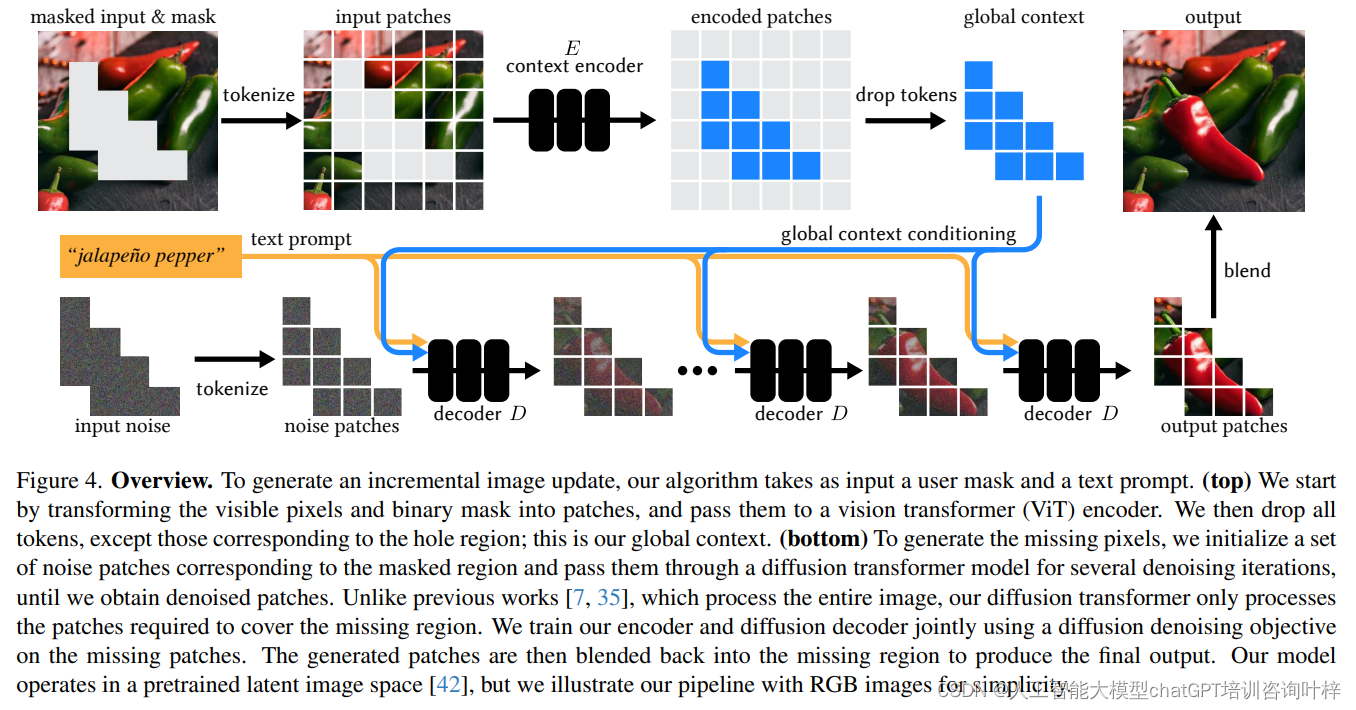
上下文编码器的设计也极大优化了计算过程。该编码器一次性处理整个图像和遮罩,生成一个紧凑的全局上下文,之后在多次迭代中复用这一上下文,避免了对同一图像重复编码的需要。这种设计不仅提高了计算效率,还减少了内存占用和整体的计算延迟。
LazyDiffusion通过智能地压缩和利用图像上下文信息,以及仅对图像的特定区域进行迭代处理,实现了计算效率的大幅提升。这使得模型特别适合于交互式图像编辑,为用户提供了接近实时的反馈和高度灵活的编辑体验。在图像编辑领域,尤其是在需要快速迭代和精细调整的场景中,LazyDiffusion展现了其巨大的潜力和应用价值。
实验与结果
实验设置 (Experimental Setup)
-
数据集: 研究人员使用了一个内部数据集,包含2.2亿张高质量的1024×1024分辨率的图像。这些图像涵盖了多种对象和场景,为模型提供了丰富的训练材料。
-
掩码和文本提示生成: 采用实体分割模型对图像中的每个对象进行分割,并使用BLIP-2为每个实体生成描述性文本。为了模拟用户创建的粗糙和不准确的掩码,研究人员对实体掩码进行了随机膨胀处理。
-
基线比较: 将LazyDiffusion与两种图像修复基线方法进行比较,分别是RegenerateImage和RegenerateCrop。RegenerateImage处理整个图像,而RegenerateCrop仅处理掩码周围的紧凑区域。
推理时间 (Inference Time)
-
性能对比: 研究人员展示了LazyDiffusion与基线方法在推理时间上的性能对比。LazyDiffusion的运行时间与掩码的大小成比例,而基线方法则在固定大小的张量上运行,导致LazyDiffusion在处理小掩码时具有显著的速度优势。
-
速度提升: 在掩码覆盖图像10%的情况下,LazyDiffusion实现了比RegenerateImage快10倍的速度提升。
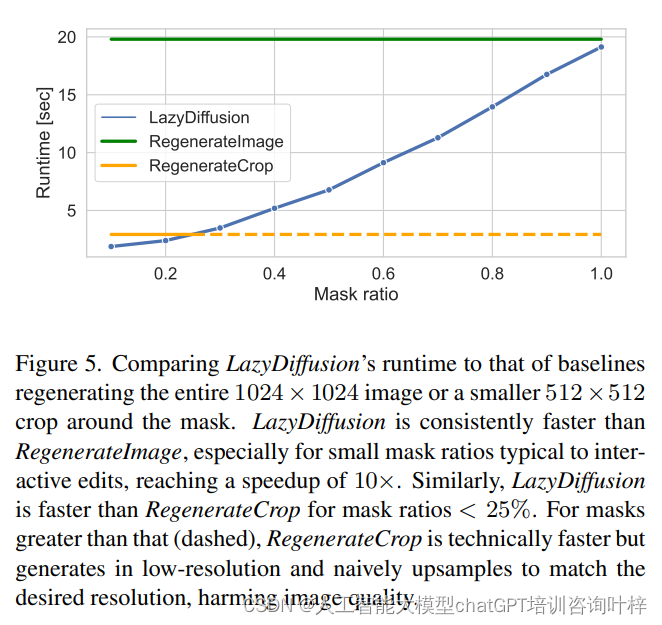
逐步生成 (Progressive Generation)
-
交互式编辑: LazyDiffusion显著加快了局部图像编辑的速度,使得扩散模型更适合于用户参与其中的交互式应用。
-
生成示例: 论文中展示了LazyDiffusion在图像编辑和生成中的迭代过程,从空白画布开始,逐步添加图像内容。
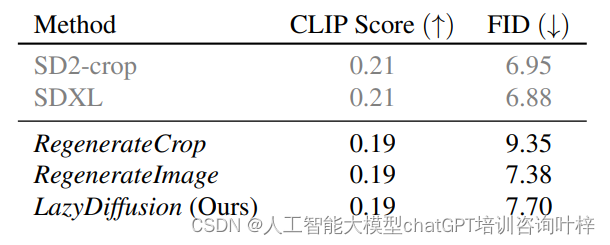
图像修复质量 (Inpainting Quality)
-
定量评估: 使用零样本FID(Fréchet Inception Distance)和CLIPScore进行定量评估,这些指标估计了图像与真实图像的相似度以及文本-图像对齐的质量。
-
用户研究: 通过用户研究评估模型在生成高度上下文相关的图像修复任务中的性能。用户在给定的掩码输入图像、文本提示和两种结果(LazyDiffusion和基线)中选择整体看起来最好的图像。
-
质量比较: LazyDiffusion在保持图像全局一致性的同时,即使在压缩上下文的情况下,也能产生与RegenerateImage和SDXL相当的修复结果。
草图引导的图像修复 (Sketch-guided Inpainting)
-
多样化条件: LazyDiffusion不仅依赖掩码和文本提示,还能适应其他形式的条件,如草图和边缘图。
-
灵活性展示: 论文中通过使用用户提供的粗略彩色草图来引导图像生成,展示了模型的灵活性。
实验结果证明了LazyDiffusion在交互式图像编辑任务中的有效性和效率,为未来的图像编辑工具和应用提供了新的可能性。
尽管LazyDiffusion在交互式图像编辑领域展现出巨大潜力,但研究人员也指出了一些局限性,例如在处理极高分辨率图像时可能遇到的挑战。未来的工作将致力于解决这些挑战,进一步提升模型的可扩展性和适用性。
论文链接:https://arxiv.org/abs/2404.12382
GitHub 地址:https://lazydiffusion.github.io/

















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











