







转自:AI产品汇
项目主页-https://www.nexa4ai.com/
代码链接-https://github.com/NexaAI/octopus-v4
模型链接-https://huggingface.co/NexaAIDev/Octopus-v4
论文链接-https://arxiv.org/pdf/2404.19296.pdf
01-图语言模型背景
2024年4月,我们见证了最新的最强大的开源模型Meta的Llama3,其70B参数版本使用Groq实现了每秒约300个代币的惊人推理速度。此后不久,更强大的开源设备模型发布,包括微软的38亿参数的Phi-3-mini和苹果的OpenELM系列,参数范围从10亿到30亿。这些不同的模型迎合了各种用例,因此用户可以根据用例选择最佳模型。
图数据结构已经成为表示各个领域中复杂关系和依赖关系的强大工具。在计算机科学中,图由一组由边连接的节点(或顶点)组成,这些边可以是有向的,也可以是无向的。这种灵活的结构允许它可以用来表示使用线性或表格格式难以捕捉的复杂连接和层次结构。
与其它数据结构相比,图提供了一些优势,包括高效遍历、模式发现和对真实世界网络建模的能力。许多知名公司都利用基于图形的方法来增强其产品和服务。例如,Pinterest使用图形结构来表示用户、图板和图钉之间的关系,从而实现个性化内容推荐和提高用户参与度。类似地,Facebook和LinkedIn等社交网络依靠图形表示来建模用户连接,从而促进朋友建议和专业网络等功能。在集成开源语言模型的上下文中,可以使用图结构来表示不同模型之间的关系、它们的功能以及它们的最佳用例。通过将每个语言模型视为图中的一个节点,并根据它们的兼容性、互补性或特定任务的性能建立边缘,我们可以创建一个强大的框架,用于无缝模型集成、智能查询路由和优化性能。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具。9月22日晚,实战专家1小时讲解让您轻松上手,学习如何使用 Llama Factory 微调模型。
加助理微信提供直播链接:amliy007,29.9元即可参加线上直播分享,叶老师亲自指导,互动沟通,全面掌握Llama Factory,关注享粉丝福利,限时免费CSDN听直播后的录播讲解。
LLaMA Factory 支持多种预训练模型和微调算法。它提供灵活的运算精度和优化算法选择,以及丰富的实验监控工具。开源特性和社区支持使其易于使用,适合各类用户快速提升模型性能。
02-图语言模型简介
图片
自从ChatGPT、GPT-4等大语言模型的出现,便受到了大家的广泛关注。然而当前最具有价值的两个模型(OpenAI的GPT-4和Anthropic的各种模型)却是私有的,且并不开源。主要的原因是这些模型价格昂贵,消耗了大量的人力与物力资源,最起码要收回基础的成本才会考虑开源!
相比之下,开源社区已经产生了一些极巨竞争力的模型,例如:Llama3。此外,针对特定行业微调得到的行业语言模型,如为法律、医疗或金融任务量身定制的语言模型,其表现往往优于通用型大语言模型。
本文介绍了一种新的方法,该方法能够使用功能令牌来同时集成多个开源模型,而每个模型都针对特定任务进行了深度的优化处理。作者新开发的Octopus v4模型可以利用功能令牌智能地将用户的查询引导到一个最合适的行业大模型中,并重新格式化查询的问题从而获得最佳性能。
Octopus v4是在Octopus v1、v2和v3型号的大语言模型的基础上演变而来,擅长选择、参数理解和重新格式化等功能。此外,作者探索着将图作为一种通用的数据结构,通过利用Octopus模型和功能代币的功能,有效地协调多个开源模型。
03-图语言模型思路
图片
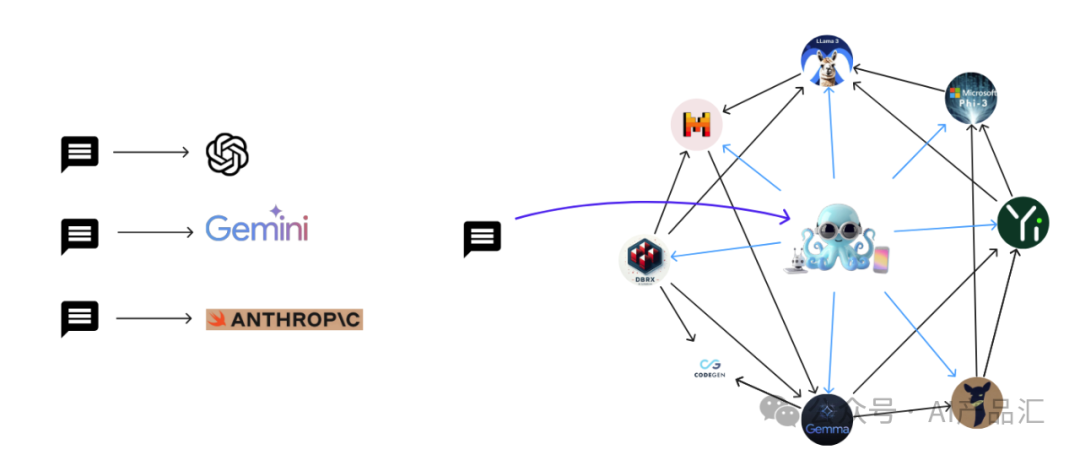
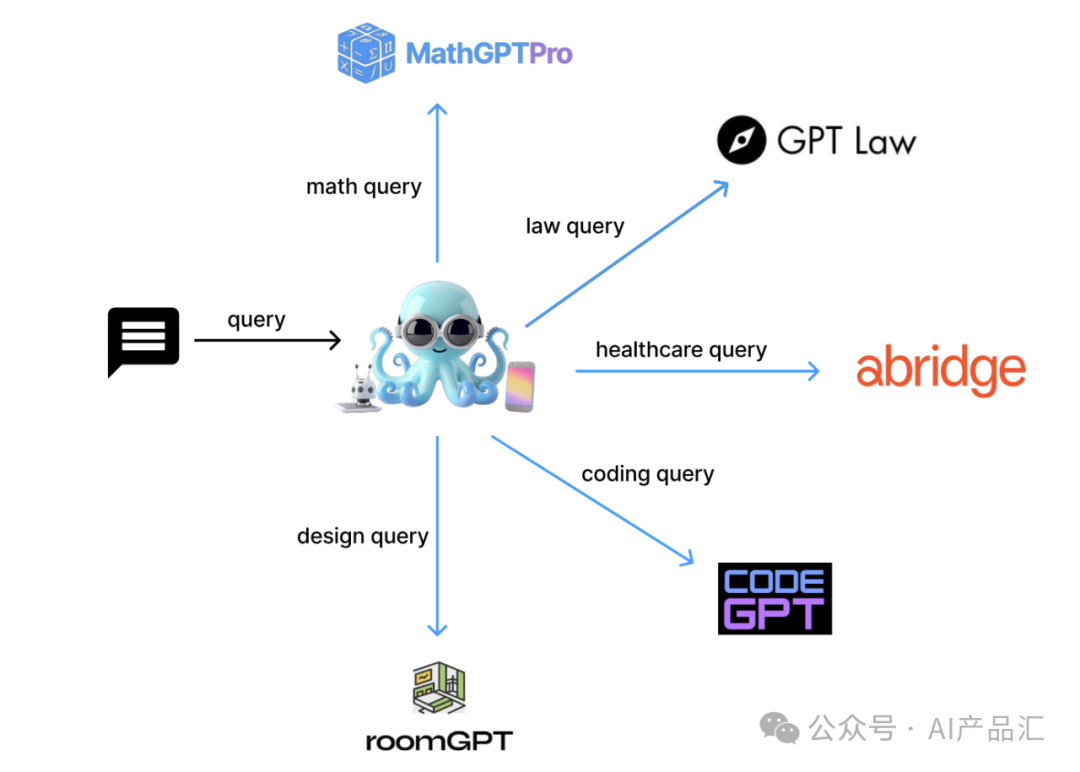
上图展示了Octopus模型的整体思路,最左边表示用户输入的query信息,中间的章鱼表示Octopus模型,MathGPTPro、LawGPT等是一个经过特定优化的行业语言模型。Octopus模型与其它行业大模型充当了图中的一些Node,不同的行业语言模型与Octopus模型之间的连接关系充当了图中的一些Edge,这样就组成了一个基础的图语言模型。
04-图语言模型流程
04.01-整体流程
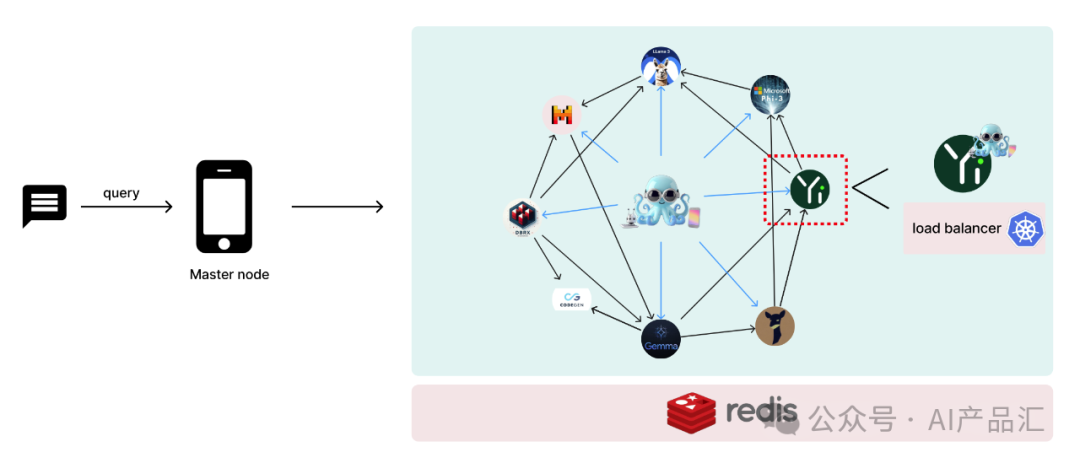
图片
上图展示了图语言模型的系统实现细节。该系统设计以图语言模型为特色,其中主节点部署在中央设备上面,工作节点分布在各种设备上。作者使用Kubernetes(k8s)对每个单独的行业型语言模型进行无服务器部署。
为了实现高效的数据共享,作者使用了Redis支持的分布式缓存机制。需要注意的是,对于每个工作节点,都有一个小的Octopus v4-Lora连接到它,用于在多代理用例的情况下指导下一个邻居节点。
其中每个节点代表一个语言模型,利用多个Octopus模型进行协调。在我们准备进行生产部署时,集成负载均衡器以有效管理系统需求是至关重要的。下面将详细介绍下整个系统的几个可管理的组件。
04.02-整体架构详解

图片
在作者的原始设计中,体系结构由两个抽象层组成。第一层使用功能令牌来表示可由Octopus v2模型执行的动作。该层包括三个不同的Octopus v2模型,每个模型都由不同的功能令牌标识,有效地将它们区分为单独的人工智能代理。第二层抽象属于Octopus v4模型,其中内部功能令牌被映射到各种v2模型。为了简单起见,上图只包括三个v2模型,但在实际用例中,一个模型可以映射到多个v2模型中。
05-图语言模型环境搭建与运行

图片
05.01-搭建运行环境
05.02-执行Demo
06-图语言模型性能评估
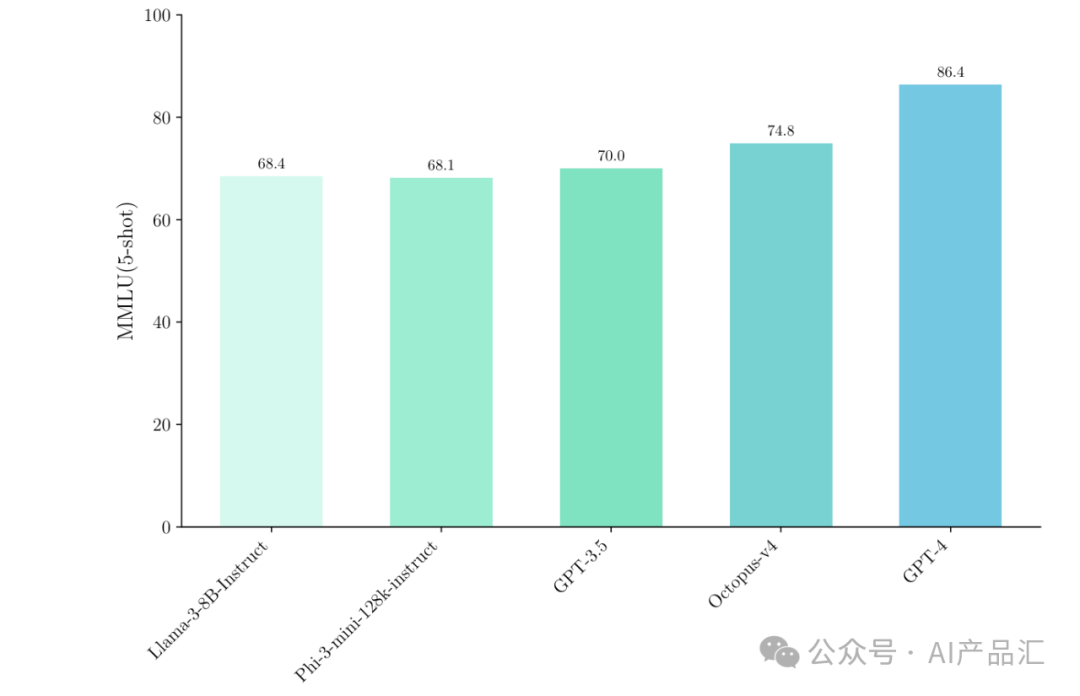
图片
上图展示了Octopus v4与其它的SOTA模型(Llama-3-8B、Phi-3-mini-128k、GPT-3.5、GPT-4)的MMLU指标比较结果。在Octopus v4的推理过程中,只有两个小的语言模型被激活,每个模型的参数都小于10B。通过观察与分析,我们可以得出以下的初步结论:只需要牺牲少量的代币,Octopus v4在MMLU得分方面超越了GPT-3.5,与GPT-4具有较小的差距。
07-图语言模型效果展示

图片
图7.1-图语言模型样例展示1
上图展示了该模型的一个样例结果。Query表示用户输入的问题,Response表示Octopus v4图语言模型的回答结果,其中nexa_4表示一个功能性token,它指向了一个行业大模型MathGPT,用该模型解决该问题更合适!
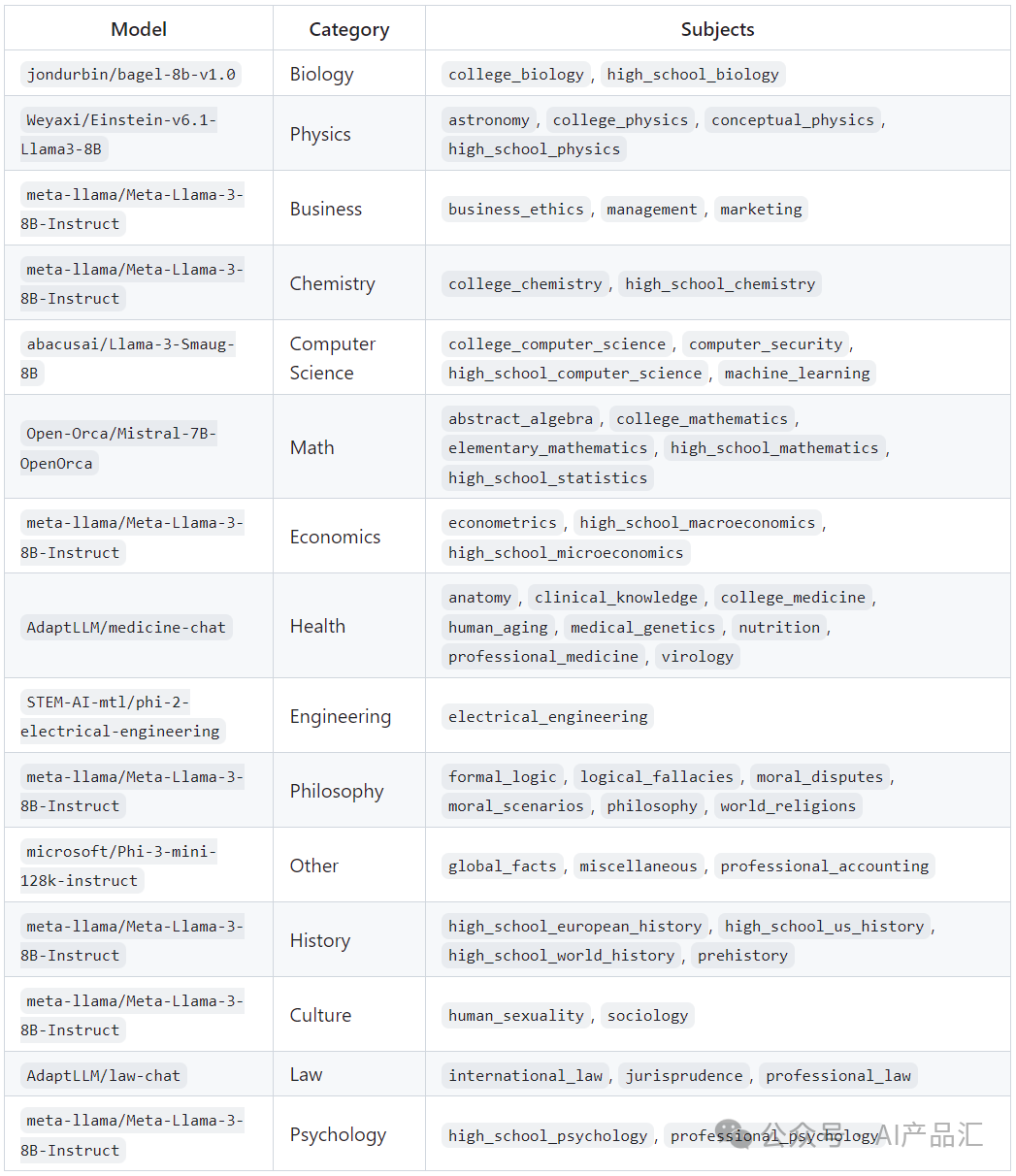
图片
图7.2-图语言模型当前支持的模型列表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









