






Test-Time Personalization with a Transformer for Human Pose Estimation
2021 CVPR
摘要
我们提出在给定一组人的测试图像的情况下对人体姿态估计器进行个性化,而不使用任何人工注释。虽然人体姿态估计有了很大的进步,但要将模型推广到不同的未知环境和没见过的人仍然是非常有挑战性的。我们没有为每个测试用例使用固定的模型,而是在测试期间调整我们的姿态估计器,以利用特定于人的信息。我们首先在不同的数据上训练我们的模型,联合了监督和自监督的姿态估计。我们使用了一个transformer模型来建立自监督关键点和监督关键点之间的转换。在测试期间,我们通过根据自监督的目标进行微调来个性化和调整我们的模型。然后,通过对更新后的自监督关键点进行变换来改进该假设。我们用多个数据集进行了实验,结果表明,我们的自监督个性化显著改善了概率估计。
结论
在本文中,我们提出在测试期间使用未标记的测试样本来个性化人体姿态估计。我们提出的TTP方法首先使用不同的数据进行训练,然后在测试时使用自监督关键点进行更新,以适应特定的主题。为了加强监督任务和自监督任务之间的关系,我们提出了一种transformer设计,允许从微调的自监督关键点直接改进监督姿态估计。我们提出的方法在多个数据集上比基线有了显著的改善。
方法
1. 自监督关键点估计
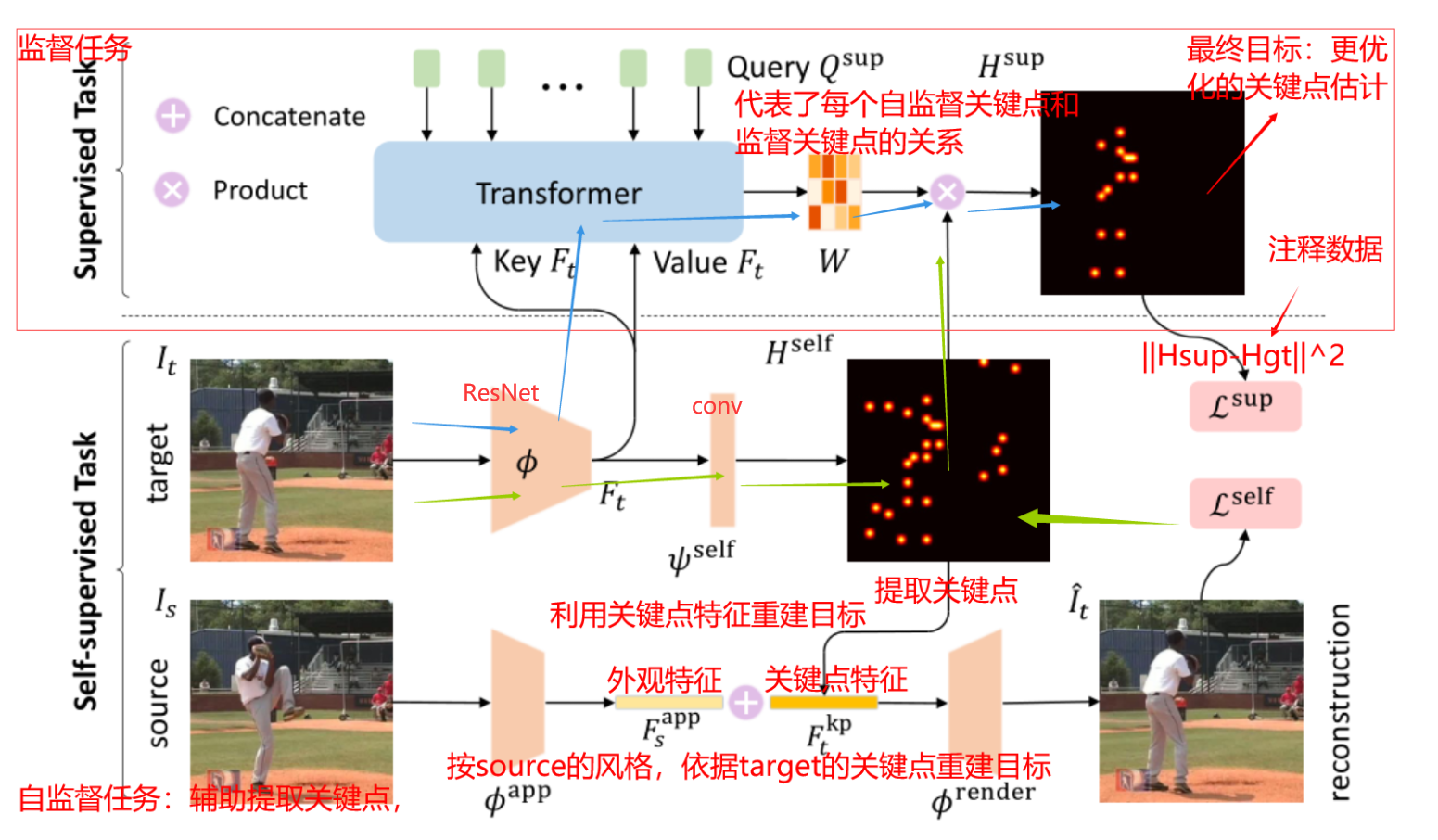
自监督任务的模型参考自Unsupervised Learning of Object Landmarks through Conditional Image Generation,几乎一样
基于transformer的监督关键点估计,transformer的设计对监督任务和自监督任务之间的关系进行了建模,学习亲和力矩阵(affinity matrix)使自监督关键点与监督关键点对齐,避免了多任务训练中的冲突。transformer与卷积模型相比,具有更好的全局上下文信息捕捉能力
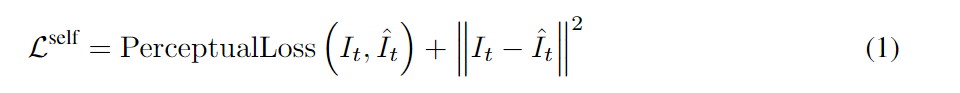
PerceptualLoss引用自Perceptual Losses for Real-Time Style Transfer and Super-Resolution
用于计算图像变换损失

2. 测试期间个性化(Test-Time Personalization)
先冻结监督transformer部分,利用损失函数Lself更新共享编码器φ和自监督头ψself 。然后将更新后的共享编码器和自监督头与监督的头部一起用于最终预测。
在预测过程中,更新过的特征和自监督头部将输出改进的关键点热图,从而可以得到更好的重建。这些改进的自监督热图将同时通过transformer来生成改进的监督关键点。
的自监督热图将同时通过transformer来生成改进的监督关键点。















 984
984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









