







使用场景:扫描版PDF在使用时没有目录很不方便,尤其是导入到goodnotes等软件时。在acrobat中可以手动添加书签,但是效率较低。这里记录下如何批量添加目录,关键点是目录文件的处理。
所示软件:FreePic2PDF 和GVIM
第一步:提取PDF原始的目录信息(FreePic2PDF使用参考)(FreePic2PDF下载地址)
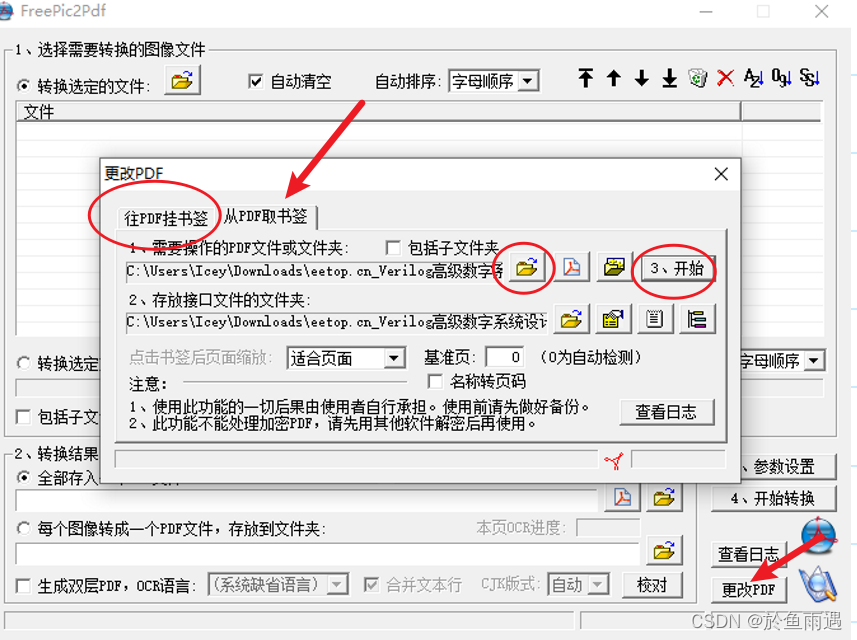
首先取书签,会在当前文件路径生成文件夹,接着修改txt文件,最后挂书签即可。
第二步:制作目录信息包
思路:从当当淘宝等网站复制文字版本目录,利用OCR识别数字目录,最后进行拼接。核心是对TXT的处理,建议熟练使用GVIM。
京东详情页存在具体的目录,但是没有页码。

用gvim新建文件,利用通配符操作进行替换,在小章节前添加Tab(\t)


对页码进行截图,只保留数字,利用OCR在线识别出txt输出,在线OCR网址
注:识别文字可以选择较生僻的,亲测DANISH无误差。
TXT处理
页码需要先合并,同时可能出现一行多个的情况,需要用gvim替换,思路是找数字开头空格结尾,在数字前添加Tab。
最后把两个TXT每一行合并,可以使用脚本,这里使用参考。
txt合并脚本bat,把文件放在同一个文件夹
txt合并脚本bat,把文件放在同一个文件夹
@echo off
set num=0
setlocal enabledelayedexpansion
for /f "delims=" %%a in (1.txt) do (
if !num! equ 0 (
set /p str=<2.txt
echo %%~a !str!>>3.txt
) else (
call:get !num! "%%~a"
)
set /a num+=1
)
pause
exit
:get
for /f "skip=%~1 delims=" %%b in (2.txt) do (
echo %~2 %%b>>3.txt
goto :eof
)
最终效果
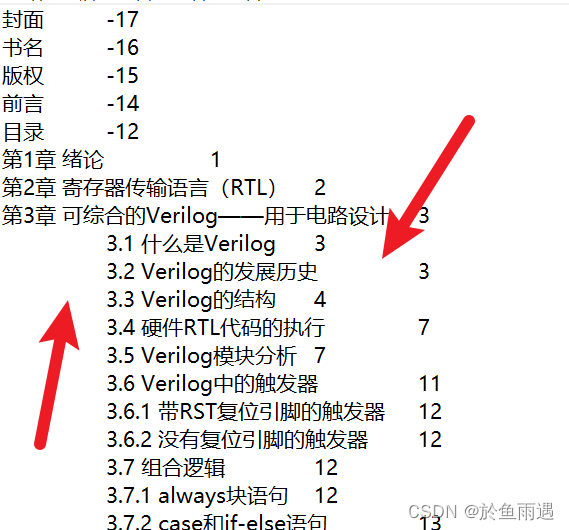
完成TXT处理后,回到第一步参考,用软件导入即可。
注意点:
- 一级标题顶格,二级标题TAB缩进,页码TAB缩进。
- 没有页码使用OCR时注意可能有错误,直接有页码的目录改格式即可。
- GVIM不是必须的,记事本应该也有通配符操作。
- 示例中页码从正文开始,部分文件的页码从封面开始,这时需要重新编码。建议第一页前使用ABC。


















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









