









想要掌握如何将大模型的力量发挥到极致吗?叶梓老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
想快速掌握自动编程技术吗?叶老师专业培训来啦!这里用Cline把自然语言变代码,再靠DeepSeek生成逻辑严谨、注释清晰的优质代码。4月12日,叶梓老师将在视频号上直播分享《用deepseek实现自动编程》。
视频号(直播分享):sphuYAMr0pGTk27 抖音号:44185842659
在人工智能领域,大模型(Large Language Models,LLMs)的发展日新月异,它们在自然语言处理任务中的表现令人瞩目。然而,如何进一步优化这些模型的性能,特别是在奖励建模(Reward Modeling,RM)方面,一直是研究的热点。最近,DeepSeek与清华大学的研究者们联合发表了一篇题为《通用奖励模型的推理时扩展》(Inference-Time Scaling for Generalist Reward Modeling)的论文,提出了一种新的方法,通过增加推理计算资源来提升通用奖励模型的性能。
奖励建模的重要性
奖励建模是强化学习(Reinforcement Learning,RL)中的一个关键环节,它通过为模型的行为分配奖励信号来引导模型的学习方向。对于大模型来说,奖励建模可以帮助模型更好地理解人类的偏好和价值观,从而生成更符合人类期望的文本内容。然而,奖励建模面临的一个主要挑战是如何在不同的领域和任务中生成准确且高质量的奖励信号。
推理时间扩展性的探索
为了提高奖励建模在大模型中的应用效果,DeepSeek与清华大学的研究者们提出了推理时间扩展性(Inference-Time Scalability)的概念。这种方法的核心在于,通过增加推理时的计算资源,例如多次采样和聚合,来生成更准确的奖励信号。具体来说,就是通过并行采样生成多个不同的奖励信号,然后通过投票(Voting)的方式选择最终的奖励结果。
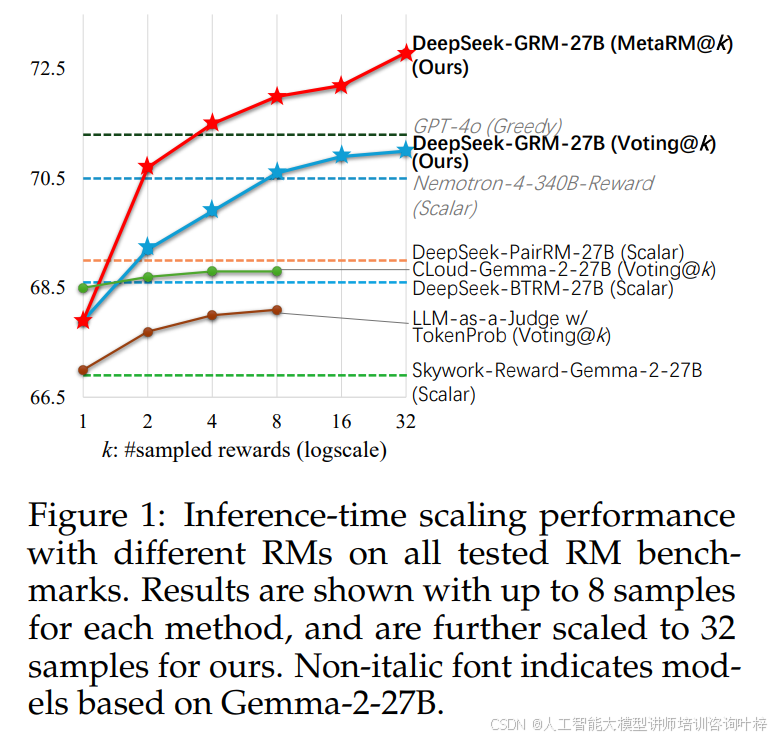
在论文中,研究人员通过实验展示了不同奖励建模方法在推理时间扩展性方面的表现。图 1展示了在不同采样数量下,各种奖励建模方法的性能变化。结果显示,基于点生成(Pointwise)的奖励建模方法(如DeepSeek-GRM-27B)表现出了显著的性能提升。
点生成奖励建模的优势
点生成奖励建模方法是一种灵活的奖励建模方式,它能够为单个、成对或多个响应生成奖励信号。这种灵活性使得点生成奖励建模方法在处理不同类型的任务时具有明显的优势。例如,在处理单个回答的评分任务时,点生成奖励建模可以直接为每个回答分配一个奖励值;而在比较多个回答的优劣时,它也能够生成相应的奖励信号来进行排序。
此外,点生成奖励建模方法还能够通过生成详细的批评(Critique)来解释奖励信号的来源。这些批评内容可以帮助研究人员更好地理解模型是如何评估输入内容的,从而为进一步优化模型提供依据。
自我原则批判调整方法
为了进一步提升奖励建模的性能,研究人员提出了一种名为自我原则批判调整(Self-Principled Critique Tuning,SPCT)的方法。这种方法通过在线强化学习(Online Reinforcement Learning)的方式,让模型在推理过程中自动生成适应性的原则(Principles)和准确的批评内容。这些原则和批评内容不仅可以指导模型生成更准确的奖励信号,还能够随着推理计算资源的增加而不断优化。
在SPCT方法中,模型首先通过拒绝式微调(Rejective Fine-Tuning)阶段来适应生成原则和批评内容的任务。然后,在在线强化学习阶段,模型会根据输入的查询和回答,生成相应的原则和批评内容,并通过与环境的交互来不断优化这些内容。
推理时间扩展性的实现
为了实现推理时间扩展性,研究人员采用了并行采样的方法来增加计算资源的使用。通过并行采样,模型可以在短时间内生成多个不同的奖励信号,然后通过投票(Voting)的方式选择最终的奖励结果。这种方法不仅能够提高奖励信号的质量,还能够随着采样数量的增加而进一步提升模型的性能。
在论文中,研究人员还引入了一种元奖励建模(Meta Reward Modeling)方法来进一步优化投票过程。元奖励建模方法通过训练一个额外的模型来评估生成的原则和批评内容的质量,从而在投票过程中过滤掉低质量的样本。
实验结果与分析
通过一系列的实验,研究人员验证了SPCT方法在奖励建模中的有效性。实验结果表明,SPCT方法显著提高了奖励建模的质量和推理时间扩展性,使其在多个奖励建模基准测试中超越了现有的方法和模型。例如,在表 2中,DeepSeek-GRM-27B在推理时间扩展性方面的表现尤为突出,其性能随着采样数量的增加而显著提升。
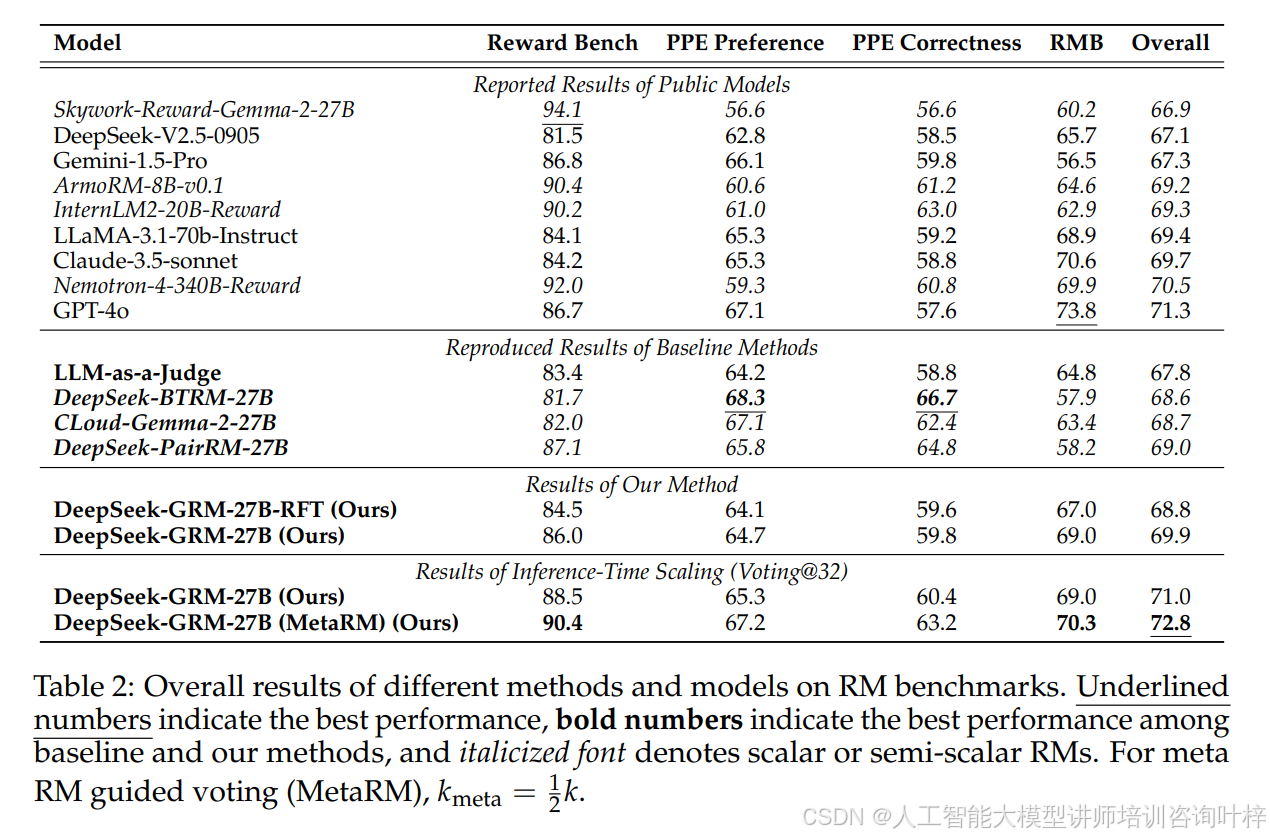
此外,研究人员还对SPCT方法的不同组成部分进行了消融研究(Ablation Study)。实验结果表明,原则生成(Principle Generation)和拒绝式微调(Rejective Fine-Tuning)等组成部分对于SPCT方法的性能至关重要。
推理时间扩展性与训练时间扩展性的比较
除了在推理时间扩展性方面的研究,研究人员还对奖励建模的训练时间扩展性进行了探索。训练时间扩展性指的是通过增加模型的训练计算资源,来提升模型在训练阶段的性能。
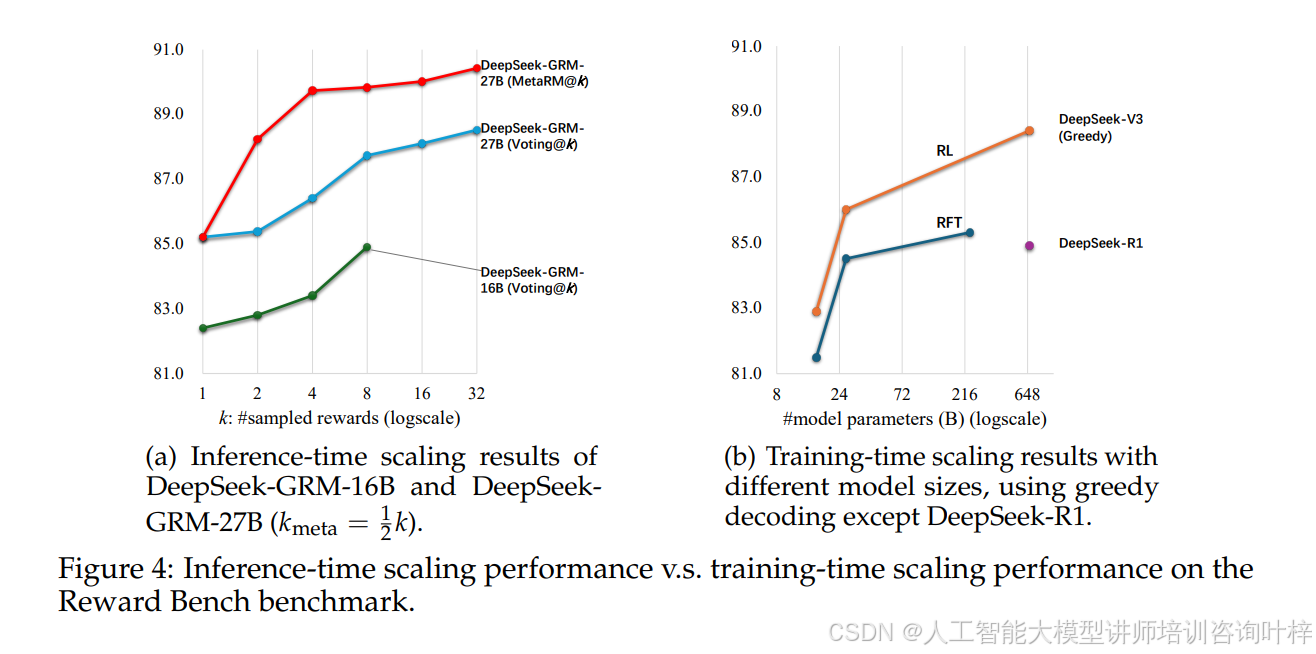
实验结果表明,推理时间扩展性在某些情况下能够超越训练时间扩展性。例如,在图 4中,研究人员展示了DeepSeek-GRM-27B在推理时间扩展性方面的性能与不同大小的模型在训练时间扩展性方面的性能对比。结果显示,通过增加推理时的计算资源,DeepSeek-GRM-27B能够达到与更大规模模型相当的性能,甚至在某些情况下表现更好。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











