







Gradient descent 梯度下降
可以尝试使用梯度下降法来最小化任何代价函数 J J J,不仅仅是线性回归中的代价函数。
基本思想:一般给定 θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1的初始值均为0,持续改变二者的值,直到找到代价函数的最小值。

梯度下降的运行过程:
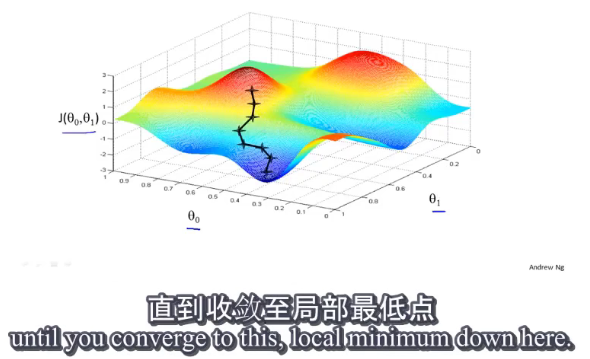
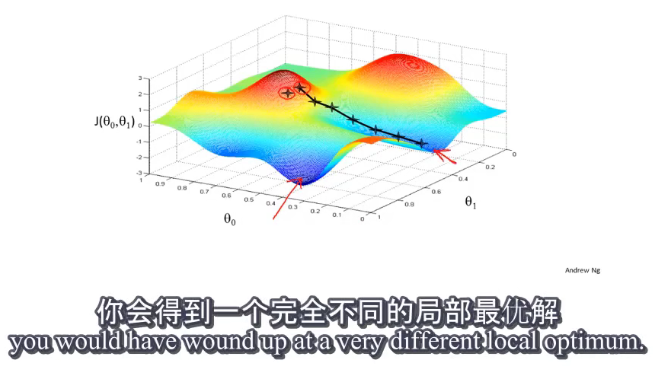
梯度下降的特点:和初始开始的位置有关,即和 θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1的初始值有关。并且不同的初始值可能得到完全不同的局部最优解。
数学原理
梯度下降算法:反复执行{}内的步骤,直到收敛。对于更新方程,需要同时更新
θ
0
\theta_0
θ0和
θ
1
\theta_1
θ1

其中“:=”表示赋值,“=”表示真假判定; α \alpha α表示学习率或学习速率,用来控制梯度下降时,“迈出步子的大小”,即以多大的幅度更新参数 θ j \theta_j θj, α \alpha α的值越大,梯度下降的越迅速。
将代价函数简化为只有一个参数 θ 1 \theta_1 θ1,试着去理解梯度下降法在这个函数上起什么作用。

探究梯度下降算法的更新规则:
假设以下是关于实数 θ 1 \theta_1 θ1的函数 J ( θ 1 ) J(\theta_1) J(θ1),现在从出发开始梯度下降,梯度下降要做的就是不断更新,即 θ 1 = θ 1 − α d J ( θ 1 ) d θ 1 \theta_1=\theta_1- \alpha\frac{\mathrm{d} J\left ( \theta_1 \right )}{\mathrm{d} \theta_1} θ1=θ1−αdθ1dJ(θ1),(这里使用 d d θ \frac{\mathrm{d} }{\mathrm{d\theta}} dθd导数符号,是因为函数 J ( θ 1 ) J(\theta_1) J(θ1)只有一个变量)。
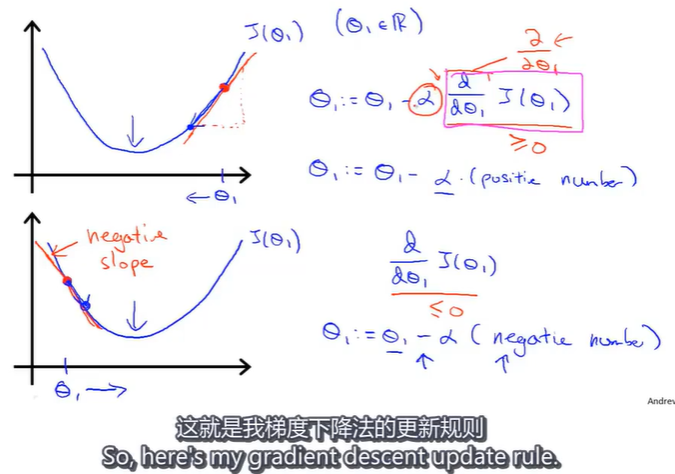
其中,当 d J ( θ 1 ) d θ 1 \frac{\mathrm{d} J\left ( \theta_1 \right )}{\mathrm{d} \theta_1} dθ1dJ(θ1)的值大于0时,更新后的 θ 1 \theta_1 θ1减小,越往极小值点靠近,同理,当 d J ( θ 1 ) d θ 1 \frac{\mathrm{d} J\left ( \theta_1 \right )}{\mathrm{d} \theta_1} dθ1dJ(θ1)的值小于0时,更新后的 θ 1 \theta_1 θ1增大,同样是靠近极小值点。
现在来看看 α \alpha α的大小不同会出现什么情况?
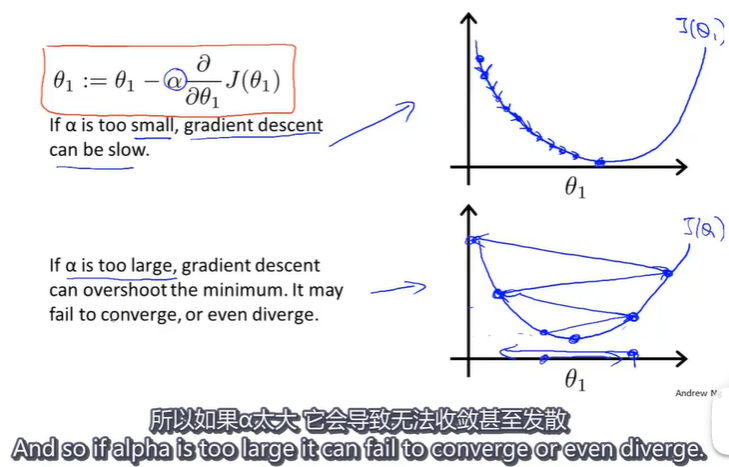
当 α \alpha α太小时,剃度下降可能会很慢;当 α \alpha α很大时,可能会导致无法收敛。
假如现在的 θ 1 \theta_1 θ1已经处于一个局部最优解,梯度下降接下来将会如何?
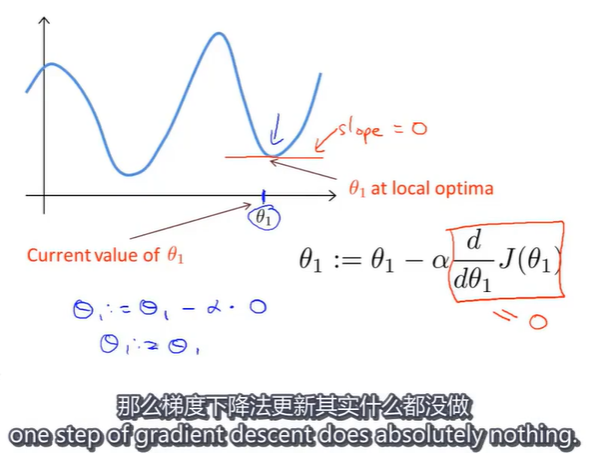
在局部最低点,代价函数的导数值为0,此时梯度下降算法什么都不做,它使你的解始终保持在局部最优点。这也解释了即使学习速率 α \alpha α保持不变梯度下降法也可以收敛到局部最低点的原因。
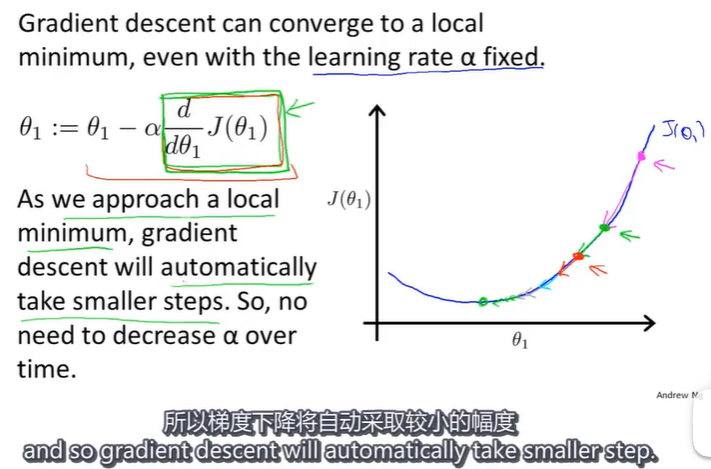
在梯度下降算法中,当我们接近局部最低点时,因为随着 θ 1 \theta_1 θ1的值越靠近局部最低点,代价函数 J ( θ 1 ) J(\theta_1) J(θ1)的导数值越小,最终趋近于0,因此梯度下降法会自动采取更小的幅度去逼近局部最低点,所以实际上没有必要再另外减小 α \alpha α的值。
线性回归的梯度下降


其实就是简单地不断计算代价函数的偏导数,再不断更新参数 θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1的值,直到收敛。
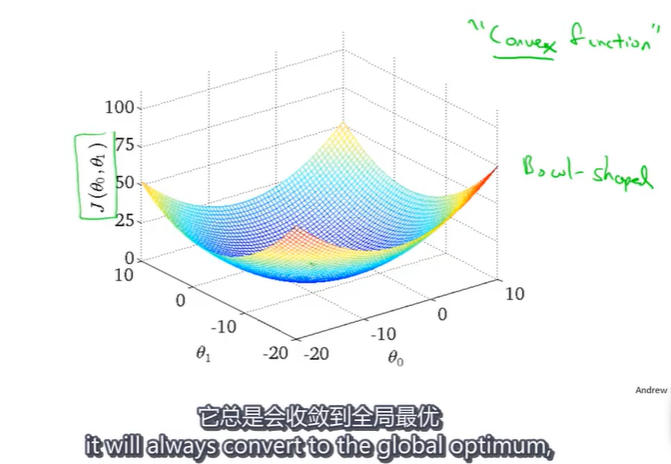
由于线性回归的代价函数 J ( θ 0 , θ 1 ) J(\theta_0,\theta_1) J(θ0,θ1)的函数图像是一个凸函数,使用梯度下降法不存在局部最优解,而是全局最优解。

注意: 以上梯度下降法我们称之为Batch梯度下降法,它意味着每一步梯度下降都遍历了整个训练集的样本,所以在梯度下降中,计算偏导数时我们计算m个样本的总和。















 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









