






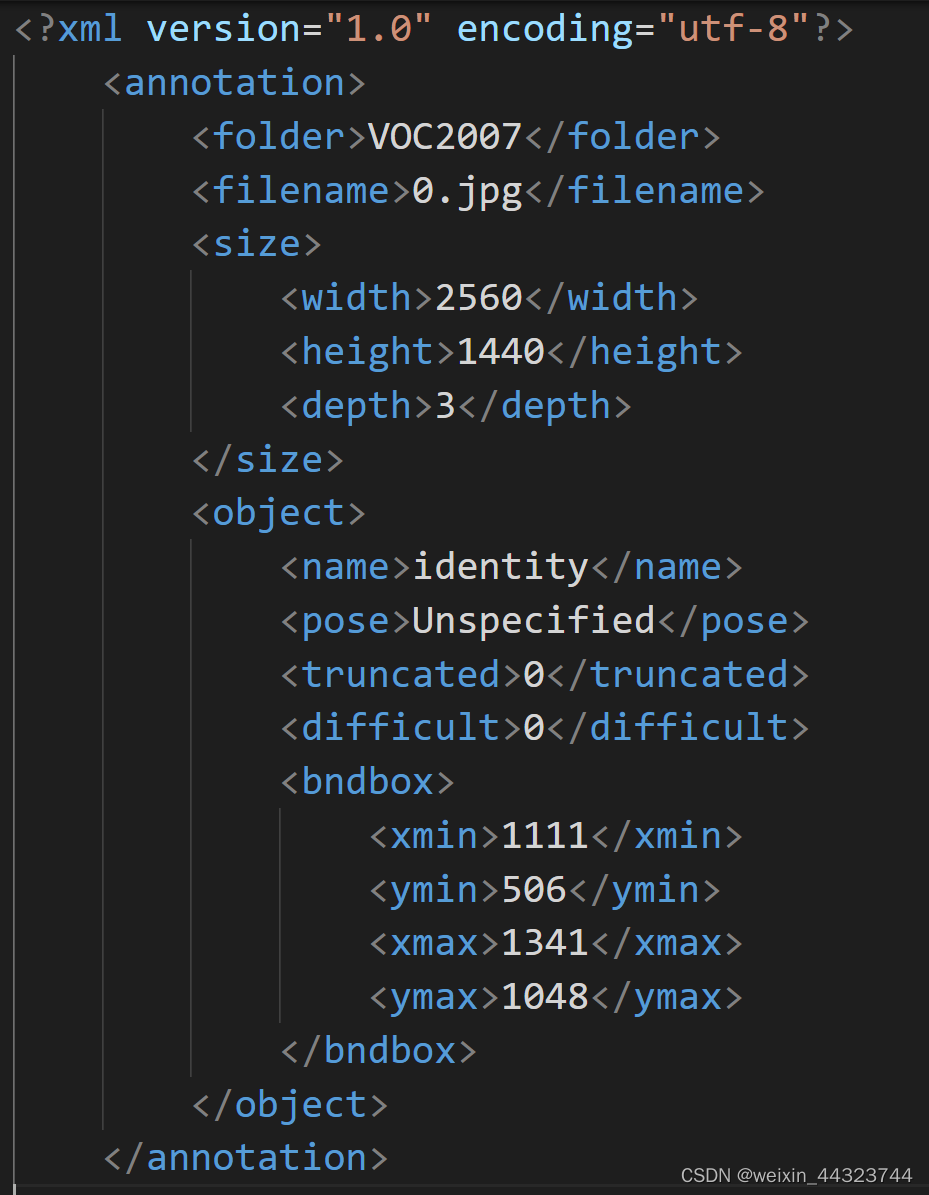
把voc数据格式转为coco数据格式,想把在yolo里使用的数据转为在mmdet中应用数据格式,首先,在yolo里的labels时txt类型如下图1,而在voc转为coco数据格式时,需要先将txt类型转为xml类型,xml类型如下图2所示。

下面将txt类型转为xml:
from xml.dom.minidom import Document
import os
import cv2
def makexml(txtPath,xmlPath,picPath): #读取txt路径,xml保存路径,数据集图片所在路径
dict = {'0':'identity', '1':'action', '2':'abnormal entity'}
files = os.listdir(txtPath)
for i, name in enumerate(files):
print(name)
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile=open(txtPath+name)
txtList = txtFile.readlines()
img = cv2.imread(picPath+name[0:-4]+".jpg")
Pheight,Pwidth,Pdepth=img.shape
for i in txtList:
oneline = i.strip().split(" ")
if len(xmlBuilder.getElementsByTagName("folder")) == 0: # 只让folder size标签记录一次
folder = xmlBuilder.createElement("folder")#folder标签
folderContent = xmlBuilder.createTextNode("VOC2007")
folder.appendChild(folderContent)
annotation.appendChild(folder)
filename = xmlBuilder.createElement("filename")#filename标签
filenameContent = xmlBuilder.createTextNode(name[0:-4]+".jpg")
filename.appendChild(filenameContent)
annotation.appendChild(filename)
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthContent)
size.appendChild(width)
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightContent)
size.appendChild(height)
depth = xmlBuilder.createElement("depth") # size子标签depth
depthContent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthContent)
size.appendChild(depth)
annotation.appendChild(size)
object = xmlBuilder.createElement("object")
picname = xmlBuilder.createElement("name")
nameContent = xmlBuilder.createTextNode(dict[oneline[0]])
picname.appendChild(nameContent)
object.appendChild(picname)
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose)
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
bndbox = xmlBuilder.createElement("bndbox")
xmin = xmlBuilder.createElement("xmin")
mathData=int(((float(oneline[1]))*Pwidth+1)-(float(oneline[3]))*0.5*Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
ymin = xmlBuilder.createElement("ymin")
mathData = int(((float(oneline[2]))*Pheight+1)-(float(oneline[4]))*0.5*Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
xmax = xmlBuilder.createElement("xmax")
mathData = int(((float(oneline[1]))*Pwidth+1)+(float(oneline[3]))*0.5*Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
ymax = xmlBuilder.createElement("ymax")
mathData = int(((float(oneline[2]))*Pheight+1)+(float(oneline[4]))*0.5*Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
f = open(xmlPath+name[0:-4]+".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
# txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
makexml("data/splited1/labels/train/","data/splited1/xml/val/","data/splited1/images/train/")下面将xml类型转为json格式:
在转换之前,先将xml文件名放在一个txt文件里
# create_xml_list.py
import os
xml_list = os.listdir('data/splited1/xml/train')
with open('data/splited1/xml_list.txt','a') as f:
for i in xml_list:
if i[-3:]=='xml':
f.write(str(i)+'\n')
下面就可以将xml转为json
# voc2coco.py
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = {}
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
PRE_DEFINE_CATEGORIES = {'identity':0, 'action':1, 'abnormal entity':2}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = os.path.splitext(filename)[0]
return int(filename)
except:
raise NotImplementedError('Filename %s is supposed to be an integer.'%(filename))
def convert(xml_list, xml_dir, json_file):
list_fp = open(xml_list, 'r')
json_dict = {"images":[], "type": "instances", "annotations": [],
"categories": []}
categories = PRE_DEFINE_CATEGORIES
bnd_id = START_BOUNDING_BOX_ID
for line in list_fp:
line = line.strip()
print("Processing %s"%(line))
xml_f = os.path.join(xml_dir, line)
tree = ET.parse(xml_f)
root = tree.getroot()
path = get(root, 'path')
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
print(root)
filename = get_and_check(root, 'filename', 1).text
else:
raise NotImplementedError('%d paths found in %s'%(len(path), line))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width,
'id':image_id}
json_dict['images'].append(image)
## Cruuently we do not support segmentation
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bndbox, 'xmin', 1).text) - 1
ymin = int(get_and_check(bndbox, 'ymin', 1).text) - 1
xmax = int(get_and_check(bndbox, 'xmax', 1).text)
ymax = int(get_and_check(bndbox, 'ymax', 1).text)
assert(xmax > xmin)
assert(ymax > ymin)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width*o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox':[xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
list_fp.close()
if __name__ == '__main__':
if len(sys.argv) <= 1:
print('3 auguments are need.')
print('Usage: %s XML_LIST.txt XML_DIR OUTPU_JSON.json'%(sys.argv[0]))
exit(1)
# xml_list.txt xml_folder coco.json
convert(sys.argv[1], sys.argv[2], sys.argv[3])
运行上面的代码 python voc2json.py 后面加上三个路径xml_list.txt ,xml_folder ,coco.json
生成的json里的内容



重点,这里将txt转为xml时,让folder,size这些node只出现一次,否则在xml转json时会报错。
所以,我这里些的txt转xml的代码是只让让folder,size这些node只出现了一次。
但是对于xml转为json时,没有划分train、val、test。图片也没有划分。
 https://blog.csdn.net/qq_40502460/article/details/116564254?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-116564254-blog-109508645.pc_relevant_downloadblacklistv1&spm=1001.2101.3001.4242.1&utm_relevant_index=2
https://blog.csdn.net/qq_40502460/article/details/116564254?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-116564254-blog-109508645.pc_relevant_downloadblacklistv1&spm=1001.2101.3001.4242.1&utm_relevant_index=2














 3277
3277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









