






一、2.5更新
1、layer normalization和batch normalization的区别
参考:http://t.csdnimg.cn/VSDJz
(1)为什么在模型训练前需要对数据归一化?
为了解决ICS问题,即internal covariate shift(内部协变量漂移)问题,该问题会使数据分布发生变化,对下层网络的学习带来困难。
在深度神经网络中,层与层之间是存在直接或间接影响的,某一层的微小变动就可能导致其它层的“剧烈震荡”导致相应网络层落入饱和区【sigma函数中当x<-6或x>6时,梯度值接近0,BP过程中低层神经网络梯度消失】,导致模型的训练困难,这种现象称为“internal covariate shift”。为了减少层和层之间的影响,学者们考虑从直观的数据分布上进行处理,将批量数据标准化到~N(0,1)分布,使得每层的输入数据分布范围可控。
(2)batch normalization
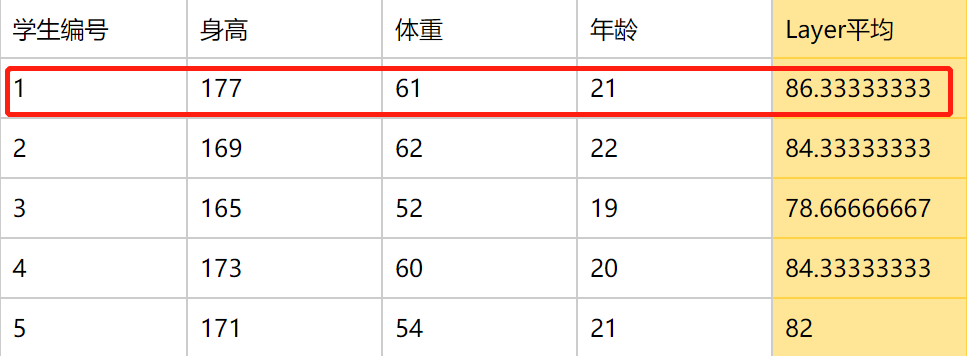
对一批样本的同一维度特征做归一化。如下图根据这个batch中的三种特征(身高、体重、年龄)数据进行性别预测,首先进行归一化管理,如果是batch normalization则是对每一列特征进行归一化,如求一列身高的平均值。

特点:强行将数据转化为均值为0,方差为1的正态分布,使得数据分布一致,并且避免梯度消失。而梯度变大意味着学习收敛速度快,能够提高训练速度。
设batch_size=m,网络前向传播时,每个深进院都有m个输出,BN就是将每个神经元的m个输出做归一化处理,以下是BN原论文中的伪代码:

即有两个步骤:
- 标准化:求得均值为0,方差为1的标准正态分布 x ˉ i \bar x_i xˉi;
- 尺寸变换和偏移:获得新的分布 y i y_i yi。均值为β,方差为γ(其中偏移β和尺寸变换γ是需要学习的参数)。该过程有利于数据分布和权重的互相协调。
缺点:
- 对batch size的大小比较敏感,由于每次计算均值和方差是在一个batch上,因此如果batch size太小,则计算的均值、方差不足以代表整个数据分布。
- batch normalization实际使用时需要计算并保存每一层神经网络batch的均值和方差等统计信息,对一个固定深度的前向神经网络(DNN、CNN)使用BN很方便,但对于RNN来说,sequence的长度是不一致的,即RNN的深度不是固定的,不同的时间步需要保存不同的数据特征,可能存在一个特殊的sequence比其他sequence的长度长,这样训练时计算就比较麻烦。
(3)layer normalization
对单个样本的所有维度特征做归一化。如下图,layer normalization是对每一行(该条数据)的所有特征数据求平均值。
BN与LN的区别:
- LN中同层神经元输入拥有相同的均值和方差,不同的输入样本拥有不同的均值和方差;
- BN中则针对不同神经元输入来计算均值和方差,同一batch中的输入拥有相同的均值和方差。
2、Bert采用mask的具体策略,为什么这么设计?
参考:https://mp.weixin.qq.com/s?__biz=MzI4MDYzNzg4Mw==&mid=2247509962&idx=3&sn=5a4759570b286d00eeb2a3366f784bb5&chksm=ebb79f1edcc01608a7b46e85561bf191284c33fb322fb44539f6bb2a41d451a172f05cc67fe9&scene=27
(1)我们怎么用Bert?
Bert一般不直接拿去解决相应的下游任务,而是将其在特定数据上进行微调后再使用。也就是说包含了两个阶段,第一阶段是预训练阶段,即使用大量的数据喂给Bert进行无差别学习,相当于我们大量学习基础知识(比如识字、造句、完形填空);第二阶段是微调阶段,这里使用少量带标签的领域数据微调Bert模型,就比如让我们具体学习一篇阅读理解以提升我们在阅读理解方面的能力,从而使我们在学完以后(微调完后)在其他更多的阅读理解上能够获得一个好的成绩。
(2)mask策略的具体使用
Bert在第一阶段预训练阶段的学习目标有两个:
- Masked LM
- NextSentence Prediction
也就是说,mask策略是在预训练阶段使用的!!
Masked LM即掩码语言模型,它和一般的语言模型不同: - 自回归模型:这种模型的第i个字的概率和它前i-1个字有关,也就是说要预测第i个字,模型就得先从头到尾一次预测出第1到第i-1个字,再预测第i个字;
- Masked LM:随机将句子中的某些字mask掉,然后通过被mask掉的字的上下文来预测这个字是什么。
Bert的MASK机制:
以token为单位随机选择句子中15%的token,然后(这地方捋清楚哈,是对选出来的15%进行操作):
- 其中的80%使用[MASK]符号进行替换;
- 10%使用随机的其他token替换;
- 剩下10%不变。
(3)MASK的作用?
①处理非定长输入序列
- RNN中的MASK
- Attention中的MASK
比如用于RNN和Attention中,这是一般构造一个MASK矩阵来实现,矩阵元素只包含0和1。
在神经网络中处理非定长的输入序列我们会使用padding来对句子进行截长补短,即把句子转换成一个定长的向量,长度不够使用0来填充。

这样做的目的是方便模型的批量训练处理,但是会带来一个问题,因为在经过RNN或CNN后一般会进行一个最大池化或平均池化操作。
假设某输入维度为(1,4,4),即batch size为1,句子经过padding填充后的长度为4,词向量维度为4,如下所示:
tensor = [[[-0.31374098, 1.37414397, 0.55369354, 1.48887183],
[-1.66548506, 2.54986855, -0.11285839, 0.62201919],
[-0.13604648, 0.91690237, 0.05759679, -1.06613941],
[0, 0, 0, 0 ]]]
最后一行为padding向量,分别对其进行全局最大池化和平均池化得:
max_pooling = [[0. , 2.54986855, 0.55369354, 1.48887183]]
mean_pooling = [[-0.52881813, 1.21022872, 0.12460799, 0.2611879 ]]
如果不进行padding,即把最后一行全0向量去掉,它的最大池化和平均池结果为:
max_pooling = [[-0.13604648, 2.54986855,0.55369354, 1.48887183]]
mean_pooling = [[-0.70509084, 1.6136383 , 0.16614398, 0.34825054]]
可见padding会影响模型的学习效果。使用MASK矩阵即可去除这种影响。根据以上例子,MASK矩阵可以表示为:
M = [[1,1,1,0]]
它的维度一般为batch_size * max_len,max_len表示句子的最大长度,M矩阵中的1表示该位置是正常token,0表示该位置是padding的,那么在后续计算中需要忽略该位置的信息。
加入MASK矩阵后计算平均池化的公式为:
mean_pooling = np.sum(tensor * M.T,axis=1)/np,sum(M,axis=1)
其中.T表示句子的转置,计算结果为[[-0.70509084, 1.6136383 , 0.16614398, 0.34825054]],这和不进行 padding是一致的。
max_pooling = np.max(tensor - (1-M.T) * 1e10 , axis=1)
意思是将句子中的padding位置减去无穷大,变成无穷小,那么计算最大值时就不会取到这个padding值了,计算结果为[[-0.13604648, 2.54986855, 0.55369354, 1.48887183]],和不进行padding是一致的。
②防止标签泄露
- Transformer中的MASK
- BERT中的MASK
- XLNet中的MASK
在语言模型中,常常需要从上一个词预测下一个词,但如果要在LM中应用 self attention 或者是同时使用上下文的信息,要想不泄露要预测的标签信息,就需要 mask 来“遮盖”它。
3、常用的文本数据增强方法
参考:https://www.cnblogs.com/IllidanStormrage/p/16347433.html
当前的有监督的深度学习模型,若想获得高性能,需要依赖大量标注训练数据。然而在实际项目中,往往存在训练样本少、标注数据成本高等情况。在这种情况下,我们就需要用到文本数据增强技术。
(1)Easy Data Augmentation(EDA)
代码:https://github.com/jasonwei20/eda_nlp/blob/master/code/eda.py
具体包括同义词替换、随机插入、随机交换、随机删除等。
无监督方法——EDA来自论文《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》。一个用于提高文本分类任务性能的简单数据增强技术。在实验的五个文本分类任务中,EDA提高了卷积和递归神经网络的性能。EDA对于较小的数据集表现出特别强的结果;平均而言,在五个数据集上,仅使用50%的可用训练集进行EDA训练达到了与使用所有可用数据进行正常训练相同的准确度。
EDA的4个数据增强操作:
①同义词替换(Synonym Replacement,SR)
从句子中随机选择n个非停用词,然后每个词随机选择一个同义词替换它们。举例如下:
原句: 每周三 \color{red}{每周三} 每周三在会议室进行项目汇报周会。
输出: 每周五 \color{red}{每周五} 每周五在会议室进行项目汇报周会。
代码:
########################################################################
# Synonym replacement
# Replace n words in the sentence with synonyms from wordnet
########################################################################
#for the first time you use wordnet
#import nltk
#nltk.download('wordnet')
from nltk.corpus import wordnet
def synonym_replacement(words, n):
new_words = words.copy()
random_word_list = list(set([word for word in words if word not in stop_words]))
random.shuffle(random_word_list)
num_replaced = 0
for random_word in random_word_list:
synonyms = get_synonyms(random_word)
if len(synonyms) >= 1:
synonym = random.choice(list(synonyms))
new_words = [synonym if word == random_word else word for word in new_words]
#print("replaced", random_word, "with", synonym)
num_replaced += 1
if num_replaced >= n: #only replace up to n words
break
#this is stupid but we need it, trust me
sentence = ' '.join(new_words)
new_words = sentence.split(' ')
return new_words
②随机插入(Random Insertion,RI)
从句子中随机选择一个非停用词,然后随机选择该词的一个同义词。将该同义词插入到句子中的随机位置。此过程重复n次。举例如下:
原句:每周三在会议室进行项目汇报周会。
输出:每周三在会议室 每周四 \color{red}{每周四} 每周四进行项目汇报周会。
代码:
########################################################################
# Random insertion
# Randomly insert n words into the sentence
########################################################################
def random_insertion(words, n):
new_words = words.copy()
for _ in range(n):
add_word(new_words)
return new_words
def add_word(new_words):
synonyms = []
counter = 0
while len(synonyms) < 1:
random_word = new_words[random.randint(0, len(new_words)-1)]
synonyms = get_synonyms(random_word)
counter += 1
if counter >= 10:
return
random_synonym = synonyms[0]
random_idx = random.randint(0, len(new_words)-1)
new_words.insert(random_idx, random_synonym)
③随机交换(Random Swap,RS)
从句子中随机选择两个词,交换位置。此过程重复n次。举例如下:
原句:每周三在 会议室 \color{red}{会议室} 会议室进行 项目 \color{red}{项目} 项目汇报周会。
输出:每周三在 项目 \color{red}{项目} 项目进行 会议室 \color{red}{会议室} 会议室汇报周会。
代码:
########################################################################
# Random swap
# Randomly swap two words in the sentence n times
########################################################################
def random_swap(words, n):
new_words = words.copy()
for _ in range(n):
new_words = swap_word(new_words)
return new_words
def swap_word(new_words):
random_idx_1 = random.randint(0, len(new_words)-1)
random_idx_2 = random_idx_1
counter = 0
while random_idx_2 == random_idx_1:
random_idx_2 = random.randint(0, len(new_words)-1)
counter += 1
if counter > 3:
return new_words
new_words[random_idx_1], new_words[random_idx_2] = new_words[random_idx_2], new_words[random_idx_1]
return new_words
④随机删除(Random Deletion,RD)
句子中的每个词,以概率p进行随机删除。举例如下:
原句:每周三在 会议室 \color{red}{会议室} 会议室进行项目汇报周会。
输出:每周三在进行项目汇报周会。
代码:
########################################################################
# Random deletion
# Randomly delete words from the sentence with probability p
########################################################################
def random_deletion(words, p):
#obviously, if there's only one word, don't delete it
if len(words) == 1:
return words
#randomly delete words with probability p
new_words = []
for word in words:
r = random.uniform(0, 1)
if r > p:
new_words.append(word)
#if you end up deleting all words, just return a random word
if len(new_words) == 0:
rand_int = random.randint(0, len(words)-1)
return [words[rand_int]]
return new_words
(2)An Easier Data Augmentation(AEDA)
代码:https://github.com/akkarimi/aeda_nlp
AEDA就是在句子中间添加标点符号以此来增强数据。
(默默地说,其实这种数据增强方法实际用下来一点也不好用,所以咱就是说应付面试或者笔试就行,真正做项目还是找更好的方法…)
①输入多少标点符号?
从1到三分之一句子长度中,随机选择一个数,作为插入标点符号的个数。
②为什么是1到三分之一句长?
作者表示,既想每个句子中有标点符号插入,增加句子的复杂性;又不想加入太多标点符号,过于干扰句子的语义信息,并且太多噪声对模型可能有负面影响。
③句子插入标点符号的位置如何选取?
随机插入。
④标点符号包含哪些?
主要有6种,“.”、“;”、“?”、“:”、“!”、“,”。
⑤AEDA比EDA效果好的理论基础是什么?
作者认为,EDA方法无论是同义词替换、随机替换、随机插入还是随机删除,都改变了原始文本的序列信息;而AEDA方法,只是插入标点符号,对于原始数据的序列信息修改不明显。
代码:
PUNCTUATIONS = ['.', ',', '!', '?', ';', ':']
PUNC_RATIO = 0.3
def insert_punctuation_marks(sentence, punc_ratio=PUNC_RATIO):
words = sentence.split(' ')
new_line = []
q = random.randint(1, int(punc_ratio * len(words) + 1))
qs = random.sample(range(0, len(words)), q)
for j, word in enumerate(words):
if j in qs:
new_line.append(PUNCTUATIONS[random.randint(0, len(PUNCTUATIONS)-1)])
new_line.append(word)
else:
new_line.append(word)
new_line = ' '.join(new_line)
return new_lin
(3)Unsupervised Data Augmentation(UDA)
一个半监督的学习方法,减少对标注数据的需求,增加对未标注数据的利用。来自论文《Unsupervised Data Augmentation for Consistency Training》。
二、5.14更新
1、encoder、decoder
- 编码器的输入是源语言的输入序列,例如英语句子。每个输入单词首先经过一个词嵌入层(word embedding),将其转换为一个固定维度的向量。然后,每个词向量还要加上一个位置嵌入向量(position embedding),用于表示单词在句子中的位置信息。位置嵌入向量可以通过训练得到,也可以使用三角函数计算得到。词向量和位置向量相加后,就得到了编码器的输入向量。
- 编码器的输出是一个隐藏状态矩阵,每一行对应一个输入单词的编码信息。编码器由多个相同的编码层堆叠而成,每个编码层包含两个子层:多头注意力层(Multi-Head-Attention)和前馈神经网络层(Feed Forward Neural Network)。多头注意力层用于计算输入序列中每个单词与其他单词的相关性,前馈神经网络层用于对自注意力的输出进行非线性变化。每个子层后面还有一个残差连接和一个层归一化操作,用于提高模型的稳定性和泛化能力。编码器的最后一个编码层的输出就是隐藏状态矩阵,它将作为解码器的输入之一。
- 解码器的输入是目标语言的部分输出序列,例如中文句子。每个输出单词也要经过一个词嵌入层和一个位置嵌入层,得到解码器的输入向量。
- 解码器的输出是一个概率分布向量,表示下一个输出单词的预测概率。解码器由多个相同的解码层堆叠而成,每个解码层包含三个子层:多头自注意力层、多头编码-解码注意力层(Multi-Head Encoder-Decoder Attention)和前馈神经网络层。多头自注意力层用于计算输出序列中每个单词与输入序列中每个单词的相关性,前馈神经网络层用于对注意力的输出进行非线性变换。每个子层后面也有一个残差连接和一个层归一化操作。解码器的最后一个解码层的输出经过一个线性层和一个softmax层,得到下一个输出单词的概率分布向量。















 1047
1047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









