









人工智能咨询培训老师叶梓 转载标明出处
大模型培训讲师叶梓分享前沿论文:10亿人物角色驱动的大模型数据合成
人工智能的发展越来越依赖于海量且多样化的数据。但现实情况是,获取真实、高质量且多样化的数据往往既昂贵又耗时。如果我们能够创造出符合各种需求的合成数据,会怎样呢?最近,腾讯AI实验室西雅图团队就在这方面取得了突破性的进展,他们提出了一个革命性的概念——“人物中心(Persona Hub)”,这是一个包含10亿个不同人物角色的庞大数据库,能够模拟真实世界中各种人的视角和知识,从而生成几乎涵盖所有场景的合成数据。图1展示了人物角色(Personas)如何与各种数据合成提示(prompts)一起工作,以指导大模型(LLM)从相应的视角合成数据。

想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
构建Persona Hub
在构建Persona Hub的过程中,研究者们提出了两种可扩展的方法来从海量网络数据中提取多样化的人物角色:Text-to-Persona 和 Persona-to-Persona。
Text-to-Persona 方法的核心在于,具有特定职业经历和文化背景的人会有独特的阅读和写作兴趣。因此,从一段特定的文本中,我们可以推断出一个可能阅读、写作、喜欢或不喜欢这段文本的特定人物角色。考虑到网络上的文本数据几乎是无限的且包罗万象,可以通过向大模型提示这些网络文本,简单地获得广泛的人物角色集合,如图3所示。
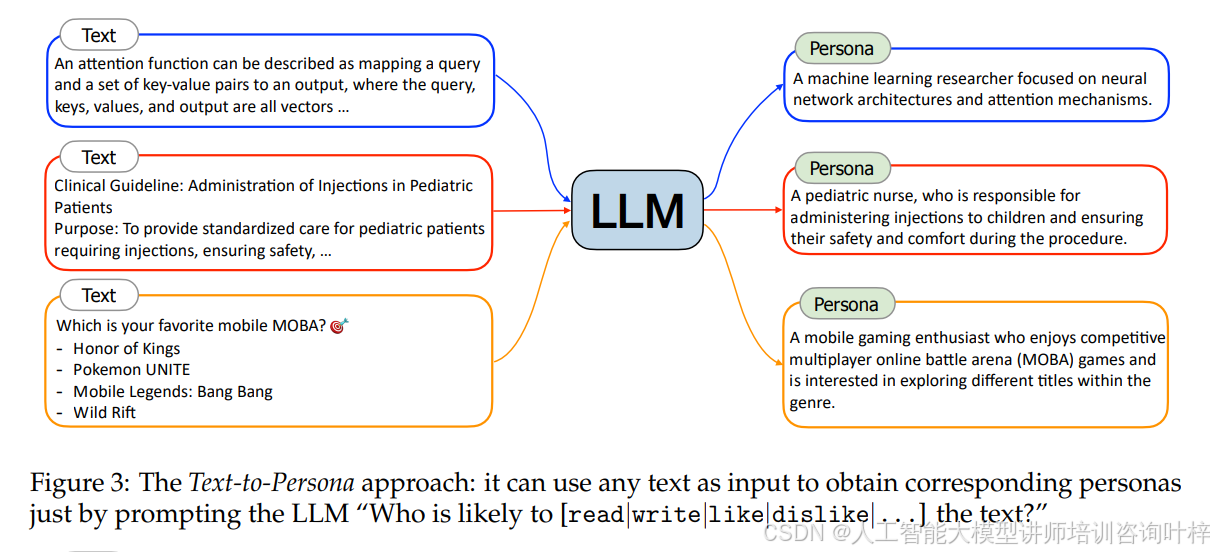
大模型可以接受多种格式(例如,纯文本或结构化文本)的人物角色表示,这可以在提示中控制。输出人物角色描述的粒度也可以通过提示进行调整。例如,在第一种情况下,粗粒度的人物角色可能是“计算机科学家”,而细粒度的人物角色是“专注于神经网络架构和注意力机制的机器学习研究者”。在实践中,我们要求大模型(在提示中)尽可能具体地输出人物角色描述。
如果输入文本(例如,来自数学教科书或关于超导性的学术论文)包含许多详细元素,那么生成的人物角色描述也将是具体和细粒度的。因此,通过将Text-to-Persona方法应用于海量网络文本数据,我们可以获得数十亿(甚至数万亿)的多样化人物角色,涵盖不同粒度的各个方面。
如上所述,Text-to-Persona是一种高度可扩展的方法,可以合成几乎涵盖每个方面的人物角色。然而,它可能仍然会遗漏一些在网络上可见度较低的人物角色,因此不太可能通过Text-to-Persona获得,例如儿童、乞丐或电影的幕后工作人员。为了补充Text-to-Persona可能难以触及的人物角色,我们提出了Persona-to-Persona,它从通过Text-to-Persona获得的人物角色中衍生出具有人际关系的人物角色。
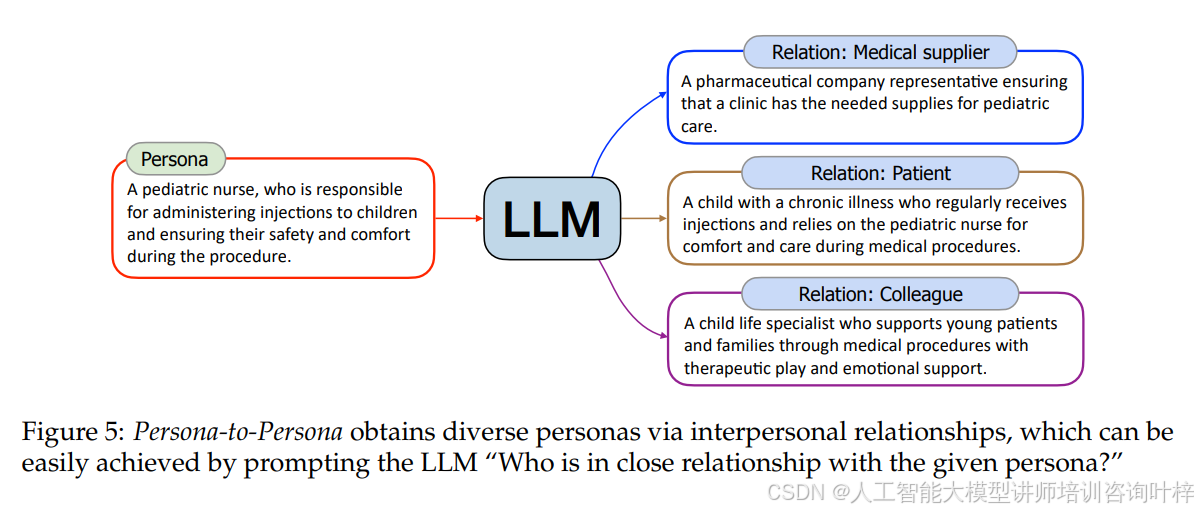
图5Persona-to-Persona 方法:可以通过人际关系获得多样化的人物角色,这可以通过向大模型提示“与给定人物角色关系密切的人是谁?”来轻松实现。
根据六度分隔理论,对每个通过Text-to-Persona获得的人物角色执行六次人物关系扩展,从而进一步丰富人物角色集合。
在运行Text-to-Persona并执行Persona-to-Persona之后,获得了数十亿的人物角色,不可避免地会有一些人物角色是相同或极其相似的。为了确保Persona Hub的多样性,以两种方式去重这些人物角色:
- MinHash-based Deduplication:使用MinHash基于人物角色描述的n-gram特征进行去重。由于人物角色描述通常只是1-2句话,比文档短得多,简单地使用1-gram和128的签名大小进行MinHash去重。在0.9的相似度阈值下进行去重。
- Embedding-based Deduplication:在基于表面形式(即MinHash与n-gram特征)的去重之后,还采用基于嵌入的去重。使用文本嵌入模型(例如,OpenAI的text-embedding-3-small模型)为每个人物角色计算嵌入,然后过滤掉余弦语义相似度大于0.9的人物角色。
人物驱动的合成数据创建
人物驱动数据合成方法直接而有效,它涉及将人物角色整合到数据合成提示中的适当位置。虽然看起来简单,但它可以显著影响大模型采取人物角色的视角来创建合成数据。在Persona Hub中的10亿人物角色的驱动下,这种方法可以轻松地创建大规模的多样化合成数据。

图6:0-shot、few-shot 和 persona-enhanced few-shot 提示方法。正如可以使用零次射击或几次射击方法来提示大模型一样,人物驱动的方法也是灵活的,并且与各种形式的提示兼容,以创建合成数据。如图所示,提出了三种人物驱动的数据合成提示方法:
- Zero-shot prompting:不利用任何现有的例子(即演示),从而充分利用模型的创造力,不受具体例子的限制。
- Few-shot prompting:通过提供一些演示,可以更好地确保合成数据满足要求。
- Persona-enhanced few-shot prompting:在增强大模型的人物驱动数据合成能力方面更有效。然而,其缺点是它需要为few-shot提示中的每个演示推导出相应的人物角色。
Persona Hub的应用案例
Persona Hub在多种数据合成场景中的应用,包括大规模创建数学和逻辑推理问题、指令(即用户提示)、知识丰富的文本、游戏NPC和工具(功能)开发。
数学问题
演示
大模型在创建数学问题时,通过添加人物角色可以引导模型生成与该角色相关的数学问题。例如,在图7(左)中,给定一个语言学家的人物角色后,模型会创建一个与计算语言学相关的数学问题。这表明添加人物角色不会限制问题的焦点或难度,而是可以根据需要轻松指定。
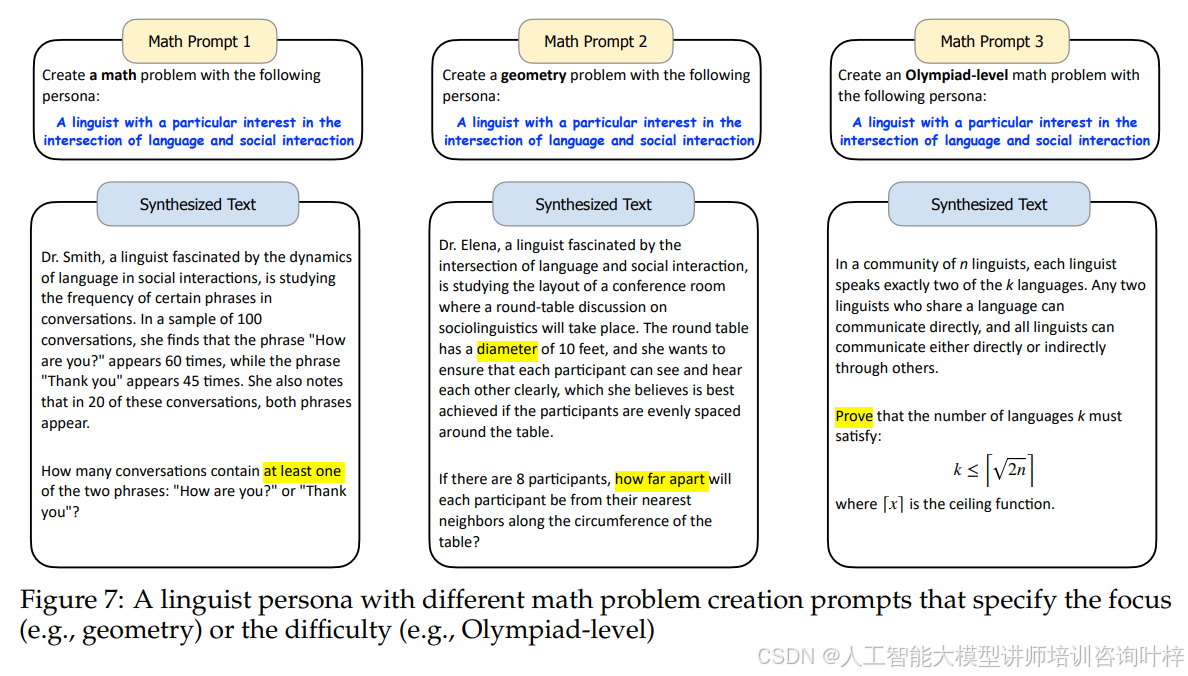
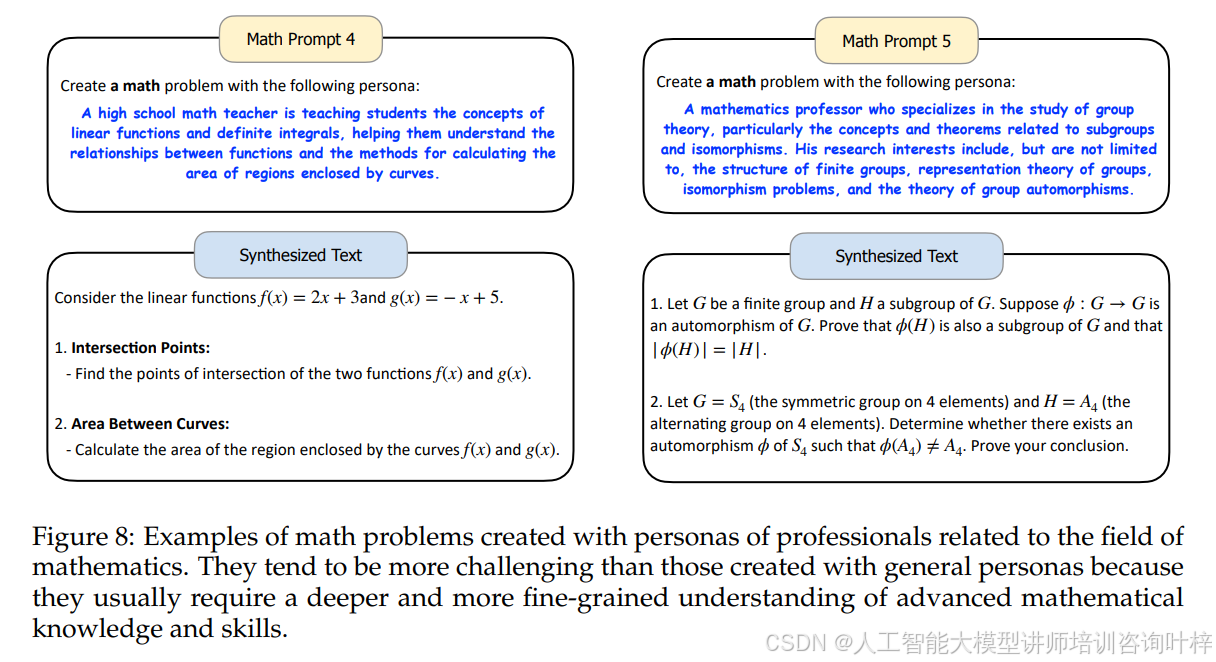
图8 展示了使用与数学领域相关的专业人士人物角色创建的数学问题,这些问题通常更具挑战性,因为它们需要更深入的数学知识和技能。
从Persona Hub中选取了1.09百万个人物角色,并使用0-shot提示方法和GPT-4来创建这些人物角色的数学问题。这种方法允许合成了1.09M个数学问题。为了评估这些数学问题,随机保留了20K作为合成测试集,剩余的1.07M个问题用于训练。
- 合成测试集(In-distribution):这20K问题集合的产生方式与1.07M训练实例相同,因此可以被视为In-distribution测试集。
- MATH(Out-of-distribution):这是测试大模型数学推理能力的最广泛认可的基准,包含5,000个竞技级别的数学问题和参考答案。
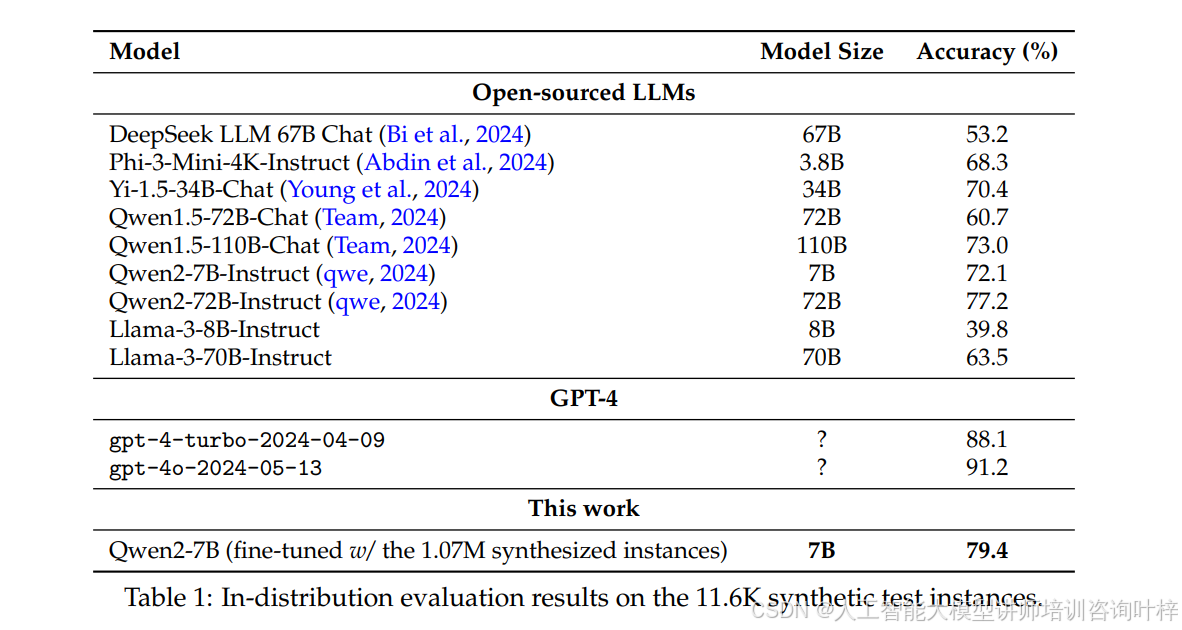
表1 展示了在11.6K合成测试实例上的In-distribution评估结果。模型在1.07M合成数学问题的帮助下,实现了近80%的准确率,超越了所有开源大模型。
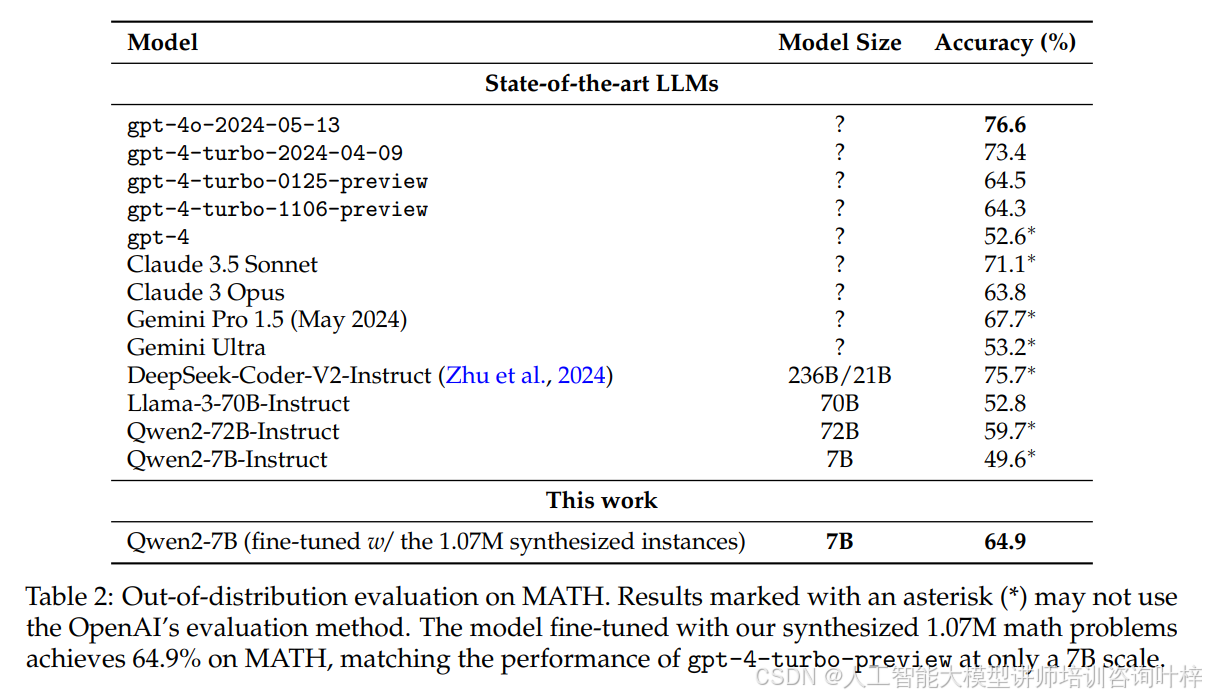
表2 展示了在MATH上的Out-of-distribution评估结果。7B模型使用合成训练数据,在MATH上取得了令人印象深刻的64.9%准确率。
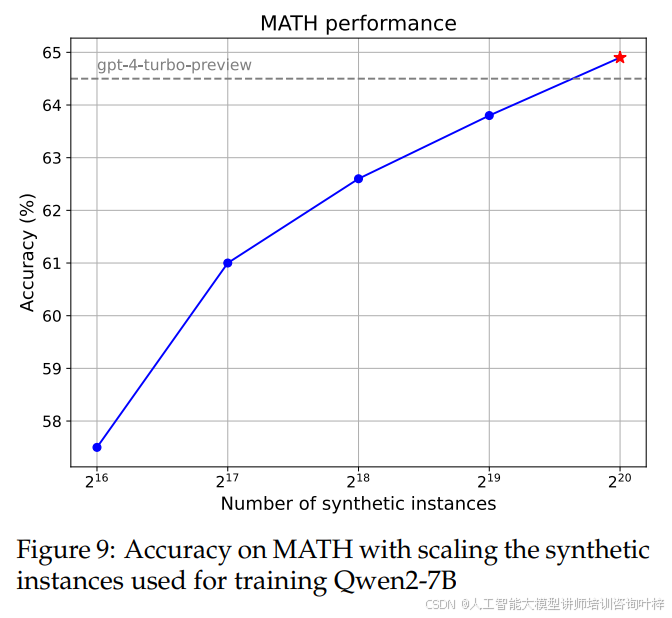 图9 展示了模型在MATH上的性能,当使用不同规模的合成数学问题进行训练时。其性能趋势通常与扩展法则一致。
图9 展示了模型在MATH上的性能,当使用不同规模的合成数学问题进行训练时。其性能趋势通常与扩展法则一致。
逻辑推理问题
类似于数学问题,逻辑推理问题也可以通过人物角色驱动的方法轻松合成。图11 和 图12 展示了使用人物角色创建的典型逻辑推理问题,包括Ruozhiba风格的逻辑推理问题。

指令
Persona Hub可以模拟各种用户,以理解他们对大模型的典型请求,从而产生多样化的指令(即用户提示)。图13 展示了两种典型的人物角色驱动的指令生成提示,分别对应于零次射击和人物角色增强的几次射击提示方法。

知识丰富的文本
除了合成指令外,人物角色驱动的方法还可以轻松适应创建知识丰富的文本,这些文本对大模型的预训练和后训练都有益处。图14 展示了使用Persona Hub中的人物角色提示大模型写Quora文章的例子。

游戏NPC
Persona Hub的一个直接且实际的应用是为游戏创建多样化的NPC(非玩家角色)。只要提供游戏的背景和世界观信息,就可以提示大模型将Persona Hub中的人物角色投影到游戏世界中的角色。图15 和 图16 展示了如何使用Persona Hub中的人物角色为“魔兽世界”和“天涯明月刀”游戏创建NPC。

 工具(功能)开发
工具(功能)开发
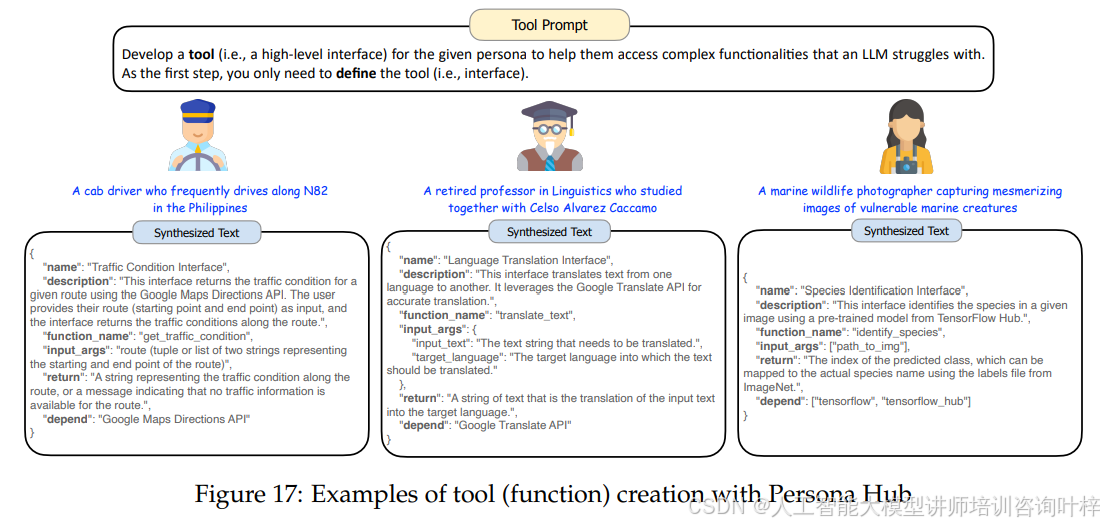
Persona Hub不仅可以模拟真实用户以预测他们可能对大模型的请求(即指令),还可以预测用户可能需要的工具,从而提前构建这些工具(功能)。图17 展示了使用不同人物角色创建的工具的例子。这些工具提供了人物角色可能需要的功能,但大模型无法直接访问,大大扩展了大模型提供的服务范围。
https://arxiv.org/pdf/2406.20094
Scaling Synthetic Data Creation with 1,000,000,000 Personas
https://github.com/tencent-ailab/persona-hub
https://huggingface.co/datasets/proj-persona/PersonaHub




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











