






转自:老朱读AI
1、介绍
LLaMA-Factory是一个开源平台,旨在为研究人员和开发者提供便捷的大型语言模型微调环境。通过LLaMA-Factory,用户可以轻松地加载预训练模型,调整模型参数,并在特定数据集上进行训练,从而优化模型性能。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。9月22日晚,实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
加助理微信:amliy007,29.9元即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory,关注享粉丝福利,限时免费CSDN听直播后的录播讲解。
LLaMA Factory 支持多种预训练模型和微调算法。它提供灵活的运算精度和优化算法选择,以及丰富的实验监控工具。开源特性和社区支持使其易于使用,适合各类用户快速提升模型性能。
2、特征
-
各种型号:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等。
-
集成方法:(连续)预训练、(多模态)监督微调、奖励建模、PPO、DPO、KTO、ORPO 等。
-
可扩展资源:通过 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 16 位全调谐、冻结调谐、LoRA 和 2/3/4/5/6/8 位 QLoRA。
-
高级算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ、PiSSA 和 Agent tuning。
-
实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
-
实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等。
-
更快的推理:带有 vLLM 工作器的 OpenAI 风格的 API、Gradio UI 和 CLI。
3、基准
与 ChatGLM 的P-Tuning相比,LLaMA Factory 的 LoRA 调优可将训练速度提高 3.7 倍,并在广告文本生成任务中获得更好的 Rouge 分数。通过利用 4 位量化技术,LLaMA Factory 的 QLoRA 进一步提高了 GPU 内存的效率。
4、定义
-
训练速度:训练过程中每秒处理的训练样本数量。(bs=4,cutoff_len=1024)
-
Rouge Score :广告文本生成任务开发集上的Rouge-2分数。(bs=4,cutoff_len=1024)
-
GPU 内存:4 位量化训练中的峰值 GPU 内存使用率。(bs=1,cutoff_len=1024)
-
我们采用pre_seq_len=128ChatGLM 的 P-Tuning 和lora_rank=32LLaMA Factory 的 LoRA 调优。
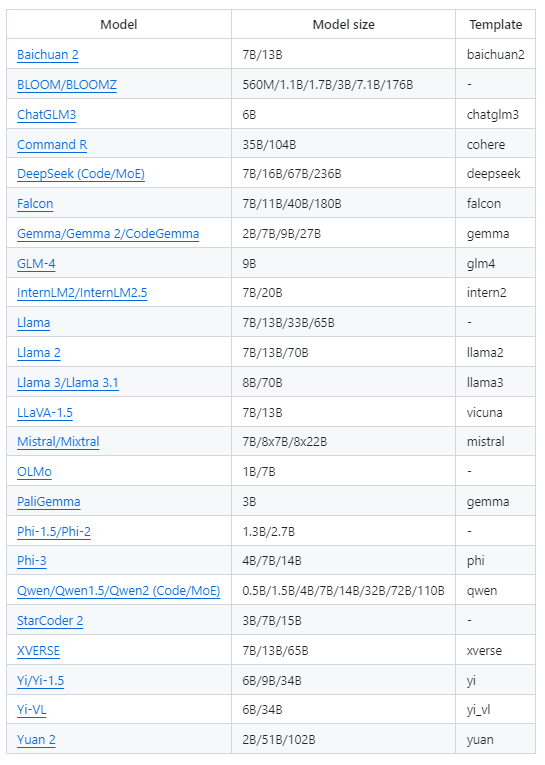
5、支持的模型
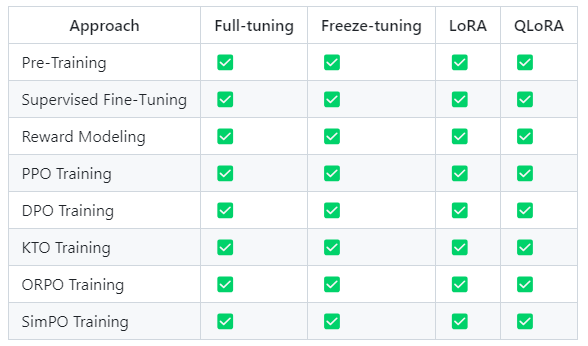
5、支持的训练方式
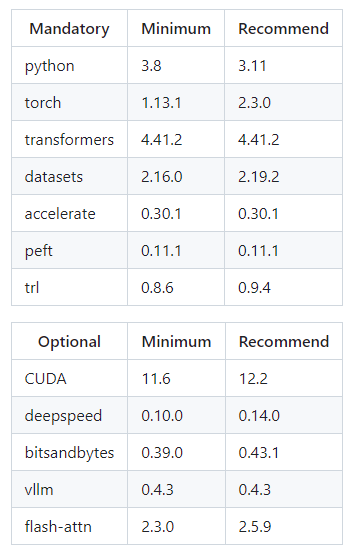
6、环境要求
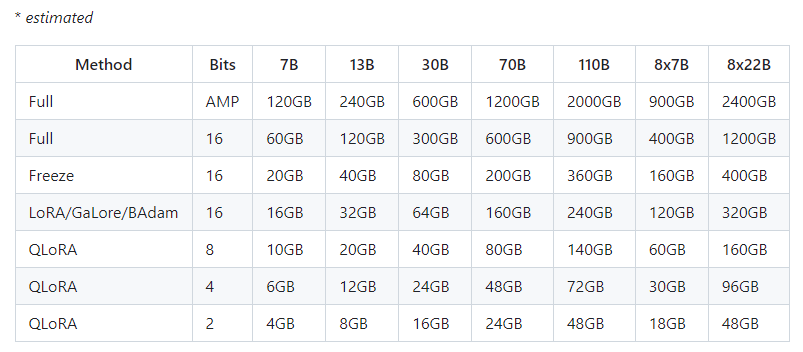
7、硬件要求
**番外篇**
在了解LLM微调工具之前,我们务必要对模型微调的相关概念具备一定程度的了解,以此辅助我们更好地LLM微调工具。
一、模型训练阶段
在深入理解模型微调的概念之前,我们先来明晰大模型训练阶段包含哪些内容。
Pre-Training(预训练阶段):此阶段用于训练基础模型,是最为消耗算力的阶段,也是大模型得以诞生的起始点。
Supervised Finetuning(SFT,指令微调/监督微调阶段):与预训练阶段相比,此阶段最大的转变在于训练数据从“量多质低”转变为“量少质高”,训练数据主要通过人工进行筛选或生成。在这个阶段完成后,实际上已经能够获取一个可以上线使用的大模型。
RLHF(基于人类反馈的强化学习,Rainforcement Learning from Human Feedback):它可以划分为两个环节。
奖励建模阶段(Reward Modeling):在这一阶段,模型学习和输出的内容发生了本质性的变化。在前两个阶段,即预训练和微调阶段,模型的输出是符合预期的文本内容;而在奖励建模阶段,其输出不仅涵盖预测内容,还包含奖励值或者评分值,数值越高,表明模型的预测结果越佳。这个阶段输出的评分,并非提供给最终的用户,而是在强化学习阶段发挥关键作用。
强化学习阶段(Reinforcement Learning):这个阶段十分“聪明”地整合了前面的成果:
针对特定的输入文本,通过 SFT 模型获取多个输出文本。
基于 RM 模型为多个输出文本的质量进行打分,此打分实际上已符合人类的期望。
基于这个打分,为多个输出文本结果添加权重。这个权重实际上会体现在每个输出 Token 中。
将加权结果反向传播,对 SFT 模型的参数进行调整,这便是所谓的强化学习。
常见的强化学习策略包含 PPO 与 DPO,它们的细节我们无需深究,只需知晓 DPO 主要应用于分布式训练,适用于大规模并行处理的场景,而 PPO 通常指的是单机上的算法即可。
做一个形象的类比,这四个阶段相当于人的求学之路:
-
预训练阶段,相当于是小学生
-
有监督微调阶段,相当于是中学生
-
奖励建模阶段,相当于是大学生
-
强化学习阶段,相当于是社会人
二、模型训练模式
在了解了模型训练阶段之后,随之而来的一个问题是,我们应当在哪个阶段开展微调训练呢?
通常会有以下训练模式供选择,依据领域任务、领域样本的情况以及业务的需求,我们能够挑选适宜的训练模式。
-
模式一:基于 base 模型 + 领域任务的 SFT;
-
模式二:基于 base 模型 + 领域数据 continue pre-train + 领域任务 SFT;
-
模式三:基于 base 模型 + 领域数据 continue pre-train + 通用任务 SFT + 领域任务 SFT;
-
模式四:基于 base 模型 + 领域数据 continue pre-train + 通用任务与领域任务混合 SFT;
-
模式五:基于 base 模型 + 领域数据 continue pre-train(混入 SFT 数据 + 通用任务与领域任务混合 SFT;
-
模式六:基于 chat 模型 + 领域任务 SFT;
-
模式七:基于 chat 模型 + 领域数据 continue pre-train + 领域任务 SFT
是否需要 continue pre-train
大模型的知识源自 pre-train 阶段,如果您的领域任务数据集与 pre-train 的数据集存在较大差异,例如您的领域任务数据来自公司内部,pre-train 训练样本基本无法覆盖到,那么必然要进行 continue pre-train。
倘若您的领域任务数据量庞大(token 在 1B 以上),并且仅追求领域任务的效果,不考虑通用能力,建议进行 continue pre-train。
是选择 chat 模型 还是 base 模型
假如您拥有一个出色的 base 模型,在 base 模型基础上进行领域数据的 SFT 与在 chat 模型上进行 SFT,效果方面的差异不大。
基于 chat 模型进行领域 SFT,极易导致灾难性遗忘,在进行领域任务 SFT 之后,模型的通用能力会降低,如果仅追求领域任务的效果,则无需考虑。
如果您的领域任务与通用任务存在很大的相关性,那么这种二阶段 SFT 会提升您的领域任务的效果。
如果您既追求领域任务的效果,并且期望通用能力不下降,建议选取 base 模型作为基座模型。在 base 模型上开展多任务混合训练时,需要关注各任务之间的数据配比。
其他经验
在资源许可的情况下,倘若只考虑领域任务效果,我会选择模式二;
在资源许可的情况下,若考虑模型的综合能力,我会选择模式五;
在资源不允许的情况下,我会考虑模式六;
一般而言,我们无需进行 RLHF 微调;
















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











