






翻译:“Entity Extraction from Resume using Mistral-7b for Knowledge Graphs” | by Tejpal Kumawat | Feb, 2024 | Medium[1]
在快速发展的自然语言处理(NLP)领域,从非结构化文本源中准确提取和分析信息的能力变得越来越重要。这种能力最具挑战性和相关性的应用之一就是处理简历以创建知识图谱。简历是密集而复杂的文档,包含大量有关应聘者职业经历、技能和资质的信息。然而,要准确有效地提取这些信息,需要先进的 NLP 技术。
这就是 "使用 Mistral-7b-Instruct-v2 for Knowledge Graphs 从简历中提取实体 "发挥作用的地方。Mistral-7b-Instruct-v2 是一种先进的语言教学模型,它通过识别和分类关键实体(如姓名、组织、职位名称、技能和教育详情),提供了一种创新的简历解析方法。通过利用 Mistral-7b 的指令功能,我们不仅可以高精度地提取这些实体,还能以有利于创建综合知识图谱的方式对它们进行结构化处理。
知识图谱可以组织和可视化实体之间的关系,提供数据的整体视图,这对招聘、人才管理和职位匹配等各种应用都有极大的价值。在本博客中,我们将深入探讨 Mistral-7b-instruct 如何改变简历分析流程、实体提取背后的技术基础以及从提取的数据中构建知识图谱的步骤。我们还将探讨这项技术对未来人力资源和招聘分析的潜在好处和影响。
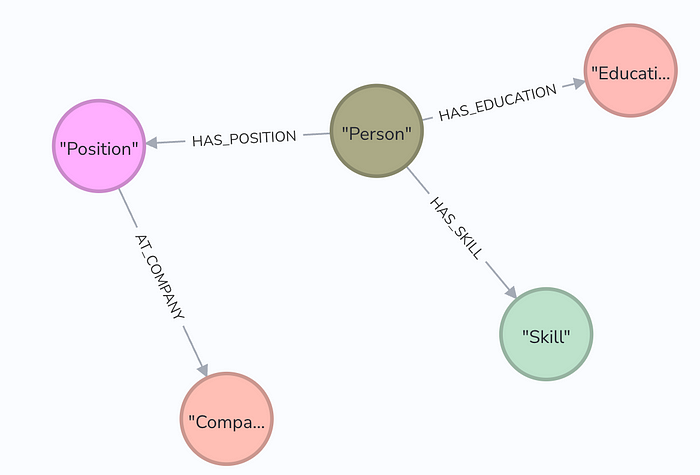
这就是典型的知识图谱:
None
由于数据隐私的原因,我们可能无法使用 openAI 或其他可用的 API。那么问题来了,我们该如何使用离线模型来准确地完成这项任务呢?
我们将使用 https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2,这是我们的用例模型。
我们将一步一步地从简历中获取相关实体。
第 1 步:从 PDF 或图片中提取文本。
我没有展示实现这一点的代码,但如果您有 PDF 文件,可以使用 Pymupdf;如果您有简历图片,可以使用 Pytesseract。
简历文本是我们的用例:
text="Developer <span class=\"hl\">Developer</span> Developer - TATA CONSULTANTCY SERVICE Batavia, OH Relevant course work† Database Systems, Database Administration, Database Security & Auditing, Computer Security,Computer Networks, Programming & Software Development, IT, Information Security Concept & Admin,† IT System Acquisition & Integration, Advanced Web Development, and Ethical Hacking: Network Security & Pen Testing. Work Experience Developer TATA CONSULTANTCY SERVICE June 2016 to Present MRM (Government of ME, RI, MS) Developer†††† Working with various technologies such as Java, JSP, JSF, DB2(SQL), LDAP, BIRT report, Jazz version control, Squirrel SQL client, Hibernate, CSS, Linux, and Windows. Work as part of a team that provide support to enterprise applications. Perform miscellaneous support activities as requested by Management. Perform in-depth research and identify sources of production issues.†† SPLUNK Developer† Supporting the Splunk Operational environment for Busine...OF COMMERCE - BANGKOK, TH June 1997 to May 2001 Skills Db2 (2 years), front end (2 years), Java (2 years), Linux (2 years), Splunk (2 years), SQL (3 years) Certifications/Licenses Splunk Certified Power User V6.3 August 2016 to Present CERT-112626 Splunk Certified Power User V6.x May 2017 to Present CERT-168138 Splunk Certified User V6.x May 2017 to Present CERT -181476 Driver's License Additional Information Skills† ∑††††SQL, PL/SQL, Knowledge of Data Modeling, Experience on Oracle database/RDBMS.† ∑††††††††Database experience on Oracle, DB2, SQL Sever, MongoDB, and MySQL.† ∑††††††††Knowledge of tools including Splunk, tableau, and wireshark.† ∑††††††††Knowledge of SCRUM/AGILE and WATERFALL methodologies.† ∑††††††††Web technology included: HTML5, CSS3, XML, JSON, JavaScript, node.js, NPM, GIT, express.js, jQuery, Angular, Bootstrap, and Restful API.† ∑††††††††Working Knowledge in JAVA, J2EE, and PHP.† Operating system Experience included: Windows, Mac OS, Linux (Ubuntu, Mint, Kali)"第二步:提取实体。
您可以使用 Google Colab 运行下面的代码,我使用的是 AWS 实例。
为了按照模式实现我们的提取目标,我将使用一系列提示链,每个提示链只关注一项任务--提取特定实体。通过这种方式,可以避免令牌限制。同时,提取的质量也会很好。
必要的库:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM下载模型:
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True,
torch_dtype=torch.float16,
# load_in_8bit=True,
# load_in_4bit=True,
device_map="auto",
use_cache=True,
)设置 Langchain 和配置模型
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
from transformers import AutoTokenizer, TextStreamer, pipeline,LlamaForCausalLM,AutoModelForCausalLM
from langchain import HuggingFacePipeline, PromptTemplate
DEVICE = "cuda:0" if torch.cuda.is_available() else "cpu"
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
text_pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=5000,
do_sample=False,
repetition_penalty=1.15,
streamer=streamer
)
llm = HuggingFacePipeline(pipeline=text_pipeline, model_kwargs={"temperature": 0.1})现在我们可以使用 LLM 了、
个人相关信息
提示
person_prompt_tpl="""From the Resume text for a job aspirant below, extract Entities strictly as instructed below
1. First, look for the Person Entity type in the text and extract the needed information defined below:
`id` property of each entity must be alphanumeric and must be unique among the entities. You will be referring this property to define the relationship between entities. NEVER create new entity types that aren't mentioned below. Document must be summarized and stored inside Person entity under `description` property
Entity Types:
label:'Person',id:string,role:string,description:string //Person Node
2. Description property should be a crisp text summary and MUST NOT be more than 100 characters
3. If you cannot find any information on the entities & relationships above, it is okay to return empty value. DO NOT create fictious data
4. Do NOT create duplicate entities
5. Restrict yourself to extract only Person information. No Position, Company, Education or Skill information should be focussed.
6. NEVER Impute missing values
Example Output JSON:
{{"entities": [{{"label":"Person","id":"person1","role":"Prompt Developer","description":"Prompt Developer with more than 30 years of LLM experience"}}]}}
Question: Now, extract the Person for the text below -
{text}
Answer:
"""这将帮助我们以 json 格式获取有关个人的信息,并使用我们显示的指令。
from langchain.chains import LLMChain
prompttemplate=PromptTemplate(template=person_prompt_tpl,input_variables=['text'])
chain=LLMChain(llm=llm,prompt=prompttemplate)
import time
t1=time.time()
result=chain(text)
t2=time.time()
print(t2-t1)输出 → 个人信息
{
"entities":[
{
"label":"Person",
"id":"developer1",
"role":"Developer",
"description":"Experienced developer with expertise in Java, JSP, JSF, DB2(SQL), LDAP, BIRT report, Jazz version control, Squirrel SQL client, Hibernate, CSS, Linux, and Windows. Has worked as a Splunk Developer supporting the Splunk Operational environment for Business Solutions Unit."
}
]
}这太棒了,我们在想要的表单中获得了关于此人的标签、身份、角色和描述。
2. 个人教育信息:
提示
edu_prompt_tpl="""From the Resume text for a job aspirant below, extract Entities strictly as instructed below
1. Look for Education entity type and generate the information defined below:
`id` property of each entity must be alphanumeric and must be unique among the entities. You will be referring this property to define the relationship between entities. NEVER create other entity types that aren't mentioned below. You will have to generate as many entities as needed as per the types below:
Entity Definition:
label:'Education',id:string,degree:string,university:string,graduationDate:string,score:string,url:string //Education Node
2. If you cannot find any information on the entities above, it is okay to return empty value. DO NOT create fictious data
3. Do NOT create duplicate entities or properties
4. Strictly extract only Education. No Skill or other Entities should be extracted
5. DO NOT MISS out any Education related entity
6. NEVER Impute missing values
Output JSON (Strict):
{{"entities": [{{"label":"Education","id":"education1","degree":"Bachelor of Science","graduationDate":"May 2022","score":"0.0"}}]}}
Question: Now, extract Education information as mentioned above for the text below -
{text}
Answer:
"""
from langchain.chains import LLMChain
prompttemplate=PromptTemplate(template=edu_prompt_tpl,input_variables=['text'])
chain=LLMChain(llm=llm,prompt=prompttemplate)
import time
t1=time.time()
result=chain(text)
t2=time.time()
print(t2-t1)产出 → 有关个人的教育情况:
{
"entities": [
{
"label": "Education",
"id": "education1",
"degree": "Master of Science in Information Technology",
"university": "KENNESAW STATE UNIVERSITY",
"graduationDate": "May 2015"
},
{
"label": "Education",
"id": "education2",
"degree": "Master of Business Administration in International Business",
"university": "AMERICAN INTER CONTINENTAL UNIVERSITY ATLANTA",
"graduationDate": "December 2005"
},
{
"label": "Education",
"id": "education3",
"degree": "Bachelor of Arts in Public Relations",
"university": "THE UNIVERSITY OF THAI CHAMBER OF COMMERCE",
"graduationDate": "May 2001"
}
]
}这真是令人难以置信,我们得到了包含个人所有教育信息的 json。
3. 个人技能信息
提示
skill_prompt_tpl="""From the Resume text below, extract Entities strictly as instructed below
1. Look for prominent Skill Entities in the text. The`id` property of each entity must be alphanumeric and must be unique among the entities. NEVER create new entity types that aren't mentioned below:
Entity Definition:
label:'Skill',id:string,name:string,level:string //Skill Node
2. NEVER Impute missing values
3. If you do not find any level information: assume it as `expert` if the experience in that skill is more than 5 years, `intermediate` for 2-5 years and `beginner` otherwise.
Example Output Format:
{{"entities": [{{"label":"Skill","id":"skill1","name":"Neo4j","level":"expert"}},{{"label":"Skill","id":"skill2","name":"Pytorch","level":"expert"}}]}}
Question: Now, extract entities as mentioned above for the text below -
{text}
Answer:
"""
from langchain.chains import LLMChain
prompttemplate=PromptTemplate(template=skill_prompt_tpl,input_variables=['text'])
chain=LLMChain(llm=llm,prompt=prompttemplate)
import time
t1=time.time()
result=chain(text)
t2=time.time()
print(t2-t1)输出 → 个人技能信息:
{
"entities":[
{
"label":"Skill",
"id":"skill1",
"name":"Java",
"level":"expert"
},
{
"label":"Skill",
"id":"skill2",
"name":"JSP",
"level":"expert"
},
{
"label":"Skill",
"id":"skill3",
"name":"JSF",
"level":"expert"
},
{
"label":"Skill",
"id":"skill4",
"name":"DB2",
"level":"intermediate"
},
{
"label":"Skill",
"id":"skill5",
"name":"Linux",
"level":"expert"
},
{
"label":"Skill",
"id":"skill6",
"name":"Windows",
"level":"intermediate"
},
{
"label":"Skill",
"id":"skill7",
"name":"SQL",
"level":"expert"
},
{
"label":"Skill",
"id":"skill8",
"name":"Oracle",
"level":"intermediate"
},
{
"label":"Skill",
"id":"skill9",
"name":"MySQL",
"level":"intermediate"
},
{
"label":"Skill",
"id":"skill10",
"name":"MongoDB",
"level":"beginner"
},
{
"label":"Skill",
"id":"skill11",
"name":"HTML5",
"level":"expert"
},
{
"label":"Skill",
"id":"skill12",
"name":"CSS3",
"level":"expert"
},
...id":"skill15",
"name":"JavaScript",
"level":"expert"
},
{
"label":"Skill",
"id":"skill16",
"name":"Node.js",
"level":"expert"
},
{
"label":"Skill",
"id":"skill17",
"name":"NPM",
"level":"expert"
},
{
"label":"Skill",
"id":"skill18",
"name":"GIT",
"level":"expert"
},
{
"label":"Skill",
"id":"skill19",
"name":"express.js",
"level":"expert"
},
{
"label":"Skill",
"id":"skill20",
"name":"jQuery",
"level":"expert"
},
{
"label":"Skill",
"id":"skill21",
"name":"Angular",
"level":"expert"
},
{
"label":"Skill",
"id":"skill22",
"name":"Bootstrap",
"level":"expert"
},
{
"label":"Skill",
"id":"skill23",
"name":"Restful API",
"level":"expert"
},
{
"label":"Skill",
"id":"skill24",
"name":"PHP",
"level":"intermediate"
},
{
"label":"Skill",
"id":"skill25",
"name":"SCRUM/AGILE",
"level":"expert"
},
{
"label":"Skill",
"id":"skill26",
"name":"WATERFALL methodologies",
"level":"expert"
}
]
}好了,我们以 Json 的形式获得了这个人的所有技能、
在这里,我们可以绘制如上图所示的知识图谱。
希望对你有用。















 58
58











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









