









人工智能咨询培训老师叶梓 转载标明出处
人工通用智能(AGI)的过程中,语言智能体成为了一个新的研究热点。这些智能体是构建在大模型之上的,它们通过提示技巧和工具使用方法来处理现实世界中的复杂任务。然而,目前的研究和开发过程中存在一个根本性问题:这些智能体的进步依赖于大量的人工工程技术,而不是自动化地从数据中学习。
为了解决这个问题,AIWaves Inc.的研究人员提出了一个名为“智能体符号学习”的新框架。这个框架的核心思想是将语言智能体视为符号网络,其中可学习的权重由提示、工具以及它们如何组合来定义。通过模仿连接主义学习中的两个基本算法——反向传播和梯度下降——智能体符号学习使得语言智能体能够以数据为中心的方式自我优化。
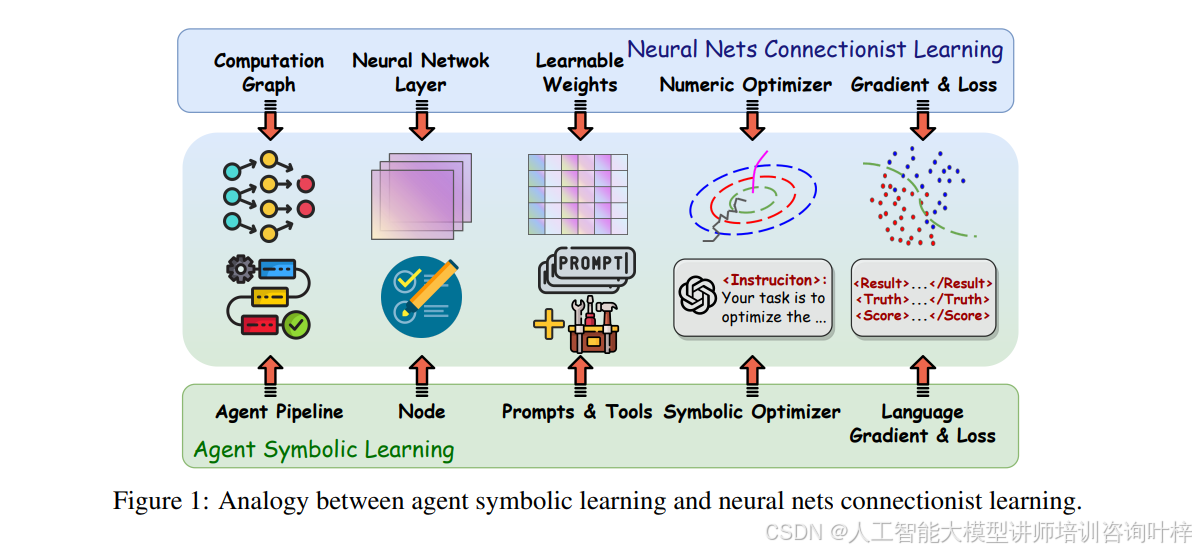
图1展示了智能体符号学习与神经网络连接主义学习之间的类比。在这种类比中,智能体的工作流程(Agent Pipeline)对应于神经网络的计算图,智能体流程中的节点(Node)对应于神经网络的层(Layer),而节点中的提示(Prompts)和工具(Tools)对应于神经网络层中的可学习权重。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
智能体符号学习
智能体符号学习这项技术的核心在于让语言智能体能够自我优化,就像神经网络通过训练学习一样。算法的核心是模仿神经网络训练中使用的连接主义学习过程,包括反向传播和基于梯度的权重更新。不过,这里的权重、损失和梯度都是用自然语言形式表示的。

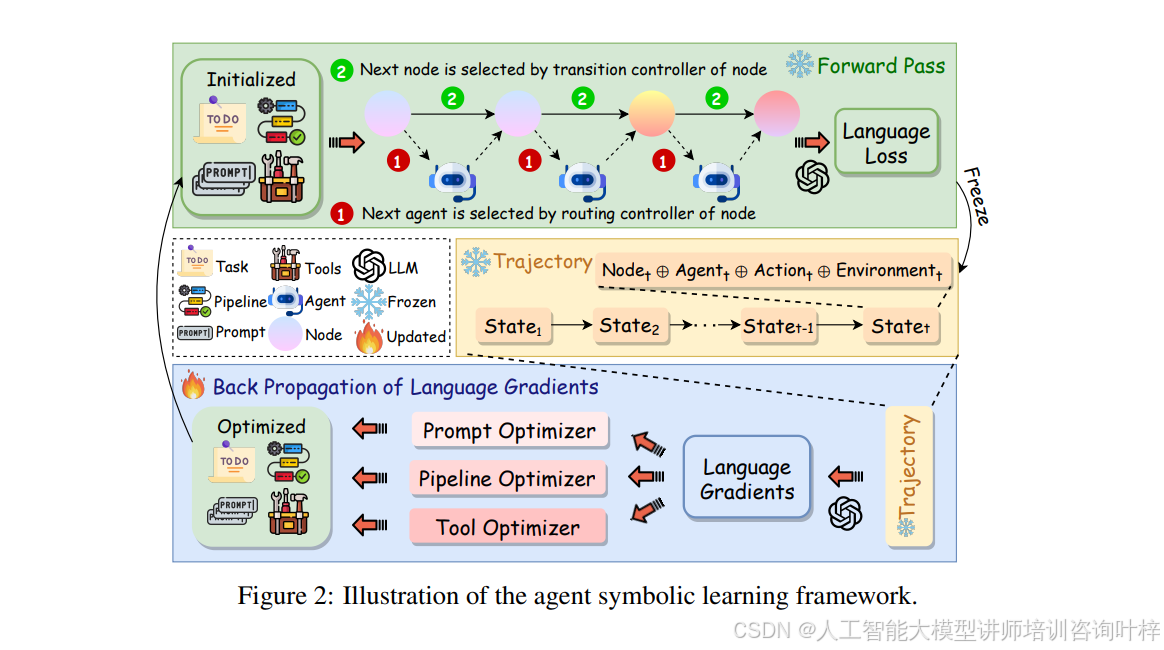 图 2 为智能体符号学习框架的直观视图。在这张图中,智能体被表示为一系列节点,这些节点通过管道连接,处理输入数据并生成输出。每个节点都利用大模型、提示(Prompts)和工具(Tools)来处理自然语言形式的输入,并产生自然语言形式的输出。
图 2 为智能体符号学习框架的直观视图。在这张图中,智能体被表示为一系列节点,这些节点通过管道连接,处理输入数据并生成输出。每个节点都利用大模型、提示(Prompts)和工具(Tools)来处理自然语言形式的输入,并产生自然语言形式的输出。
前向传递是智能体处理输入数据的过程。在这个阶段,智能体的每个节点接收输入,使用大模型、提示和工具生成输出,并将输入、输出、提示和工具使用情况记录到轨迹τ中。轨迹τ的作用类似于神经网络中的计算图,它存储了所有必要的信息,以便后续进行梯度反向传播。
损失计算阶段,通过将轨迹τ输入到大模型中,并使用一个精心设计的提示模板Ploss来计算语言损失Llang。这个损失是一个文本形式的评估,它衡量智能体的输出与预期结果之间的差异。这个损失既包括自然语言的评论,也包括一个数值分数,都是通过提示生成的。
接下来是梯度反向传播。这个过程从最后一个节点开始,反向遍历智能体的每个节点,使用大模型和提示Pgradient来计算每个节点的语言梯度∇nlang。这些语言梯度是文本形式的分析和反思,用于指导如何更新智能体的各个组件。这个过程类似于神经网络中的反向传播,但它处理的是文本形式的梯度而不是数值梯度。
最后是权重更新阶段。在这个阶段,使用所谓的“符号优化器”来更新智能体的提示、工具和管道。这些优化器是专门设计的提示管道,可以优化智能体的符号权重。优化器包括三种类型:PromptOptimizer用于优化提示,ToolOptimizer用于优化工具,PipelineOptimizer用于优化整个智能体管道。
批量训练是算法的另一个关键部分,它借鉴了小批量随机梯度下降的概念。在批量训练中,每个样本分别进行前向传递、损失计算和反向传播,然后对同一节点的一批语言梯度进行处理,提示大模型在更新智能体时综合考虑这些梯度。
整个智能体符号学习方法通过这种方式,使得智能体能够从数据中学习并自我进化,从而提高其在复杂任务中的表现。这种方法的一个关键优势是它能够避免局部最优,通过整体优化智能体的各个组件来提高整体性能。
实验
任务和数据集: 实验涉及了两类任务:标准的大模型基准测试和更复杂的智能任务。标准的大模型基准测试包括HotpotQA、MATH和HumanEval。HotpotQA是一个需要丰富背景知识的多跳问答任务,实验中使用了数据集中的“困难”部分,因为这对于语言智能体来说更具挑战性。MATH是一个包含具有挑战性的竞赛数学问题的集合。HumanEval是一个评估集,要求大模型或智能体根据文档字符串合成程序。对于评估指标,HotpotQA使用F1和精确匹配,MATH使用准确率,HumanEval使用Pass@1。
对于复杂的智能任务,考虑了创意写作和软件开发两个任务。在创意写作任务中,智能体被给定4个随机句子,并要求它们写出一个连贯的段落,每个段落以给定的句子结束。这个任务是开放式和探索性的,挑战创造性思维和高级规划。使用GPT-4评分来评估段落。软件开发任务则要求智能体系统根据简单的产品需求文档(PRD)开发可执行的软件。根据生成软件的可执行性来评估比较智能体,量化为1到4的数值分数,对应不同的执行能力水平。
基线比较: 实验中比较了几种方法,包括使用GPT和精心设计的提示的简单基线;使用Agents框架实现的语言智能体方法,也包括精心设计的提示、工具和管道;DSpy,一个可以搜索最佳提示组件组合的大模型管道优化框架;以及Agents + AutoPE,一个变体,其中智能体管道中每个节点的提示都由大模型优化。
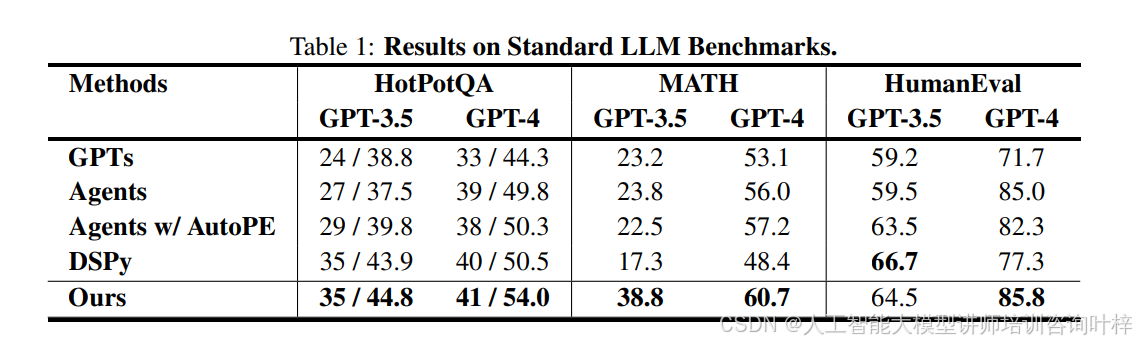
标准大模型基准测试结果: Table 1 显示了标准大模型基准测试的结果。提出的智能体符号学习框架在所有比较方法中一致地提高了性能。在MATH这个竞赛级基准测试中,性能提升尤其大。相比之下,传统的基于大模型的提示优化方法(Agents w/AutoPE)和基于搜索的提示优化方法(DSPy)在某些情况下可以提高性能,但在其他情况下会导致性能显著下降。这表明智能体符号学习框架更加稳健,可以更有效地优化语言智能体的整体性能。
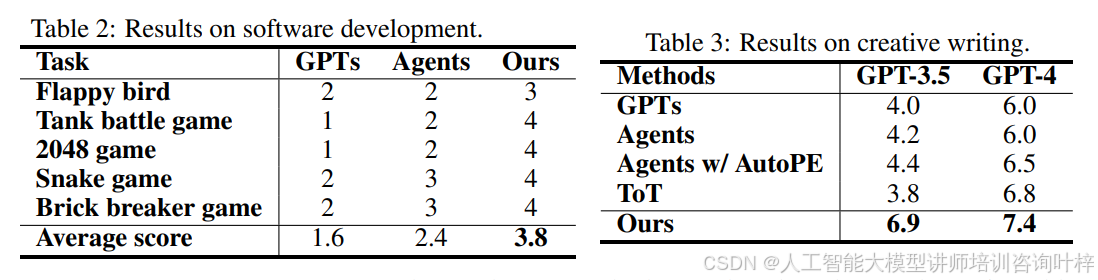
复杂任务结果: Table 2 和 Table 3 分别显示了软件开发和创意写作任务的结果。提出的方法在两项任务上都显著优于所有比较的基线,与常规大模型基准测试相比,性能差距更大。有趣的是,提出的方法甚至在创意写作任务上超过了ToT,这是一种精心设计的提示工程和推理算法。提出的方法成功地找到了计划、写作和修订管道,并且在每个步骤中都很好地优化了提示。还发现智能体符号学习框架恢复了MetaGPT中开发的标准操作程序,这是一个专门针对软件开发的智能体框架。
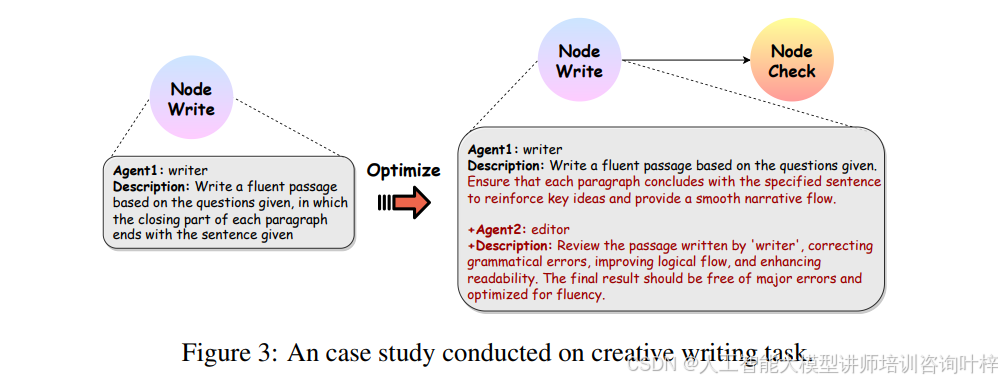
案例研究与分析: 通过 Figure 3 的案例研究,展示了智能体符号学习框架的优化动态。提出的方法可以有效地进行提示工程和设计智能体管道,就像人类专家开发语言智能体一样。
此外,发现智能体系统的初始化对最终性能有不可忽视的影响,就像神经网络的初始化对训练很重要一样。通常,以最简单的方式初始化智能体,并让符号优化器进行优化是有帮助的。相反,如果初始智能体系统过度工程化,性能往往会变得不稳定。
一个自然的延伸是,也许可以对大规模和多样化的任务进行某种预训练,作为通用智能体的多功能初始化,然后使用智能体符号学习适应专门任务。
还发现,提出的方法在复杂现实世界任务上的成功比在标准基准测试上更显著和稳定,后者的性能是通过准确率或F1来评估的。这表明未来的智能体学习研究应该更多地关注现实世界任务,智能体研究社区应该致力于构建一个专注于智能体学习评估的基准,包括多样化的复杂智能任务,并研究稳健的方法来衡量进展。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











