







Unity3D开发AI桌面精灵/宠物系列 【六】 人物模型 语音口型同步 LipSync 、梅尔频谱MFCC技术 C# 语言开发
该系列主要介绍怎么制作AI桌面宠物的流程,我会从项目开始创建初期到最终可以和AI宠物进行交互为止,项目已经开发完成,我会仔细梳理一下流程,分步讲解。 这篇文章主要讲关于人物模型 语音口型同步技术。
提示:内容纯个人编写,欢迎评论点赞,来指正我。
文章目录
前言
本篇内容主要讲Unity开发桌面宠物的大模型交互功能,大家感兴趣也可以了解一下这个开发方向,目前还是挺有前景的。
下面让我们出发吧 ------------>----------------->
一、语音口型同步LipSync技术概述
人物语音口型同步(Lip Sync)是一种技术,用于确保动画或虚拟人物的口型与配音或语音内容精确匹配。这种技术广泛应用于动画电影、视频游戏、虚拟现实、增强现实以及实时视频会议等领域,以增强角色的真实感和沉浸感。
①技术原理
人物语音口型同步通常通过分析语音信号的音素(Phoneme)来实现。音素是语言中最小的语音单位,每个音素对应特定的口型。系统通过语音识别技术将语音分解为音素序列,然后根据音素驱动角色的面部模型,生成相应的口型动画。
②实现方法
基于规则的方法:通过预定义的规则将音素映射到特定的口型。这种方法需要手动调整每个音素对应的口型,适用于简单的场景,但缺乏灵活性。
基于机器学习的方法:利用深度学习模型(如卷积神经网络或循环神经网络)自动学习语音与口型之间的映射关系。这种方法可以处理更复杂的语音和口型变化,适用于高质量的口型同步需求。
实时口型同步:在实时应用中(如视频会议或虚拟主播),系统需要快速处理语音并生成相应的口型动画。这通常需要高效的算法和硬件支持,以确保低延迟和高精度。
③应用场景
动画制作:在动画电影和电视剧中,人物语音口型同步用于确保角色的口型与配音完美匹配,提升观众的观影体验。
游戏开发:在视频游戏中,口型同步技术用于增强角色的互动性和真实感,使玩家更沉浸于游戏世界。
虚拟现实和增强现实:在VR和AR应用中,口型同步技术用于创建逼真的虚拟人物,提升用户的沉浸感。
实时视频会议:在视频会议中,口型同步技术可以用于虚拟形象或增强现实效果,使远程沟通更加自然和生动。
④技术挑战
多语言支持:不同语言的音素和口型差异较大,需要针对每种语言进行优化。
情感表达:除了口型,面部表情和情感表达也是重要因素,需要综合处理。
实时性:在实时应用中,系统需要在极短的时间内完成语音分析和口型生成,对算法和硬件性能要求较高。
人物语音口型同步技术的发展不断推动着动画、游戏和虚拟现实等领域的进步,为用户带来更加真实和沉浸的体验。

二、Unity开发准备阶段
1.Unity平台
- 该系列全部使用Unity2021.3.44开发;
- 该系列前后文章存在关联,不懂的可以看前面文章;
- 该系列完成之后我会上传源码工程,着急的小伙伴可以自己写框架,我就先编写各模块的独立功能。
2.插件:下载地址
3.示例:中文
- 元音
a:发音时,口张大,舌尖抵住下齿背,舌面中部稍微隆起,声带振动。如“啊”。
o:发音时,口半开,舌尖抵住下齿背,舌面后部隆起,声带振动。如“哦”。
e:发音时,口半开,舌尖抵住下齿背,舌面后部稍微隆起,声带振动。如“鹅”。
i:发音时,口微开,舌尖抵住下齿背,舌面前部隆起,声带振动。如“衣”。
u:发音时,口微开,舌尖抵住下齿背,舌面后部隆起,声带振动。如“乌”。
ü:发音时,口微开,舌尖抵住下齿背,舌面前部隆起,声带振动。如“迂”。
- 辅音
b:发音时,双唇紧闭,然后突然张开,气流冲出,声带不振动。如“玻”。
p:发音时,双唇紧闭,然后突然张开,气流冲出,声带不振动。如“坡”。
m:发音时,双唇紧闭,气流从鼻腔流出,声带振动。如“摸”。
f:发音时,上齿和下唇接触,气流从唇齿间摩擦而出,声带不振动。如“佛”。
d:发音时,舌尖抵住上齿龈,气流冲出,声带不振动。如“的”。
t:发音时,舌尖抵住上齿龈,气流冲出,声带不振动。如“特”。
n:发音时,舌尖抵住上齿龈,气流从鼻腔流出,声带振动。如“呢”。
l:发音时,舌尖抵住上齿龈,气流从舌两侧流出,声带振动。如“勒”。
g:发音时,舌根抵住软腭,气流冲出,声带振动。如“哥”。
k:发音时,舌根抵住软腭,气流冲出,声带不振动。如“科”。
h:发音时,舌根靠近软腭,气流从舌根和软腭之间摩擦而出,声带不振动。如“喝”。
j:发音时,舌面前部抵住硬腭,气流从舌面和硬腭之间摩擦而出,声带不振动。如“基”。
q:发音时,舌面前部抵住硬腭,气流从舌面和硬腭之间摩擦而出,声带不振动。如“七”。
x:发音时,舌面前部靠近硬腭,气流从舌面和硬腭之间摩擦而出,声带不振动。如“希”。
zh:发音时,舌尖抵住硬腭前部,气流从舌尖和硬腭之间摩擦而出,声带不振动。如“知”。
ch:发音时,舌尖抵住硬腭前部,气流从舌尖和硬腭之间摩擦而出,声带不振动。如“吃”。
sh:发音时,舌尖靠近硬腭前部,气流从舌尖和硬腭之间摩擦而出,声带不振动。如“诗”。
r:发音时,舌尖靠近硬腭前部,气流从舌尖和硬腭之间摩擦而出,声带振动。如“日”。
z:发音时,舌尖抵住上齿龈,气流从舌尖和上齿龈之间摩擦而出,声带不振动。如“资”。
c:发音时,舌尖抵住上齿龈,气流从舌尖和上齿龈之间摩擦而出,声带不振动。如“雌”。
s:发音时,舌尖靠近上齿龈,气流从舌尖和上齿龈之间摩擦而出,声带不振动。如“思”。
- 复韵母
ai:发音时,先发“a”,然后舌尖抵住下齿背,舌面前部稍微隆起,向“i”滑动,声音由低到高。如“爱”。
ei:发音时,先发“e”,然后舌尖抵住上齿龈,舌面前部稍微隆起,向“i”滑动,声音由低到高。如“飞”。
ui:发音时,先发“u”,然后舌尖抵住下齿背,舌面前部稍微隆起,向“i”滑动,声音由低到高。如“归”。
ao:发音时,先发“a”,然后舌尖抵住下齿背,舌面后部稍微隆起,向“o”滑动,声音由低到高。如“高”。
ou:发音时,先发“o”,然后舌尖抵住下齿背,舌面后部稍微隆起,向“u”滑动,声音由低到高。如“狗”。
iu:发音时,先发“i”,然后舌尖抵住下齿背,舌面前部稍微隆起,向“u”滑动,声音由低到高。如“游”。
ie:发音时,先发“i”,然后舌尖抵住下齿背,舌面前部稍微隆起,向“e”滑动,声音由低到高。如“爷”。
üe:发音时,先发“ü”,然后舌尖抵住下齿背,舌面前部稍微隆起,向“e”滑动,声音由低到高。如“月”。
er:发音时,舌尖卷起,抵住硬腭,舌面中部稍微隆起,发出“er”的音。如“儿”。
- 鼻韵母
an:发音时,先发“a”,然后舌尖抵住上齿龈,舌面中部稍微隆起,发出“n”的音。如“安”。
en:发音时,先发“e”,然后舌尖抵住上齿龈,舌面中部稍微隆起,发出“n”的音。如“恩”。
in:发音时,先发“i”,然后舌尖抵住上齿龈,舌面中部稍微隆起,发出“n”的音。如“因”。
un:发音时,先发“u”,然后舌尖抵住上齿龈,舌面中部稍微隆起,发出“n”的音。如“温”。
ün:发音时,先发“ü”,然后舌尖抵住上齿龈,舌面中部稍微隆起,发出“n”的音。如“云”。
ang:发音时,先发“a”,然后舌尖抵住上齿龈,舌面后部稍微隆起,发出“ng”的音。如“昂”。
eng:发音时,先发“e”,然后舌尖抵住上齿龈,舌面后部稍微隆起,发出“ng”的音。如“灯”。
ing:发音时,先发“i”,然后舌尖抵住上齿龈,舌面后部稍微隆起,发出“ng”的音。如“丁”。
ong:发音时,先发“o”,然后舌尖抵住上齿龈,舌面后部稍微隆起,发出“ng”的音。如“红”
- 上述操作很简单
- 重点来了
三、uLipSync使用方法
1. 模型重构
- 重构模型 BlendShape组件
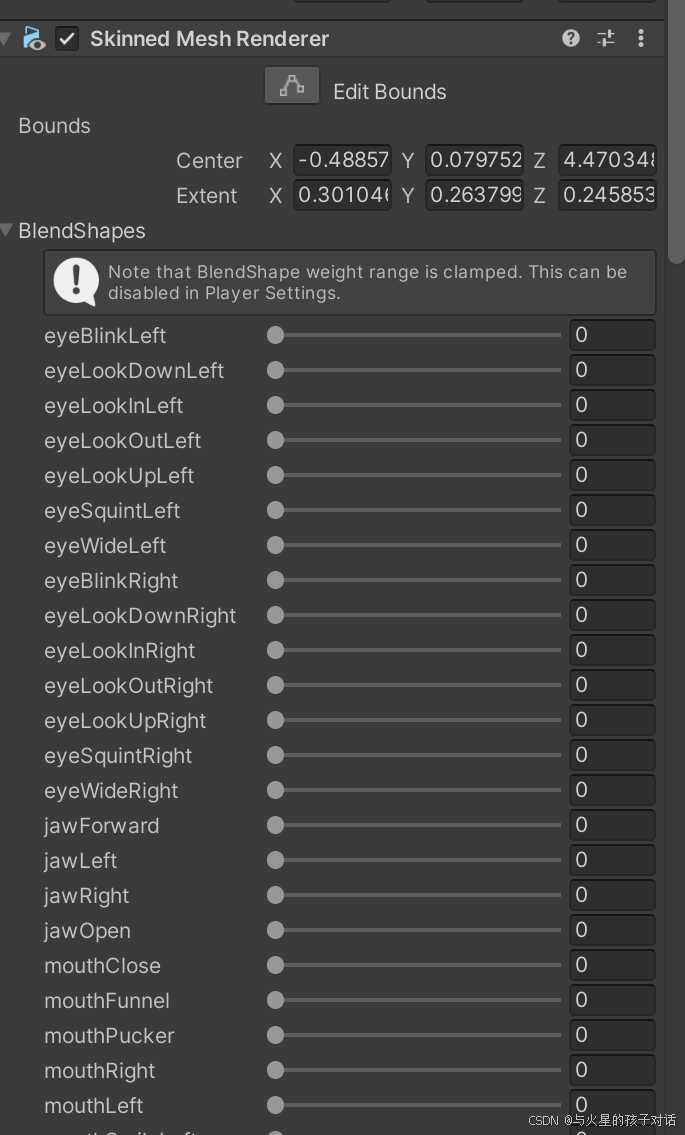
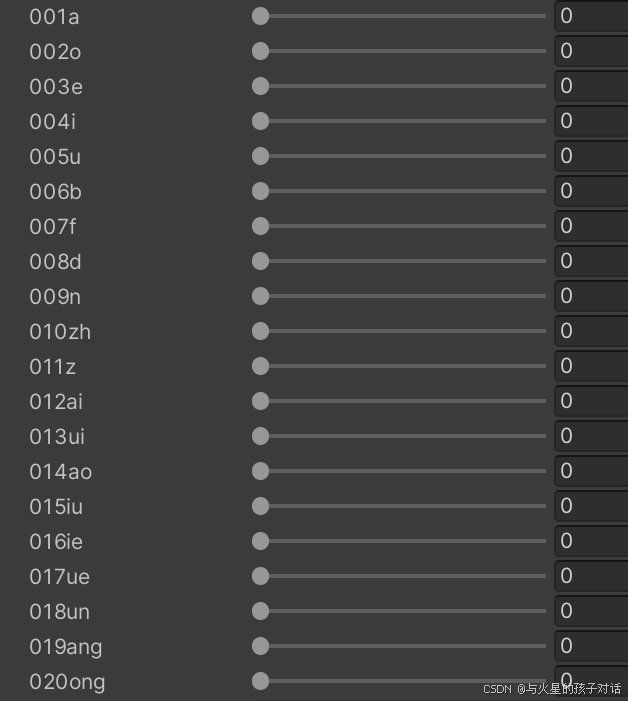
- 中文加入以下组件:
- 英文加入以下组件:
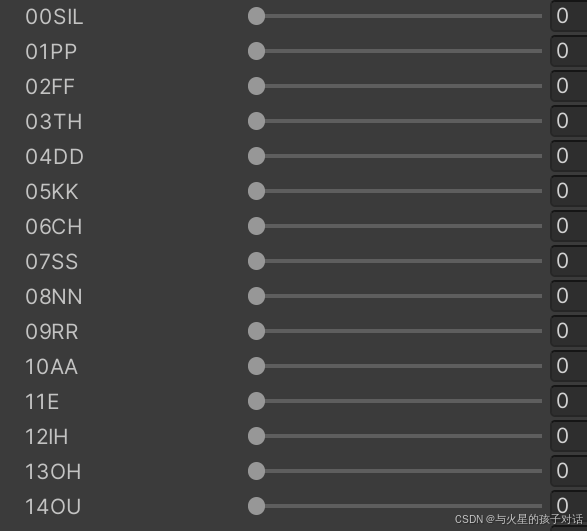
- 以上组件均为美工制作模型时添加,后续要用到,也可以用基础自带的52个BlendShape组件,只不过效果不是很好。
2. 导入插件
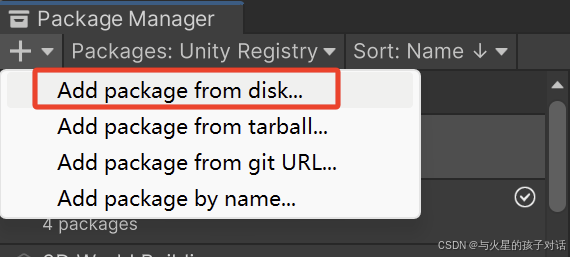
- 导入成功
3. 添加LipSync组件
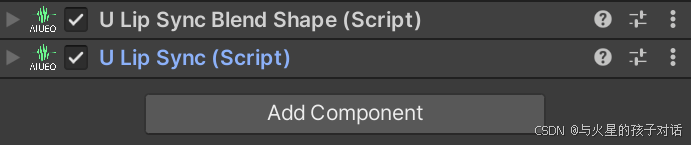
- 在模型根节点添加这两个组件。
4. 组件使用详解
1. uLipsyncBlendShape 组件
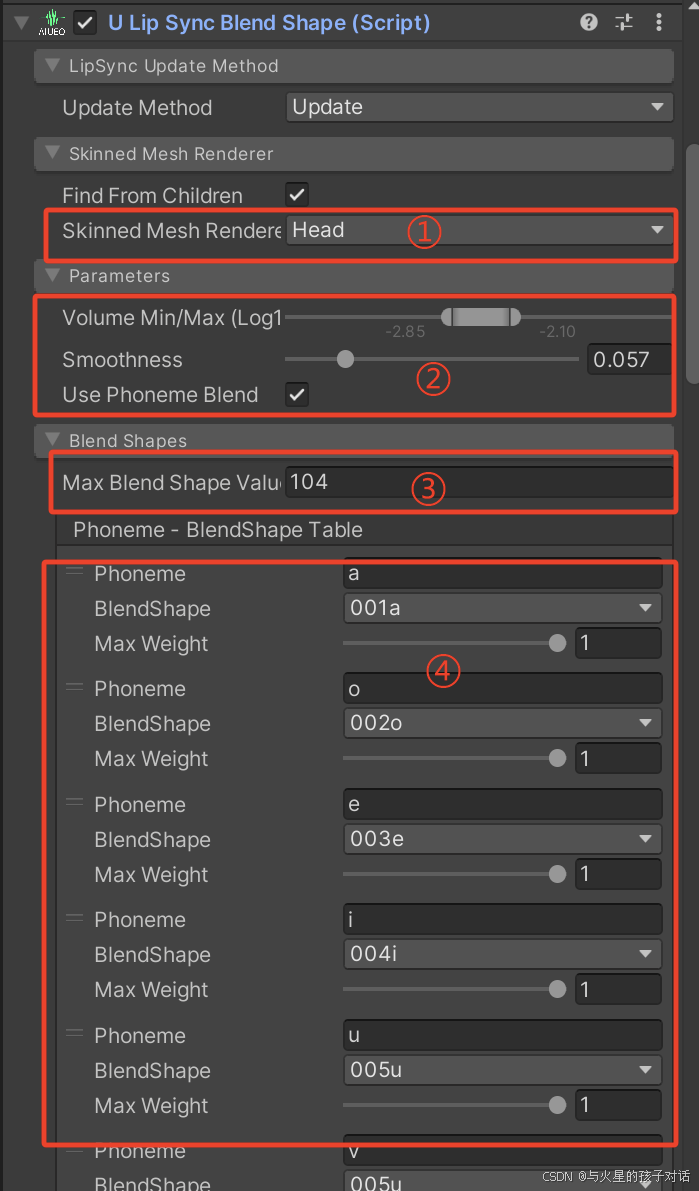
- ① 选择你的模型上带有BlendShape组件的物体
- ② 调节口型变化的平滑度和最大最小值,根据需求自行调节
- ③ BlendShape全部组件的值大小,默认是100,根据需求调整幅度
- ④ 绑定你的美术资源上添加的BlendShape组件对应的某个音素,并自己命名区分
2. uLipsync 组件
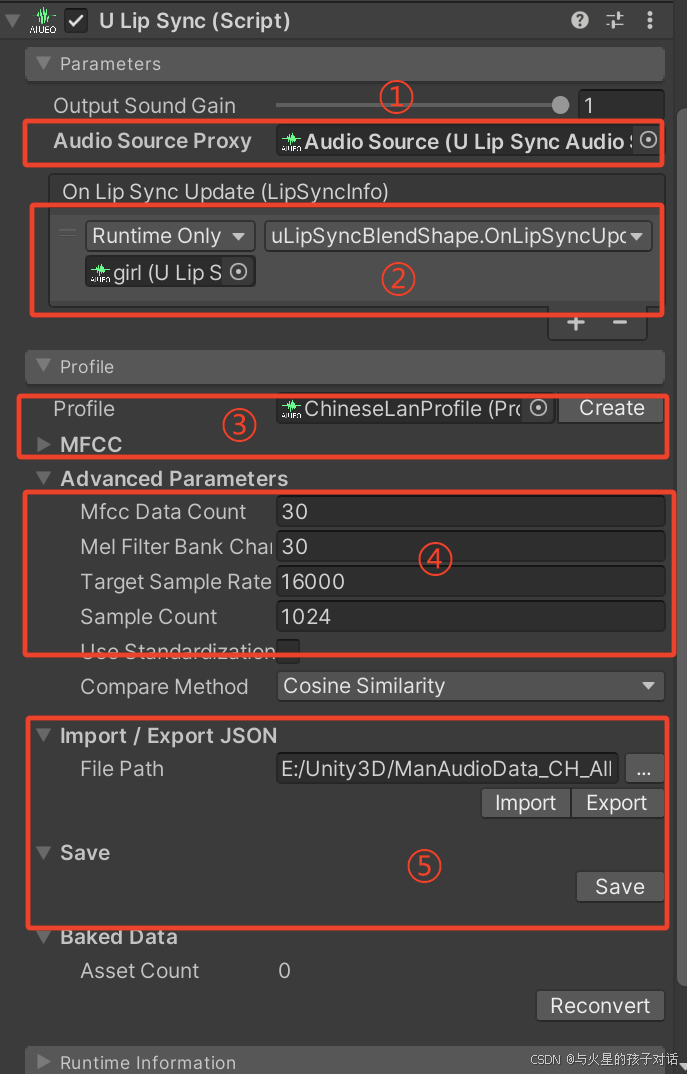
- ① 选择你的声音来源,新建个AudioSource拖进来
- ② 选择当前物体,并选择OnLipSyncUpdate方法,表示实时运行检测
- ③ 可以自己导入保存好的数据,也可以新建,接下来重点讲MFCC
- ④ 调整数据大小和采样率的,默认我这种就可以
- ⑤ 可以将数据保存到本地,其他资源可以直接使用,也可以导入其他数据
2. MFCC 技术
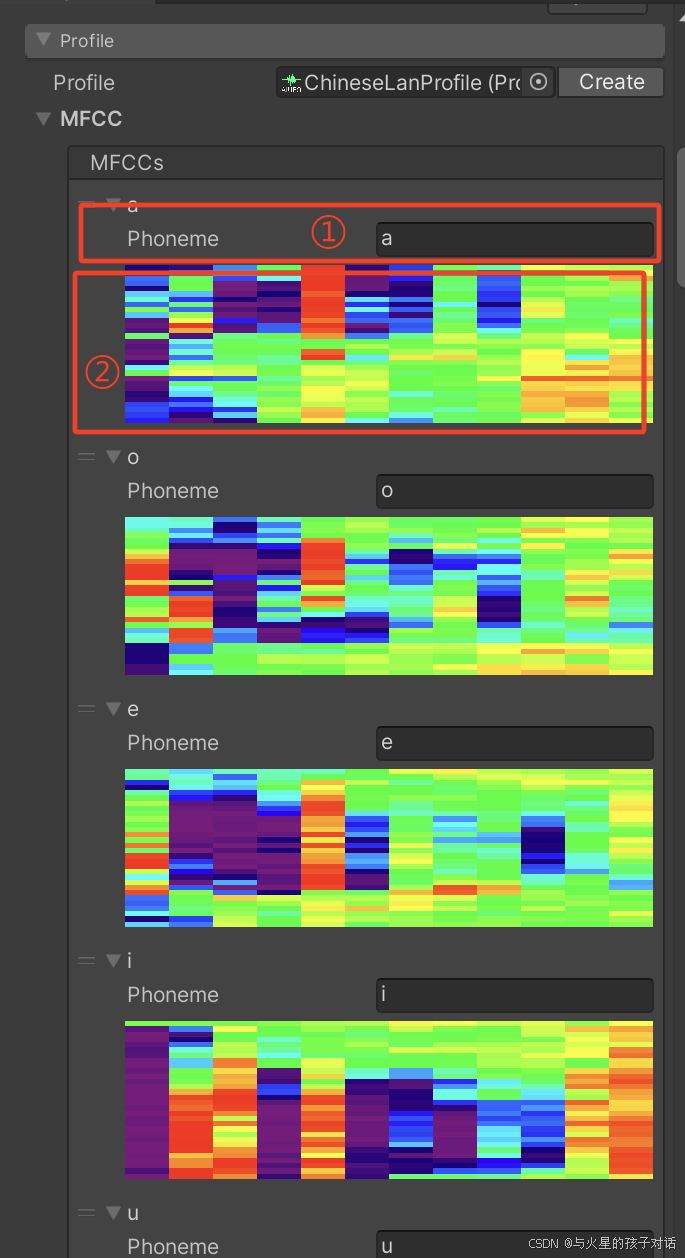
- ① 填入上个阶段自己命名的音节,
- ② 录制的频谱
那么怎么录制频谱呢?
- ① 首先网上找到 a、o、e、i、u、v等音素的读音片段,可以是mp4或者其他格式都行,我是在汉语拼音网上找的,读音种类的数据越多越精准。
- ② 导入到Unity中
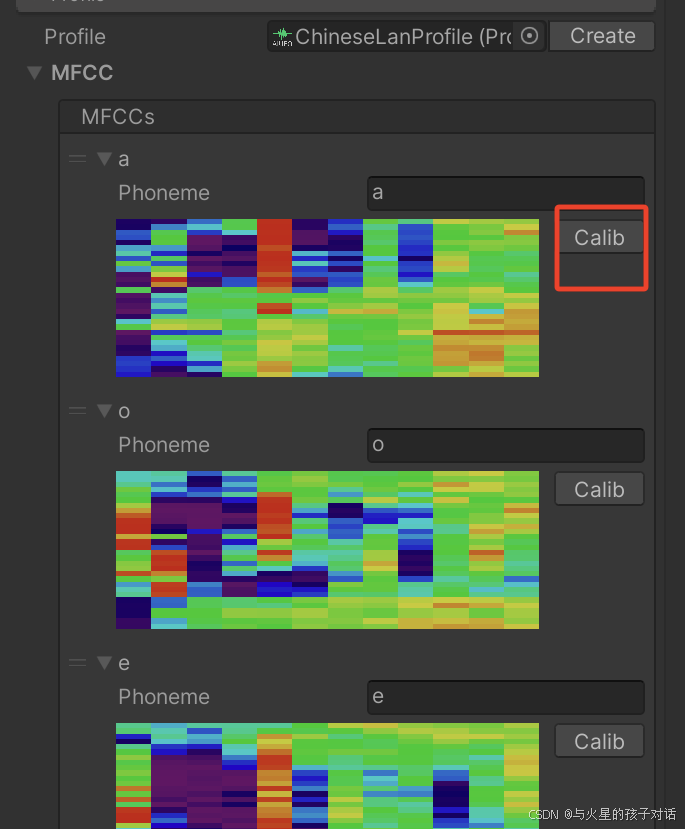
接下来就是录制了!
- ① 首先运行Unity ,你会发现多了个按钮 Calib
- ② 第二步,在音频组件上播放一个音素,循环播放
- ③ 第三步,点击Calib 按钮,长按两三秒,看到MFCC上有稳定均匀的频谱写入就代表成功了。
- ④ 第四步,重复前面的操作,将所有音素依次录入
- ⑤ 可以点击保存,下次可以直接使用
3. MFCC 频谱中文数据提供
下面是我本人训练的MFCC数据的Json文件可以导入直接用:

训练不好的小伙伴私我,这个文件数据太大,不知道以什么格式可以上传。
4. 运行查看效果,人物口型和声音同步,并实时变化,中英文的训练是一样的。
然后就,大功告成了!!!
- 该系列基本功能差不多就完成了,就完结了,接下来我会将这些功能搭一下框架,或者把其他平台的接入也展示出来。后续看计划~
四. 完结
- 大家可以从第一节开始学习,完整流程基本已经实现,现在可以实现对话了。
- 下一期更新暂定:
① 更新框架
② 其他平台的功能接入
二选一哦!- 评论告诉我,下一期更新什么

比心啦 ❥(^_-)

总结
- 提示: 大家根据需求来做功能,后续继续其他功能啦,不懂的快喊我。
- 大家可以在评论区讨论其他系列下一期出什么内容,这个系列会继续更新的
- 点赞收藏加关注哦~ 蟹蟹




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











