






最近,遇到了使用numpy来储存字典数据的情况(因为与pickle相比numpy更节省空间),但是读取的时候就遇到了问题,源代码`test1 = np.load(‘test1.npz’)``。
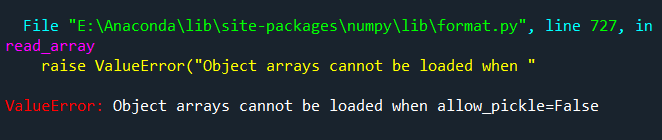
在查询原因后,发现好像是numpy版本的问题,把numpy版本降低到1.16以下就可以解决,但是这种方法感觉很麻烦,于是尝试在原来读取的基础上加入allow_pickle=True,变为test1 = np.load('test1.npz', allow_pickle=True),成功读取。
此外,使用np.savez()存储字典,是相当于把字典先转为了ndarray类型,在读取时必须加[()]变为target_all_t1 = test1['arr_1'][()],才能顺利读取出所需要的字典类型。















 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









