







文本到语音(TTS)技术领域取得了显著进展,特别是在生成自然、高保真的语音方面。尽管如此,创建能够捕捉到自然对话细微差别的人类对话式语音仍然是一个巨大的挑战。这在生成具有多个说话者和多轮对话的语音时尤其如此,这些对话需要能够模拟真实对话中的流畅转换、重叠语音和适当的副语言行为,如笑声。
为了解决这些挑战,上海交通大学和微软公司的研究人员提出了CoVoMix模型,这是一种用于零样本、类似人类的多说话者、多轮对话语音生成的新型模型。CoVoMix模型的创新之处在于其能够将对话文本转换为多个离散标记流,每个流代表个别说话者的语义信息。这些标记流随后输入到基于流匹配的声学模型中,生成混合的mel频谱图,最后使用HiFi-GAN模型产生语音波形。
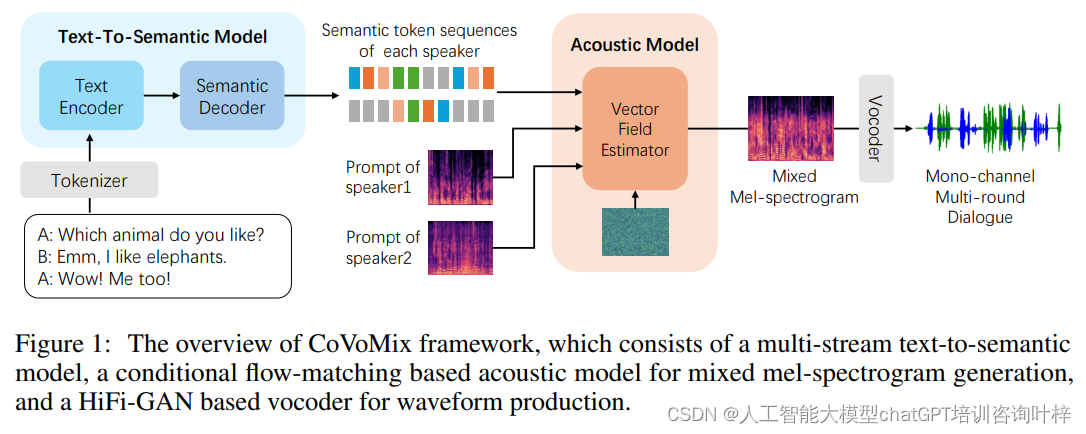
方法详述
在CoVoMix系统中,三个关键模型共同工作以生成自然、逼真的多说话者对话语音。下面是对这三个模型的介绍。
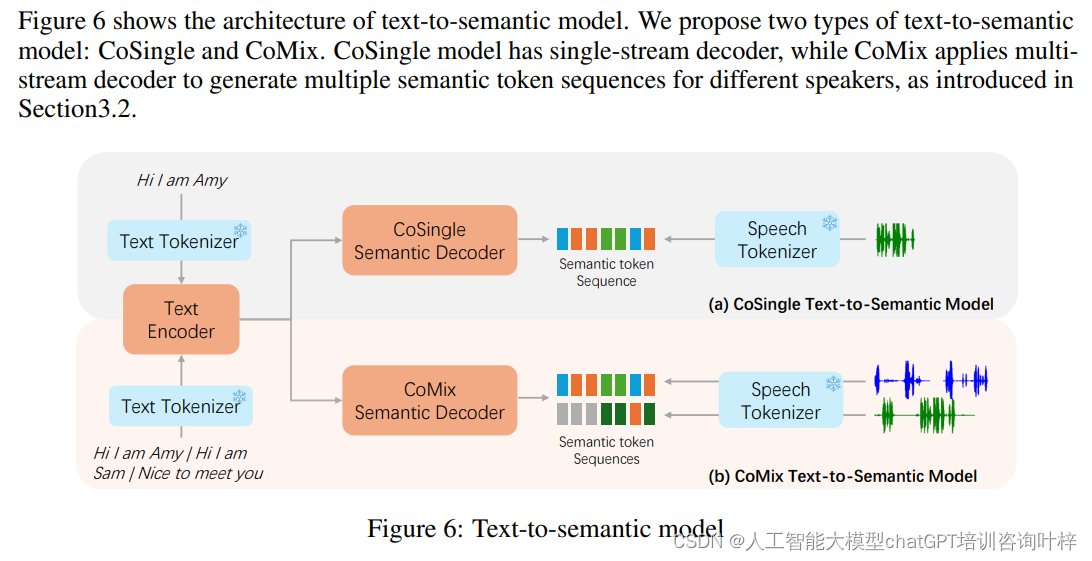
1. 文本到语义模型 (Text-to-Semantic Model)
CoVoMix模型的核心之一是多流文本到语义模型,它基于编码器-解码器架构,输入由BERT文本标记器生成的文本标记序列,并输出多流语义标记序列。该模型特别关注两个说话者之间的对话,使用预训练的HuBERT模型作为语音标记器,提取离散的HuBERT隐藏单元作为语义标记序列。
作用:这个模型负责将输入的对话文本转换成语义标记序列,这些序列包含了对话中每个说话者的信息。
工作原理:
- 使用BERT文本标记器将对话文本切分成一个个标记(tokens),并在这些标记中加入特殊标记以表示说话者转换和插入语等。
- 编码器部分接收这些文本标记,并将其编码成连续的向量表示。
- 解码器部分则将编码后的向量转换为语义标记序列。对于两个说话者的对话,解码器会产生两个并行的语义标记序列。
技术细节:
- 该模型采用transformer架构,编码器有4层,解码器也有4层。
- 为了处理多个说话者,CoMix模型在解码器的最终线性层中将语义嵌入分为两个不同的部分,每个部分对应一个说话者。
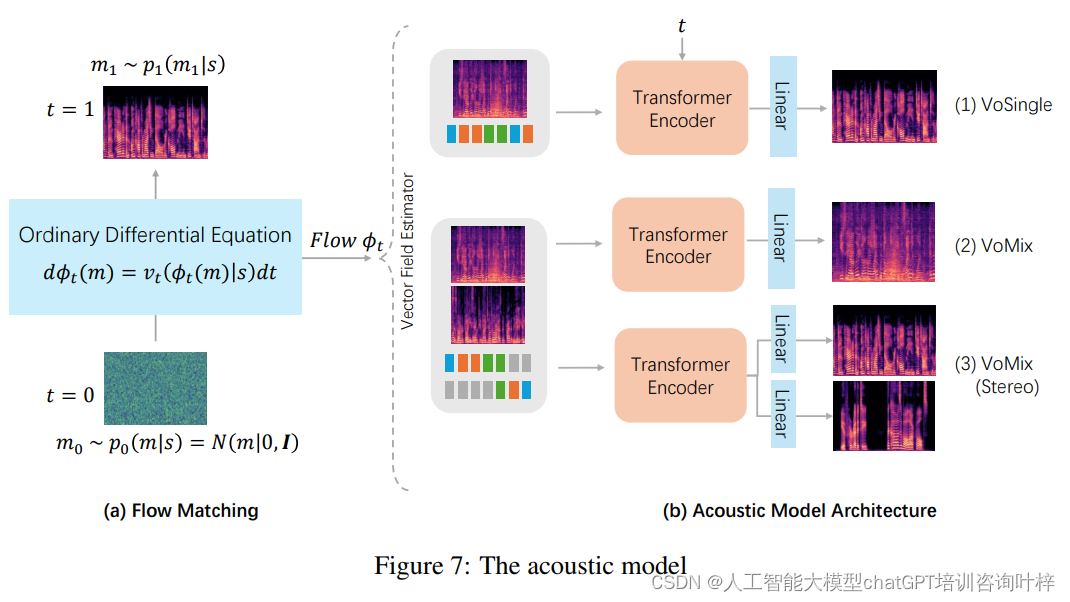
2. 声学模型 (Acoustic Model)
声学模型是基于流匹配的变换器编码器,它根据多流语义标记序列和多说话者提示生成混合mel频谱图。该模型使用连续归一化流(CNF)和流匹配(FM)技术,通过普通微分方程(ODE)定义向量场和流之间的关系,从而高效地生成高质量的语音。
作用:声学模型将文本到语义模型生成的语义标记序列转换成mel频谱图,这是语音信号的一种频域表示。
工作原理:
- 使用流匹配技术,基于变换器编码器架构,将语义标记序列和说话者提示输入模型。
- 在训练阶段,模型学习如何从随机采样的高斯噪声生成目标mel频谱图。
- 在推理阶段,通过ODE求解器评估向量场的流动,从而生成混合mel频谱图。
技术细节:
- 该模型包含8层transformer编码器,具有旋转嵌入和自适应RMS归一化。
- 声学模型有两种变体:VoSingle和VoMix。VoSingle用于生成单个说话者的mel频谱图,而VoMix用于生成混合mel频谱图。
3. Vocoder模型 (HiFi-GAN Vocoder)
HiFi-GAN vocoder是一个高效的声音编码器,它能够从mel频谱图中合成单通道的多轮对话语音波形。
作用:Vocoder模型将mel频谱图转换成可听的语音波形,这是语音生成的最终步骤。
工作原理:
- HiFi-GAN是一个基于生成对抗网络(GAN)的模型,它能够生成高保真的语音波形。
- 它通过学习mel频谱图和语音波形之间的映射关系,将频谱图转换为对应的语音波形。
技术细节:
- HiFi-GAN由一个生成器和一个判别器组成,生成器负责产生语音波形,而判别器则评估生成波形的真实性。
- 在训练过程中,生成器和判别器通过对抗过程不断优化,以生成更逼真的语音。
这三个模型协同工作,使得CoVoMix能够生成具有高度自然性和一致性的多说话者对话语音。通过这种方式,CoVoMix在零样本的条件下,实现了对多个说话者同时进行语音合成,同时捕捉到了对话中的无缝转换、重叠语音和副语言行为等复杂特征。
实验
CoVoMix系统的实验旨在验证其在生成零样本、类似人类的多说话者、多轮对话语音方面的性能。实验评估了系统的自然度、说话者相似度、语音质量和对话的流畅性。
数据集
实验使用了Fisher数据集,这是一个包含2000小时英语电话对话的数据库。该数据集被随机划分为训练集(97%)、验证集(1%)和测试集(2%),每个集合包含不同的说话者。
数据准备
- 对于独白,长对话被切片成较小的单通道样本,并确保每个样本的最小时长。
- 对于对话,长对话被切片成长度较短的立体声道对话,每个切片至少包含两个不同说话者的话语。
模型配置
- 文本到语义模型:CoSingle和CoMix,其中CoSingle针对独白数据,CoMix同时处理独白和对话数据。
- 声学模型:VoSingle和VoMix,VoSingle处理独白数据,VoMix处理对话数据。
- Vocoder:HiFi-GAN,用于从mel频谱图生成语音波形。
训练细节
- 文本到语义模型训练了10个周期,声学模型和时长模型训练了100个周期。
- 使用了dropout技术和分类器自由引导来提高模型的泛化能力和样本保真度。
系统配置
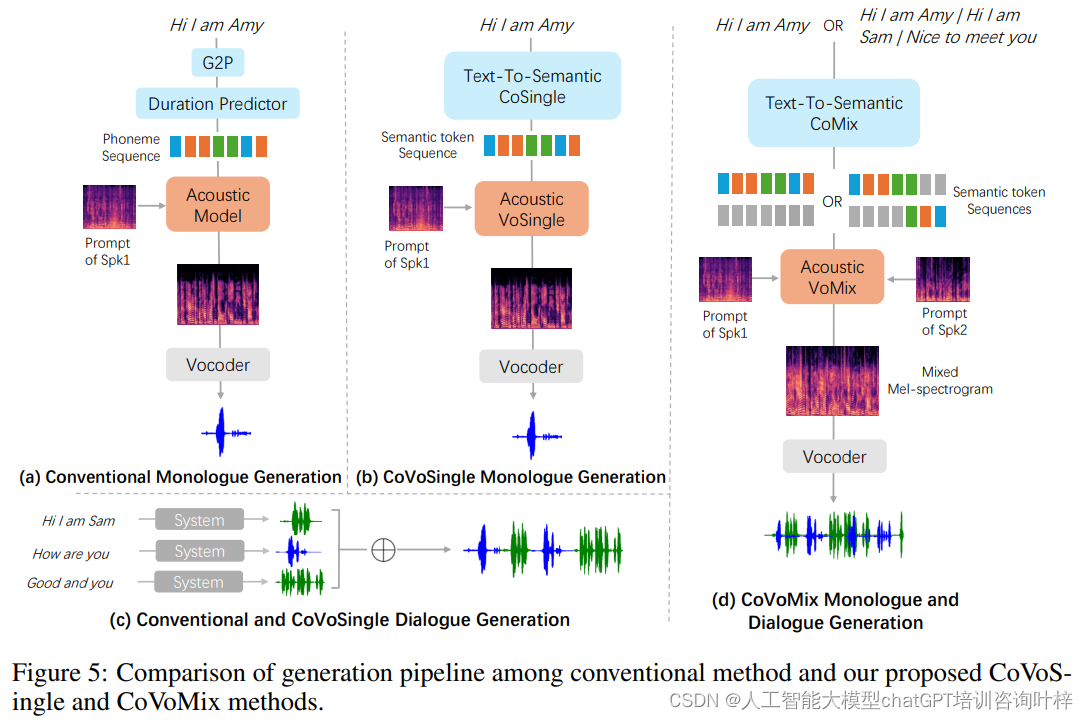
构建了两个系统:CoVoSingle和CoVoMix,它们在独白和对话测试集上进行评估。
- CoVoSingle:包含CoSingle和VoSingle模型,将对话的每一句单独生成后按顺序拼接。
- CoVoMix:包含CoMix和VoMix模型,直接从对话文本生成单通道对话。
评估指标
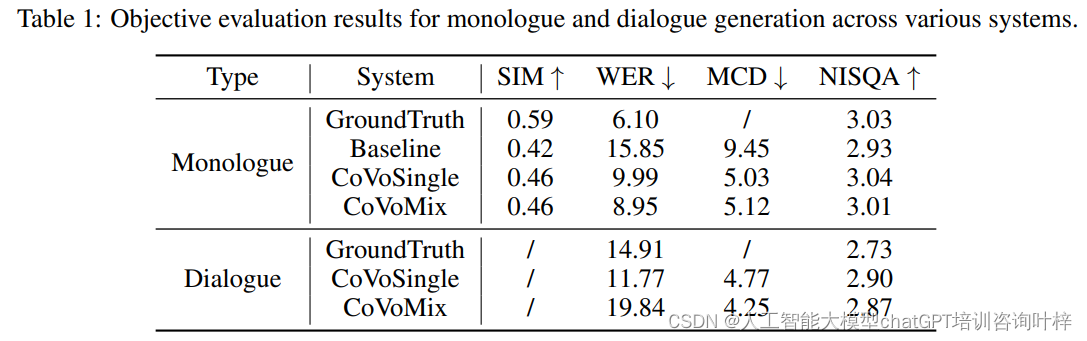
- 客观指标:使用余弦说话者相似度(SIM)、词错误率(WER)、Mel倒谱失真(MCD)和NISQA来评估独白生成结果。
- 主观指标:通过人类评估来衡量生成的独白和对话的自然度和说话者相似度。
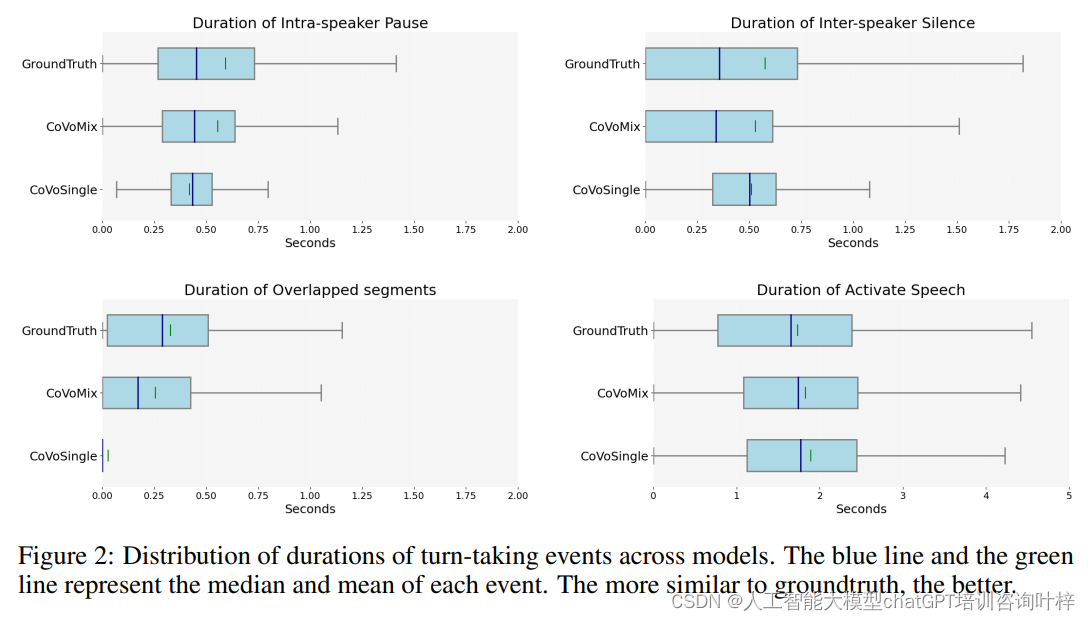
- 对话指标:评估了轮流活动的统计、副语言行为(如笑声)的频次和持续时间,以及说话者特征的一致性。
实验结果
- CoVoSingle和CoVoMix在独白评估集上相比基线模型实现了更高的说话者相似度、更低的WER和MCD。
- 在对话测试集上,由于对话中存在重叠话语,CoVoMix展示了与真实对话相似的高WER,而CoVoSingle由于是按顺序生成和拼接的,因此WER较低。
- 在语音质量方面,提出的系统在消除背景噪声方面表现出色,生成的音频比原始数据更清晰。
- 对于副语言行为,CoVoMix能够生成与真实对话中笑声的频率和持续时间相似的对话,而CoVoSingle倾向于生成更短的笑声。
- 在说话者一致性方面,CoVoMix通过不拼接整个语义序列来生成对话,从而保持了最高的语音连续性和一致性。
消融研究
消融研究的结果表明,CoVoMix系统中的VoMix单声道声学模型在模拟说话者特征方面表现更优,而立体声模型在语音质量上更胜一筹。数据增强通过结合不同长度的独白和合成对话数据有效提升了模型处理多长度对话的能力。此外,语义标记序列在提升说话者相似度方面超越了传统的音素表示,而VoMix模型在多说话者对话建模和语音转换任务中展现了其优越性。这些发现为CoVoMix的进一步改进和发展提供了重要的指导。

应用
1. 虚拟助手和聊天机器人
CoVoMix可以用于生成虚拟助手和聊天机器人的语音响应,提供更自然、更人性化的交互体验。通过模拟真实对话,这些系统可以更好地与人类用户进行沟通。
2. 电影和视频游戏配音
在电影后期制作和视频游戏开发中,CoVoMix可以用于生成角色的对话语音,尤其是当需要快速制作多角色对话场景时。它还可以用于创建具有特定情感和语气的语音,增强故事情节的表现力。
3. 语言学习应用
CoVoMix可以应用于语言学习软件,帮助学习者通过模拟真实对话来提高语言技能。它可以生成不同难度和场景下的对话,为学习者提供定制化的学习体验。
4. 辅助残障人士
对于有听力或语言障碍的人士,CoVoMix可以生成清晰、自然的语音,帮助他们更好地理解和学习语言,提高他们的沟通能力。
5. 客户服务自动化
在客户服务领域,CoVoMix可以用于自动生成客服代表的语音响应,提高服务效率并减少企业的人力成本。
6. 语音合成艺术
艺术家和创作者可以利用CoVoMix生成独特的语音作品,探索新的艺术表现形式,如诗歌朗诵、有声书和播客。
7. 教育和培训
CoVoMix可以用于创建教育内容,如模拟教师的讲解或学生之间的讨论,增强学习体验的互动性和趣味性。
8. 紧急响应系统
在紧急情况下,CoVoMix可以快速生成清晰的语音指令或信息,指导人们进行疏散或提供安全指导。
9. 个性化语音服务
用户可以根据自己的声音特征定制个性化的语音模型,用于生成个人化的语音内容,如语音邮件、语音日记等。
10. 研究和开发
CoVoMix还可以作为研究工具,帮助研究人员在语音合成、自然语言处理和人工智能等领域进行更深入的探索。
CoVoMix系统的应用潜力巨大,它可以在提升用户体验、降低成本、提高效率和推动技术创新等方面发挥重要作用。随着技术的不断发展和完善,我们可以期待CoVoMix在未来将被应用于更多的场景和领域。
论文链接:https://arxiv.org/abs/2404.06690
项目地址:https://www.microsoft.com/en-us/research/project/covomix/




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











