










我们知道transformer中的正则化除了使用常见的dropout,还使用了label smoothing,也就是标签平滑。
标签平滑其实就是将硬标签(hard label)转化为软标签(soft label),也就是将标签的one hot编码中的1转化为比1稍小的数,将0转化为比0稍大的数,这样在计算损失函数时(比如交叉熵损失函数),损失函数会把原来值为0的标签也考虑进来,其实就相当于在标签的one hot编码中的每一维上增加了噪声。本质上是向训练集中增加了信息,使得训练集的信息量增大了,更加接近真实分布的数据集的信息量,所以有利于缓解过拟合。
标签平滑的计算公式如下:
output = (1-ϵ)input+ϵ/K
其中ϵ为平滑系数,默认值是0.1,input为K类别组成的K维矩阵,K便是具体任务所分类的类别数(本例中由于使用的是逻辑回归,所以K=2),output为标签平滑时的K类别组成的K维矩阵。
逻辑回归正类和负类的标签分别设为1和0,也就是这里的input为[1,0],ϵ为0.05,那么output = (1-0.05)[1,0]+0.05/2 = [0.975,0.025]。
可以看到,原来的[0,1]编码变成了[0.025,0.975]了。又由于交叉熵损失函数如下:
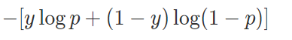
可以设p的阈值为0.5,也就是当p大于该值时样本被划分到正类(y=1),当p小于该值时,样本被划分到负类(y=0)。我们假设模型对某一样本预测为正类的概率为:
如果p=0.8,则传统方式损失为-1log(0.8)=0.097,使用标签平滑后,损失为:-[0.975log(0.8)+(1-0.975)log(1-0.8)] = 0.11
如果p=0.95,传统方式损失为-1log(0.95) = 0.022,而如果使用标签平滑,损失为-[0.975log(0.95)+(1-0.975)log(1-0.95)] = 0.054。
如果p=0.999,对于传统方式,其损失为-1log(0.999)=0.00043。做了标签平滑后其损失为:-[0.975log(0.999)+(1-0.975)*log(1-0.999)] = 0.075。
可以看出,对于同一个样本(假设该样本属于正类),如果不使用标签平滑,则模型预测的概率越大,则对应的损失就越小,也就是模型倾向于把样本预测为某类别的概率尽可能的大。如果使用标签平滑,则随着模型预测的概率增大,损失先变小后又增大,也即模型倾向于将样本预测为某类的概率在一个较大的值但是不是尽可能的大。
这里我们可以看出来了,加入了标签平滑后,使得过拟合模型的损失变得较大,一定程度上阻止了模型过度学习的趋势。















04-05
 2463
2463
2463
09-27
428
428
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









