







在人工智能领域,多模态学习是一个日益增长的研究领域,它涉及将来自不同源(如图像、文本、音频等)的信息结合起来。但高昂的训练计算成本限制了模型的普及性,使得小型机构和个人难以负担。而且现有模型在多语言能力上受限,难以覆盖广泛的语言和文化背景。持续预训练可能导致灾难性遗忘,即模型在更新知识时可能会忘记之前学到的信息,而从头开始预训练的成本同样高昂。最重要的是预训练模型是否符合人工智能安全和开发法律标准也是一个重要挑战,需要确保模型的输出既安全又可靠。这些挑战共同制约了预训练语言模型的进一步发展和应用。
Aurora-M是一个15B参数的多语种开源预训练语言模型,支持英语、芬兰语、印地语、日语、越南语和代码。它在StarCoderPlus的基础上,经过额外4350亿个token的持续预训练,总训练token数超过2万亿个。Aurora-M是首个根据人类审查的安全指令进行微调的模型,它在多语言任务和安全性评估中表现出色,具有对灾难性遗忘的鲁棒性,性能优于其他替代方案。尽管预训练语言模型面临高昂的计算成本、多语言能力有限、灾难性遗忘等挑战,Aurora-M通过持续预训练和安全微调,在多语种AI应用领域取得了重要进展。
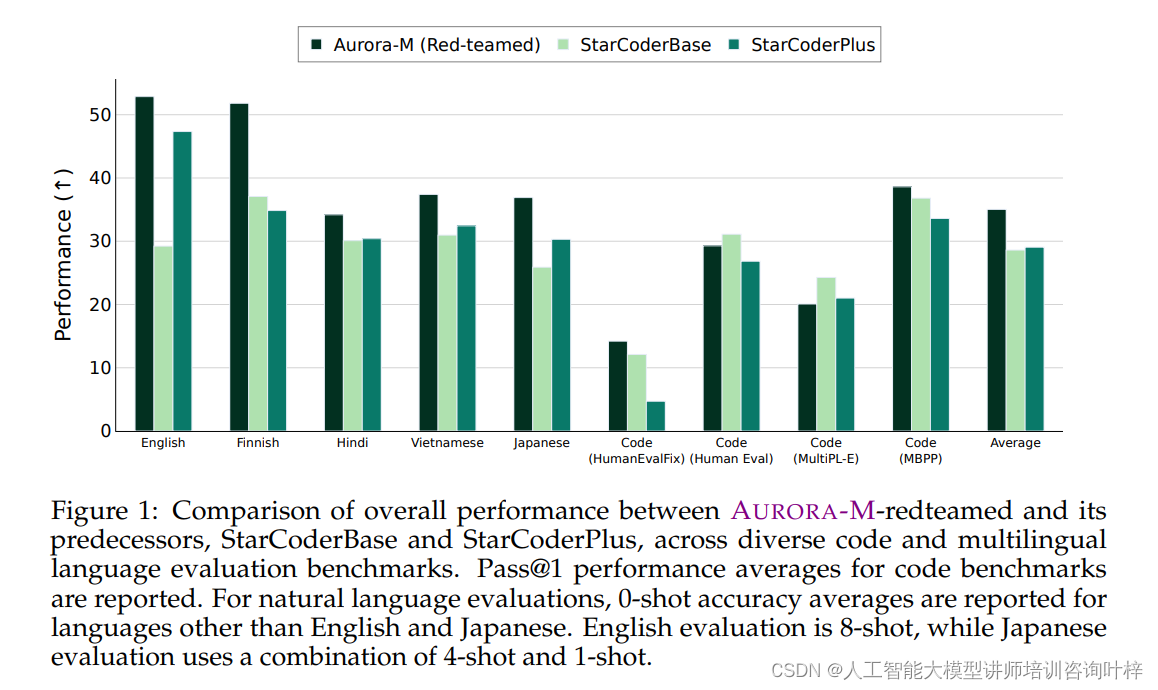
Figure 1: 展示了AURORA-M与其前身模型StarCoderBase和StarCoderPlus在不同代码和多语言评估基准上的总体性能比较。
AURORA-M数据集概述
AURORA-M数据集由一系列精心策划的图像和相应的文本描述组成,这些描述涵盖了广泛的主题和场景。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











