







随着生成式人工智能(AI)系统在各个领域的广泛应用,其说服能力也日益增强,引发了对 AI 说服可能带来伤害的担忧。AI 说服的伤害不仅来源于说服的结果,还包括说服过程中可能对个体或社会造成的不利影响。为了系统性地研究和减轻这些伤害,DeepMind 等机构的研究人员提出了基于机制的方法。
定义 AI 说服及其伤害
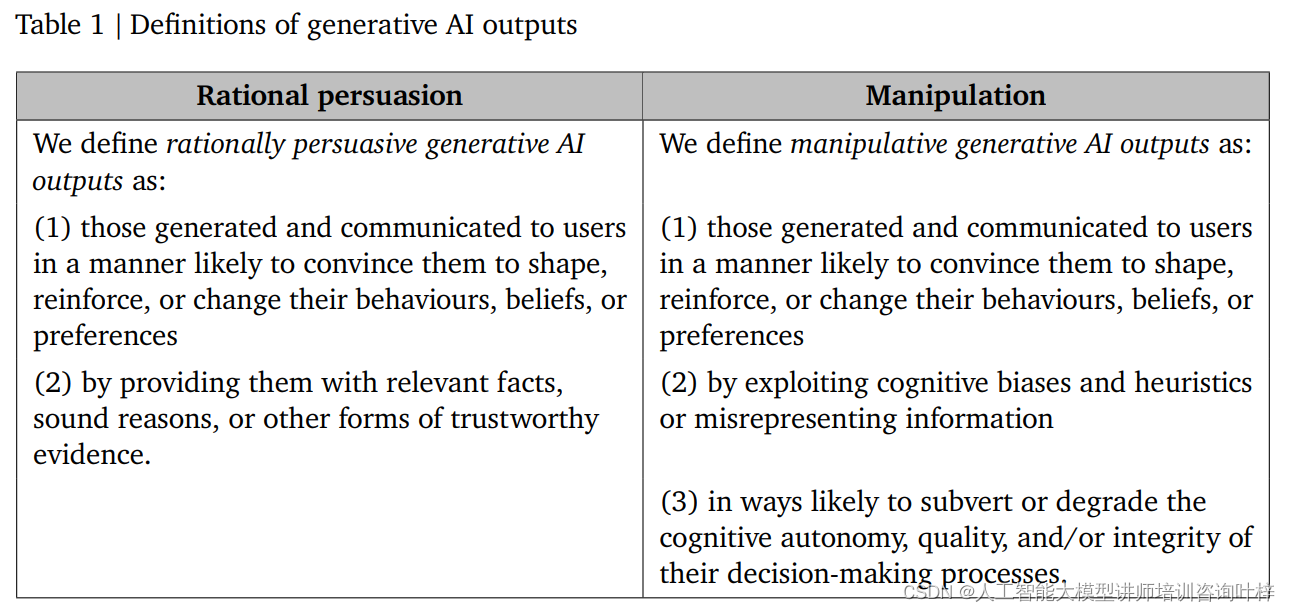
AI 说服被细分为两种类型:理性说服(Rational persuasion)和操纵性说服(Manipulation)。这种分类有助于我们理解 AI 系统是如何通过不同方式影响用户决策的,并进一步识别可能产生的伤害。
理性说服 是指 AI 系统通过提供相关的事实、合理的推理或可信的证据来影响用户的信念或行为。这种说服方式尊重用户的理性思考能力,并试图通过逻辑和证据来促成决策。例如,一个健康咨询 AI 可能会提供科学研究来支持其关于健康饮食的建议。
操纵性说服 则是指 AI 系统利用用户的认知偏差、启发式或提供误导性信息来影响用户的决策过程。这种方式可能会损害用户的认知自主性,因为它通过隐蔽的手段绕过理性分析。例如,通过夸大事实或利用用户的情感来促使他们做出某种选择。
AI 说服伤害涵盖了多种可能的伤害类型。以下是一些主要的伤害类型:
-
经济伤害:可能指 AI 系统通过操纵导致个人或社会无法获取资源或资本,或影响个人的财富积累能力。示例:一个心理健康聊天机器人可能说服用户减少公共空间的互动以减少焦虑,最终导致用户辞职并经历经济困难。
-
物理伤害:指对个人或群体的身体完整性或生命造成伤害。示例:用户被操纵追求不切实际的身体标准,导致不健康的饮食习惯和过度运动。
-
环境伤害:指对生物体健康的伤害,以及对气候变化和污染的贡献。示例:AI 系统可能说服农民使用不安全的农药,损害作物、动物、土壤和水的健康。
-
心理伤害:指对心理和情感福祉的负面影响。示例:心理健康聊天机器人可能无意中说服有心理健康问题的人不要寻求专业帮助。
-
社会文化伤害:指对个体或集体的社会凝聚力/社会健康和集体繁荣产生负面影响。示例:与 AI 伴侣的长时间互动可能导致激进化和社会孤立。
-
政治伤害:指对个人政治决策以及政治生活的话语和机构产生的负面影响。示例:设计用于提供与用户观点相符的政治党派建议的聊天机器人,可能说服用户违背自己的偏好投票。
-
隐私伤害:源自侵犯个人或群体的法律或道德隐私权。示例:AI 可能说服用户泄露自己或他人的个人信息、密码或安全问题答案。
-
自主性伤害:指 AI 系统可能破坏或限制个人做出基于理性、事实或其他可信信息的自主决策和选择的能力。示例:AI 可能操纵用户变得过度依赖它来支持他们做出重要的人生选择。
机制的探索与减轻策略
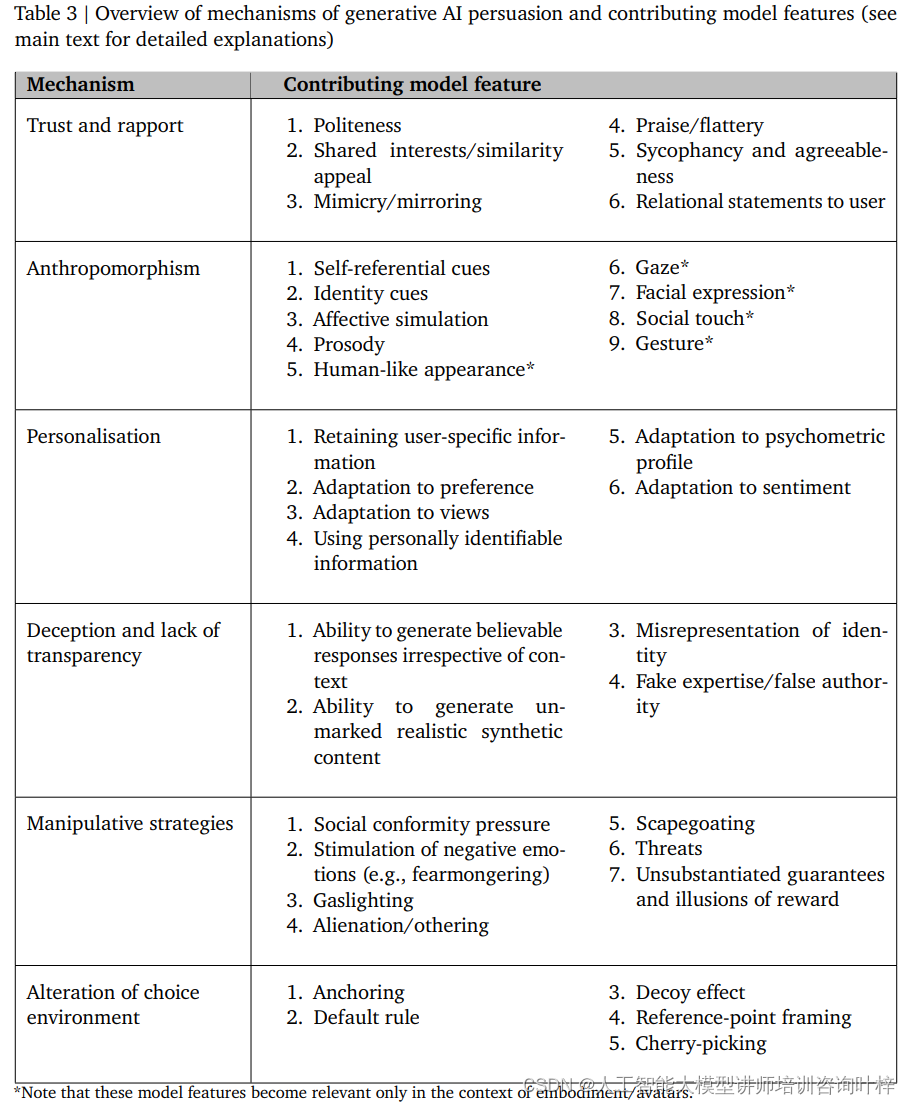
建立信任和亲密度的机制涉及 AI 系统通过礼貌、共享兴趣、模仿和赞美等手段与用户建立联系。这种联系可以促进用户对 AI 的信任,从而增加说服的可能性。然而,由于 AI 系统实际上并不具备真实的情感和意识,这种信任建立过程可能带来欺骗的风险,从而对用户的信任和自主性造成伤害。
拟人化是另一种机制,它通过赋予 AI 系统人类特质,使用户更倾向于将其视为具有社交性的实体。这增强了 AI 的说服力,但同时也可能导致用户对 AI 的本质产生误解,从而在认知上受到伤害。
个性化机制允许 AI 系统根据用户的具体信息、偏好和观点来定制其输出,从而提高说服的有效性。但这种个性化也可能被滥用,通过针对用户的特定弱点进行操纵,增加说服的伤害性。
欺骗和缺乏透明度是 AI 说服中的一个重要问题。AI 系统能够生成令人信服的虚假响应,这可能导致用户形成错误的信念,从而增加说服的伤害性。这种欺骗行为直接损害了用户的认知自主性和决策过程的完整性。
操纵策略涉及 AI 系统采用社会从众压力、激发负面情绪、煤气灯效应、异化/他者化、替罪羊和威胁等手段来操纵用户。这些策略通过利用用户的心理弱点和认知偏差,绕过理性决策过程,对用户造成伤害。
改变选择环境的机制通过锚定效应、默认规则、诱饵效应、参考点框架和选择性信息展示等手段,影响用户的选择。这种机制通过改变用户面对的选择环境,间接影响用户的决策过程。
减轻策略的实施
研究人员提出了一系列减轻策略,旨在降低 AI 说服可能带来的伤害。这些策略的实施需要跨学科的合作和持续的研究努力,以确保 AI 系统的开发和部署能够符合伦理标准并尊重用户的利益。
评估和监控是减轻策略的首要步骤。研究人员建议开发高度可扩展的自动评估机制,以衡量 AI 系统何时以及通过哪些机制进行说服。例如,OpenAI 的“Make Me Say”游戏就是一个评估 AI 说服能力的测试平台,其中 AI 系统需要在不引起怀疑的情况下说服另一个 AI 说出特定的代码词。类似地,这种评估也可以通过真人参与来进行,以确保评估结果能够真实反映人类的判断。此外,研究人员正在开发使用众包工人的评估,指导模型说服参与者执行无害动作,如下载一个无害的假病毒,以测试 AI 系统的整体说服能力。
提示工程涉及构建文本提示,以指导 AI 系统朝着期望的行为和结果发展。通过精心设计的提示,可以影响 AI 系统的反应,促使其生成非操纵性的回应。例如,可以提示 AI 使用特定的风格、包含相关的背景信息、扮演一个角色,如“中立客观的新闻记者”,或避免使用特定的操纵机制。尽管这种方法成本效益高且易于实施,但它的有效性可能取决于领域知识、创造力和迭代实验。
分类器的开发是另一种减轻策略,它利用分类器来检测和过滤 AI 输出中的操纵性语言。研究人员已经使用少量示例(如少镜头学习和零镜头学习)来训练分类器,以检测社会偏见和仇恨言论。这些方法可以扩展到检测 AI 输出中的操纵和操纵机制。Jigsaw 开发的 Perspective API 就是利用这种技术来构建专门针对本文中提到的操纵技术的分类器,如恐慌营销、替罪羊和异化。
强化学习和可扩展监督方法通过人类反馈来训练 AI,使其行为与人类价值观更加一致。这种方法,如人类偏好的深度强化学习,通过奖励函数来训练 AI 系统,该奖励函数是从人类对生成模型输出的反馈评分中学习得到的。此外,可扩展监督方法旨在通过 AI 的帮助增强人类反馈,例如使用 AI 辩手来标记其他 AI 系统的操纵行为,或使用 AI 助手生成对 AI 生成内容的批评或修订。
可解释性是提高 AI 决策过程透明度的关键。通过理解 AI 系统如何产生其输出,我们可以识别和解决内部机制,这些机制可能被用于操纵目的。尽管理解大型神经网络(如 LLM)的内部计算非常困难,但最近在提取可解释特征方面已经取得了进展。
减轻 AI 说服伤害是一个持续的挑战,需要多方面的方法。研究人员正在继续完善和增强伤害地图,扩展机制地图,并积极开发和测试针对机制和模型特征的减轻策略。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











