






导读
个人学习笔记
有些开源的算法数据集用的是coco格式,我们用标注软件标注自己的数据时,可能会按VOC格式来标注,这时候为了适配开源算法,就需把VOC转COCO格式。
VOC数据集
做目标检测时候需用到的VOC文件如下图:
JPEGImage中装的是图片
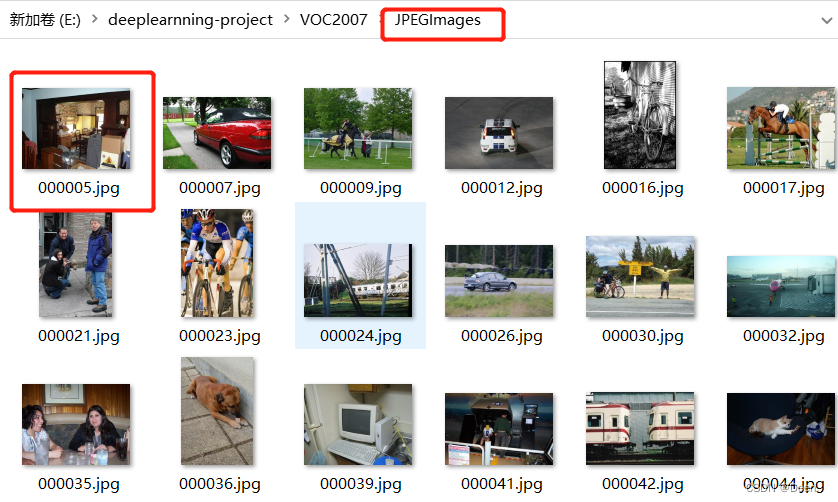
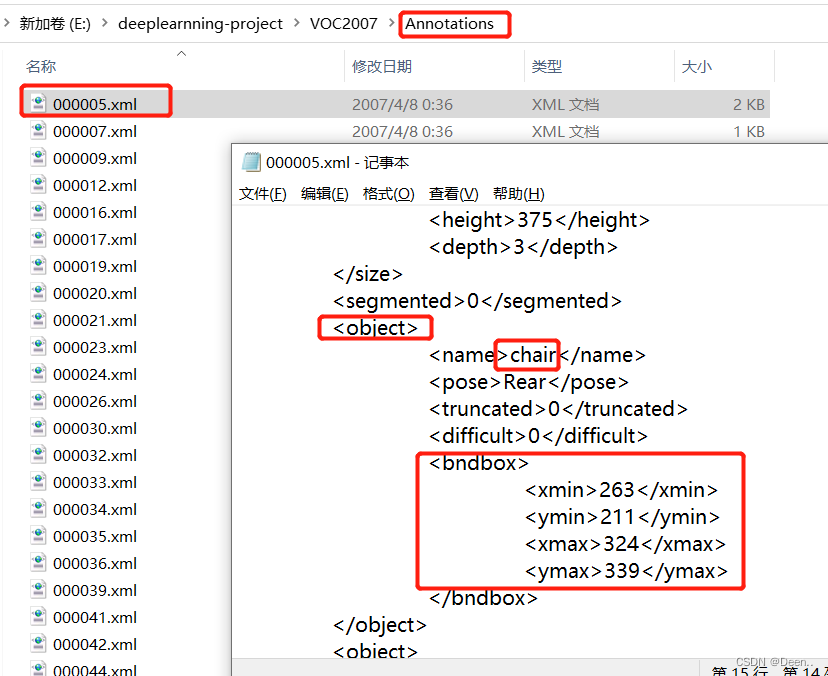
Anonotations中装的是图片对应的标注:
如下图5张这种图片中有一把椅子。
COCO数据集
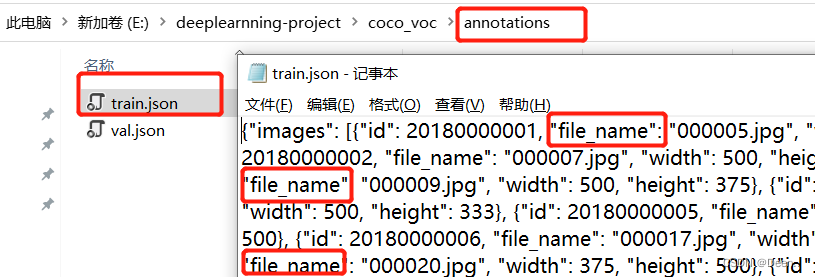
下图是将VOC转coco后的格式,coco数据集的图片跟VOC是一样的,但是他的标注全部放在一个annotations文件中的单一json文件中

而不是一张图片,一个标注文件。
转换
首先获取VOC数据集的训练集跟验证集,这个训练集跟验证集可以按自己要求去划分。VOC数据集中的Imageset文件里有划分好的txt文件,这边直接拿划分好的来演示:
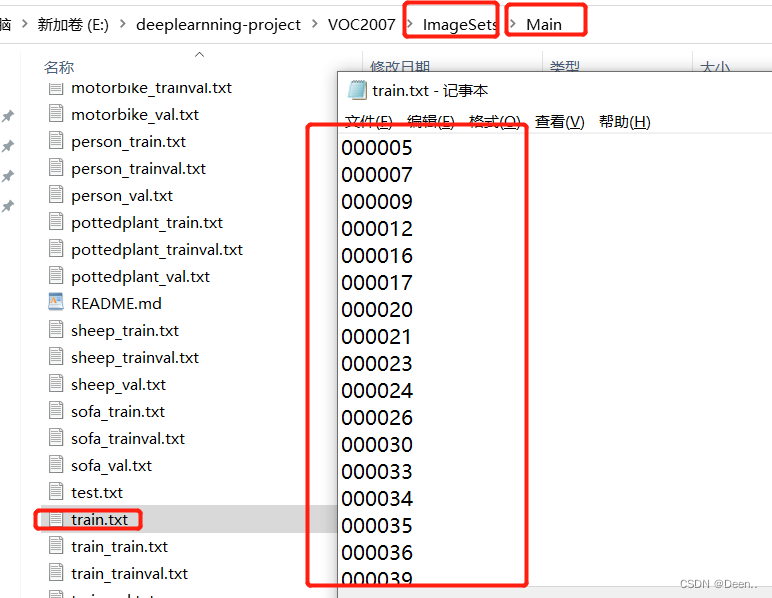
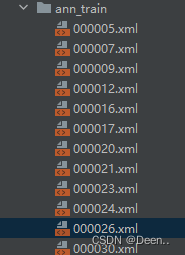
将训练集和验证集所有标注文件(xml格式)放到一个文件夹下面:
根据划分好的train.txt跟text.text文件将train跟val的编号跟他们对应的xml文件放到ann_train跟ann_val文件夹里
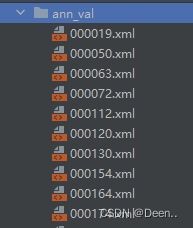
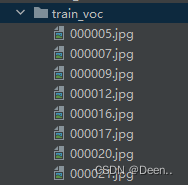
将训练集和验证集所有图片文件(jpg格式)放到一个文件夹下面:
根据txt文件里的train跟val的编号,将对应的jpg文件放到train_voc跟val_voc文件夹里
代码如下:
根据数据源的位置,去重新修改def init(self):下的内容。
import os
import shutil
# the path is you original file directory
# the newpath is the new directory
class BatchCopy():
def __init__(self):
self.path = r'E:\deeplearnning-project\VOCdevkit\VOC2007\Annotations' ####voc是将所有xml文件都放在同一目录下
self.image_path = r'E:\deeplearnning-project\VOCdevkit\VOC2007\JPEGImages'####voc的图片位置
self.newpath = r'E:\deeplearnning-project\voc2coco\ann_val' ####将训练集的xml文件单独放一个目录
self.newiamge_path = r'E:\deeplearnning-project\voc2coco\val_voc'####voc转coco后的图片分类位置
self.txt = r'E:\deeplearnning-project\voc2coco\2007_val.txt' ###训练集或验证集的txt文件位置
def copy_file(self):
if not os.path.exists(self.newpath):
os.makedirs(self.newpath)
else:
shutil.rmtree(self.newpath)
if not os.path.exists(self.newiamge_path):
os.makedirs(self.newiamge_path)
filelist = os.listdir(self.path) # file list in this directory
# print(len(filelist))
test_list = loadFileList(self.txt)
# print(len(test_list))
for f in filelist:
filedir = os.path.join(self.path, f)
(shotname, extension) = os.path.splitext(f)
if str(shotname) in test_list:
filedir_image = os.path.join(self.image_path, shotname) + '.jpg'
# print('success')
shutil.copyfile(str(filedir_image),os.path.join(self.newiamge_path,shotname)+'.jpg')
shutil.copyfile(str(filedir), os.path.join(self.newpath, f))
# load the list of train/test file list
def loadFileList(txt):
filelist = []
f = open(txt)
lines = f.readlines()
for line in lines:
line = line.strip('\r\n') # to remove the '\n' for test.txt, '\r\n' for tainval.txt
line = str(line)
line = os.path.basename(line)
_, file_suffix = os.path.splitext(line)
filelist.append(_)
f.close()
# print(filelist)
return filelist
if __name__ == '__main__':
demo = BatchCopy()
demo.copy_file()
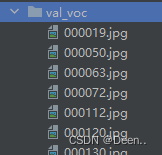
这时候已经完成coco格式里图片分类成训练集跟验证集的工作了:
最后一步,将标注里的一堆训练集或验证集的xml文件合并改写成一个json文件:
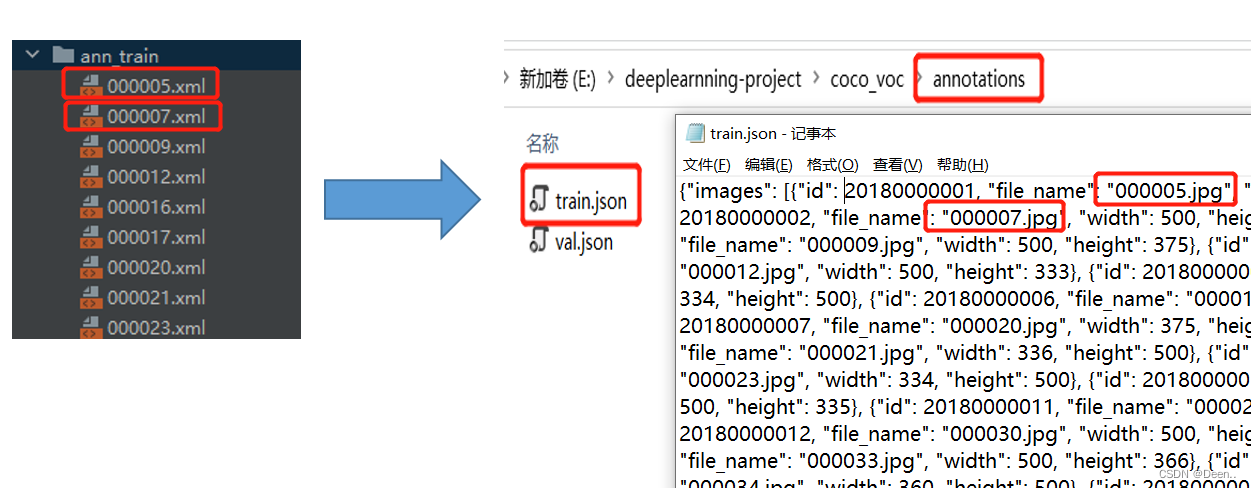
ann_train跟ann_val文件夹里的xml文件转成coco的json模式
代码如下: 只要改动main里的内容即刻
import xml.etree.ElementTree as ET
import os
import json
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 20180000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
for f in os.listdir(xml_path):
if not f.endswith('.xml'):
continue
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# elem is <folder>, <filename>, <size>, <object>
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = elem.text
if file_name in category_set:
raise Exception('file_name duplicated')
# add img item only after parse <size> tag
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
# subelem is <width>, <height>, <depth>, <name>, <bndbox>
for subelem in elem:
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
# option is <xmin>, <ymin>, <xmax>, <ymax>, when subelem is <bndbox>
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(option.text)
# only after parse the <object> tag
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
if __name__ == '__main__':
# 只需要改动这两个参数就行了
xml_path = r'E:\deeplearnning-project\voc2coco\ann_val' # 这是xml文件所在的地址
json_file = r'E:\deeplearnning-project\voc2coco\val.json' # 这是你要生成的json文件
parseXmlFiles(xml_path)
json.dump(coco, open(json_file, 'w'))
















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









