







在之前的学习中,我们知道对于训练集X进行归一化有利于我们把代价函数从扁平拉圆,便于我们训练。
那我们想一下,如果对每层神经网络的输出,我都搞一个归一化,是不是会提升我们的学习效果呢?
Batch Norm技术就出现了
实现方式
对于之前的每个神经元,我们计算z=wTa_pre, a=g(z)。在Batch Norm中,对于每一个神经元:
z=wTa_pre (没有b的原因是反正都要归一化,无论b取何值,都会体现在下面的平均值当中被减掉)
对于一组mini-batch上的所有数据,我们计算出Z的平均值:
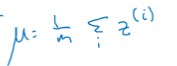
计算出Z的方差:
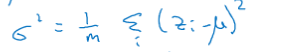
对其进行归一化,得到
Z_norm = (Z-μ)/sqrt(σ2+ε), 这里的ε是一个小常数(1e-8),为的是防止除0
为了避免始终保持均值为0,方差为1,失去活力,对每个Z_norm
Z~= Z_norm*α +β
这里的α和β起到调整每个神经元均值和方差的作用,而β也能起到之前删去的b的作用。注意对于不同的神经元α,β均不同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









