







1 、客户端环境准备

1
)找到资料包路径下的
Windows
依赖文件夹,拷贝
hadoop-3.1.0
到非中文路径(比如
d:\
)。
2
)配置
HADOOP_HOME
环境变量

3
)配置
Path
环境变量。
注意:如果环境变量不起作用,可以重启电脑试试。
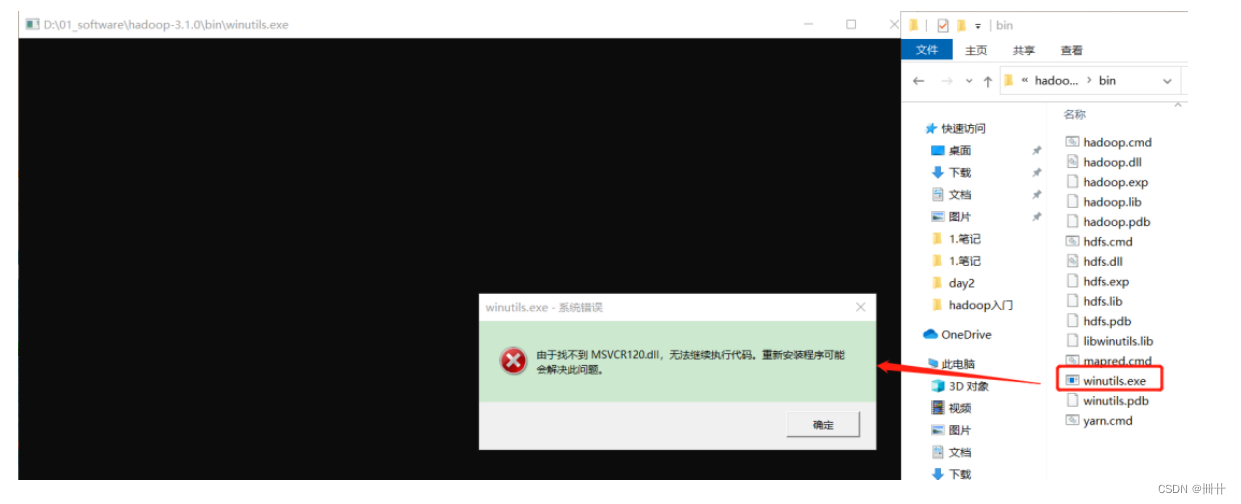
验证
Hadoop
环境变量是否正常。双击
winutils.exe,如果报如下错误。说明缺少微软运行库(正版系统往往有这个问题)。再资料包里面有对应的微软运行库安装包双击安装即可。
4)在 IDEA 中创建一个 Maven 工程 HdfsClientDemo,并导入相应的依赖坐标+日志添加
创建Maven工程以及进行相关配置



注意:这里的Maven博主没有用系统默认的那个,那个下载地址在国外,下载依赖十分慢,同时那个自带的Maven跟很多的jar包的都不兼容,不好用,博主重新从官网下载了个Maven并配置了
具体配置步骤请参考博客
注:Maven版本过高 ,会使IDEA版本不兼容。
4)在 IDEA 中创建一个 Maven 工程 HdfsClientDemo,并导入相应的依赖坐标+日志添加
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
注:下图中出现红色,点击刷新按钮,则会安装对应的包

在项目的 src/main/resources
目录下,新建一个文件,命名为“
log4j.properties
”,在文件
中填入
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n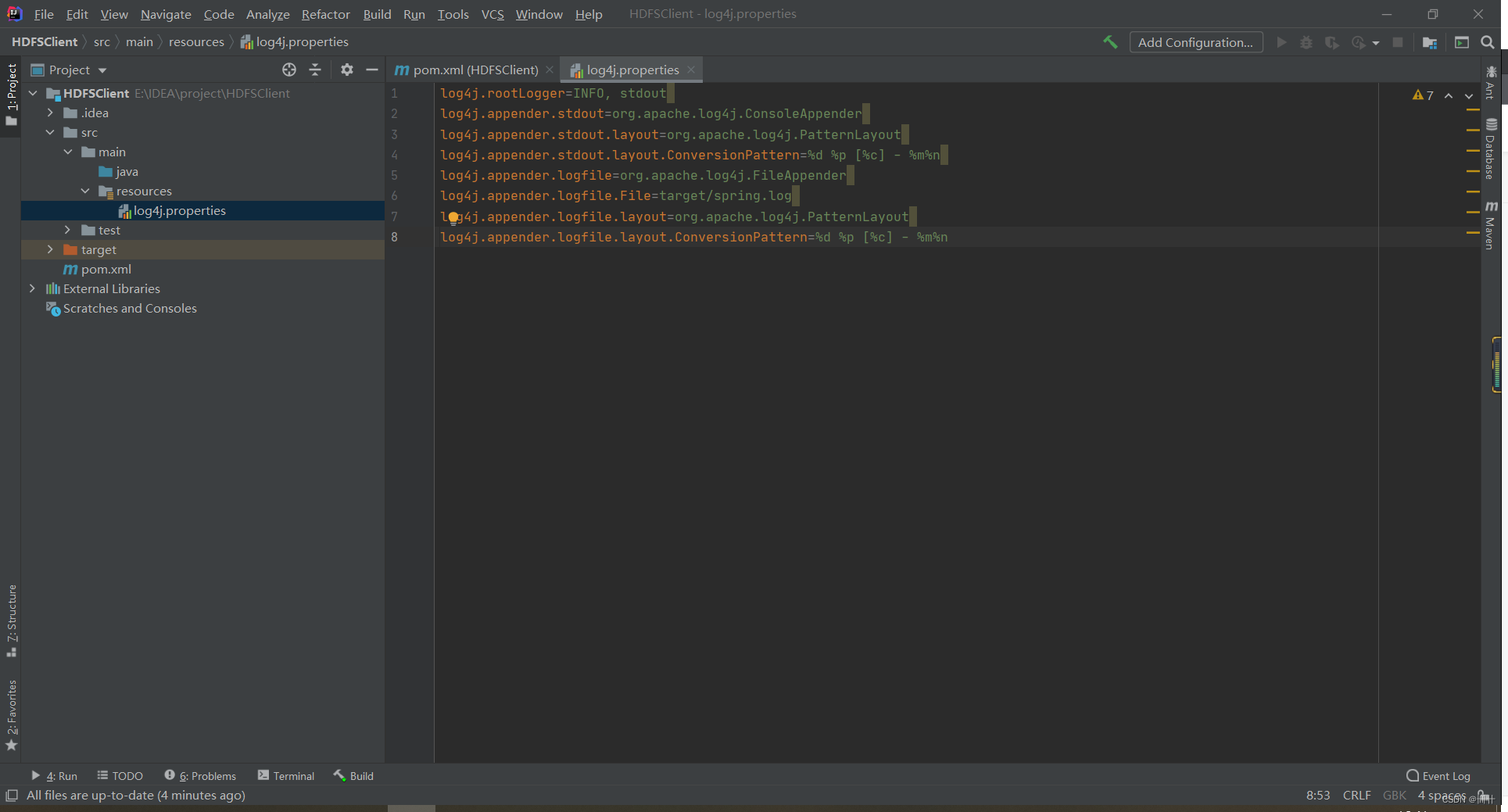
5
)创建包名:
com.atguigu.hdfs
6
)创建
HdfsClient
类
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, URISyntaxException,
InterruptedException {
// 1 获取文件系统
Configuration configuration = new Configuration();
// FileSystem fs = FileSystem.get(new
URI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"),
configuration,"atguigu");
// 2 创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
// 3 关闭资源
fs.close();
} }
对代码进行封装
package com.atguigu.hdfs;
import com.sun.jndi.toolkit.url.Uri;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* 客户端代码常用套路
* 1、获取一个客户端对象
* 2、执行相关的操作命令
* 3、关闭资源
* HDFS zookeeper
*/
public class HdfsClient {
private FileSystem fs;
@Before
public void init() throws URISyntaxException, IOException, InterruptedException {
// 1 获取文件系统
Configuration configuration = new Configuration();
URI uri = new URI("");
String user = "xjx";
fs = FileSystem.get(uri,configuration,user);
}
@After
public void close() throws IOException {
fs.close();
}
@Test
public void testMkdirs() throws IOException, URISyntaxException,
InterruptedException {
// 2 创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
}
}
7)执行程序
客户端去操作
HDFS
时,是有一个用户身份的。默认情况下,
HDFS
客户端
API
会从采用 Windows 默认用户访问
HDFS
,会报权限异常错误。所以在访问
HDFS
时,一定要配置用户。
org.apache.hadoop.security.AccessControlException: Permission denied:
user=56576, access=WRITE,
inode="/xiyou/huaguoshan":atguigu:supergroup:drwxr-xr-x2、 HDFS 的 API 案例实操
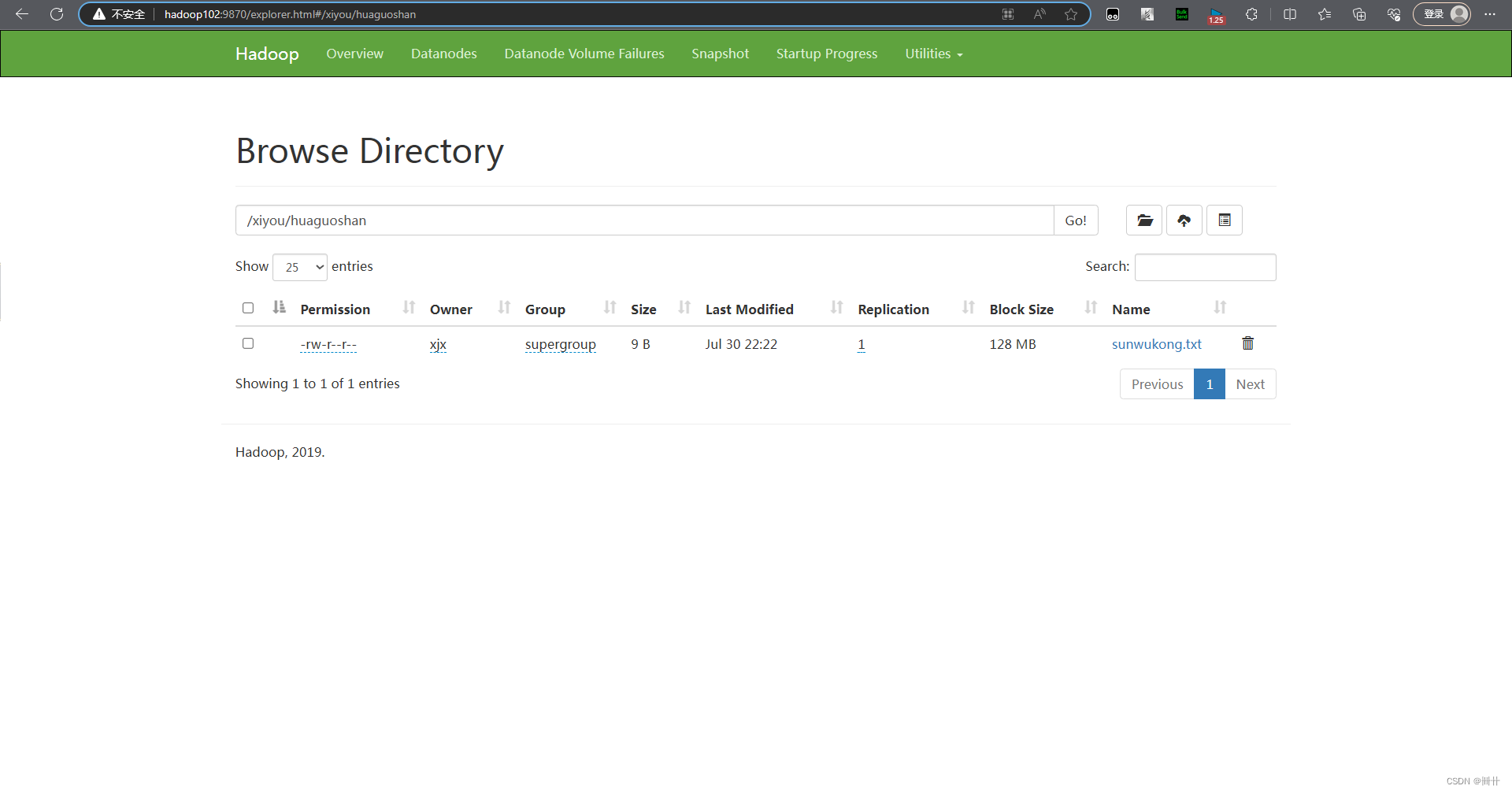
2.1 HDFS 文件上传(测试参数优先级)
1
)编写源代码
// 上传
@Test
public void testPut() throws IOException {
// 参数解读:参数一:表示删除原数据;参数二:是否允许覆盖;参数三:原数据路径:参数四:目的路径
fs.copyFromLocalFile(false,false,new Path("E:\\IDEA\\sunwukong.txt"),new Path("hdfs://hadoop102/xiyou/huaguoshan/"));
}
2)将 hdfs-site.xml 拷贝到项目的 resources 资源目录下
已知服务器的默认配置 (xxx-default.xml) 中的副本数是3,现在resources下新建一个file——hdfs-site.xml修改副本数
测试二者的优先级
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>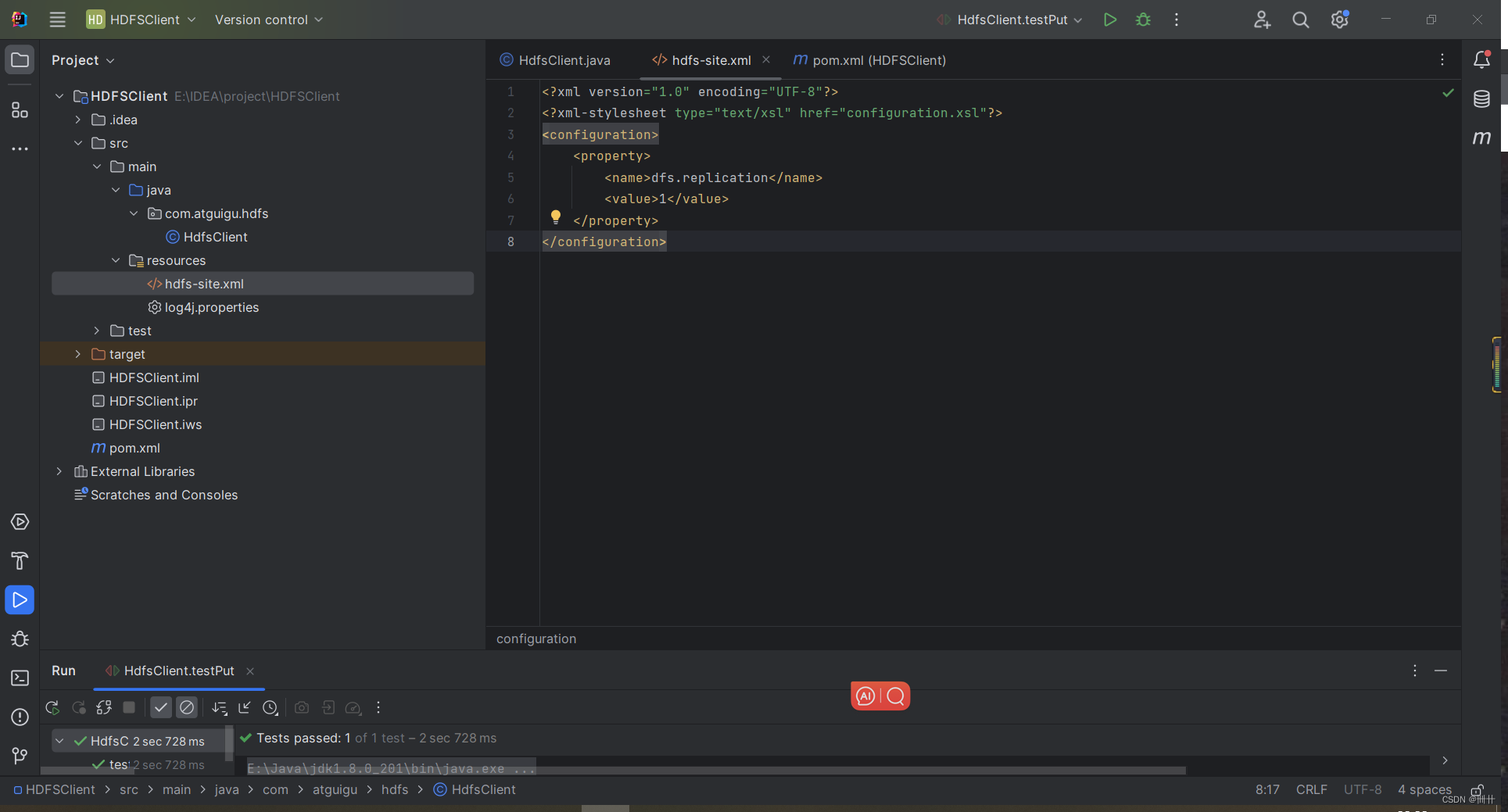
如果上传一个文件,它的副本数为1,说明 resources 资源目录下的hdfs-site.xml 优先级高
说明在项目资源目录下用户自定义的配置文件高。
(1)ClassPath 下的用户自定义配置文件(2)服务器的自定义配置(xxx-site.xml )(3) 服务器的默认配置( xxx-default.xml )
再测试客户端代码中配置副本的值的优先级:
configuration.set("dfs.replication","2");

说明客户端代码中配置高
参数优先级排序:(1 )客户端代码中设置的值(2) ClassPath 下的用户自定义配置文件(3)然后是服务器的自定义配置( xxx-site.xml )(4)服务器的默认配置( xxx-default.xml )
2.2 HDFS 文件下载
// 文件下载
@Test
public void testGet() throws IOException {
// 参数的解读:参数一:原文件是否删除;参数二:原文件路径HDFS;参数三:目标地址路径Win;参数四:
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("E:\\IDEA\\sunwukong"),false);
} 注意:是不是突然发现多了一个crc文件,用于检测传输数据有无发生变化,刚刚参数4设置为false进行了传输文件的校验
注意:是不是突然发现多了一个crc文件,用于检测传输数据有无发生变化,刚刚参数4设置为false进行了传输文件的校验
注意:如果执行上面代码,下载不了文件,有可能是你电脑的微软支持的运行库少,需要安装一下微软运行库。
将参数四改为true
// 文件下载
@Test
public void testGet() throws IOException {
// 参数的解读:参数一:原文件是否删除;参数二:原文件路径HDFS;参数三:目标地址路径Win;参数四:校验
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("E:\\IDEA\\sunwukong"),true);
}
将不会出现crc文件。
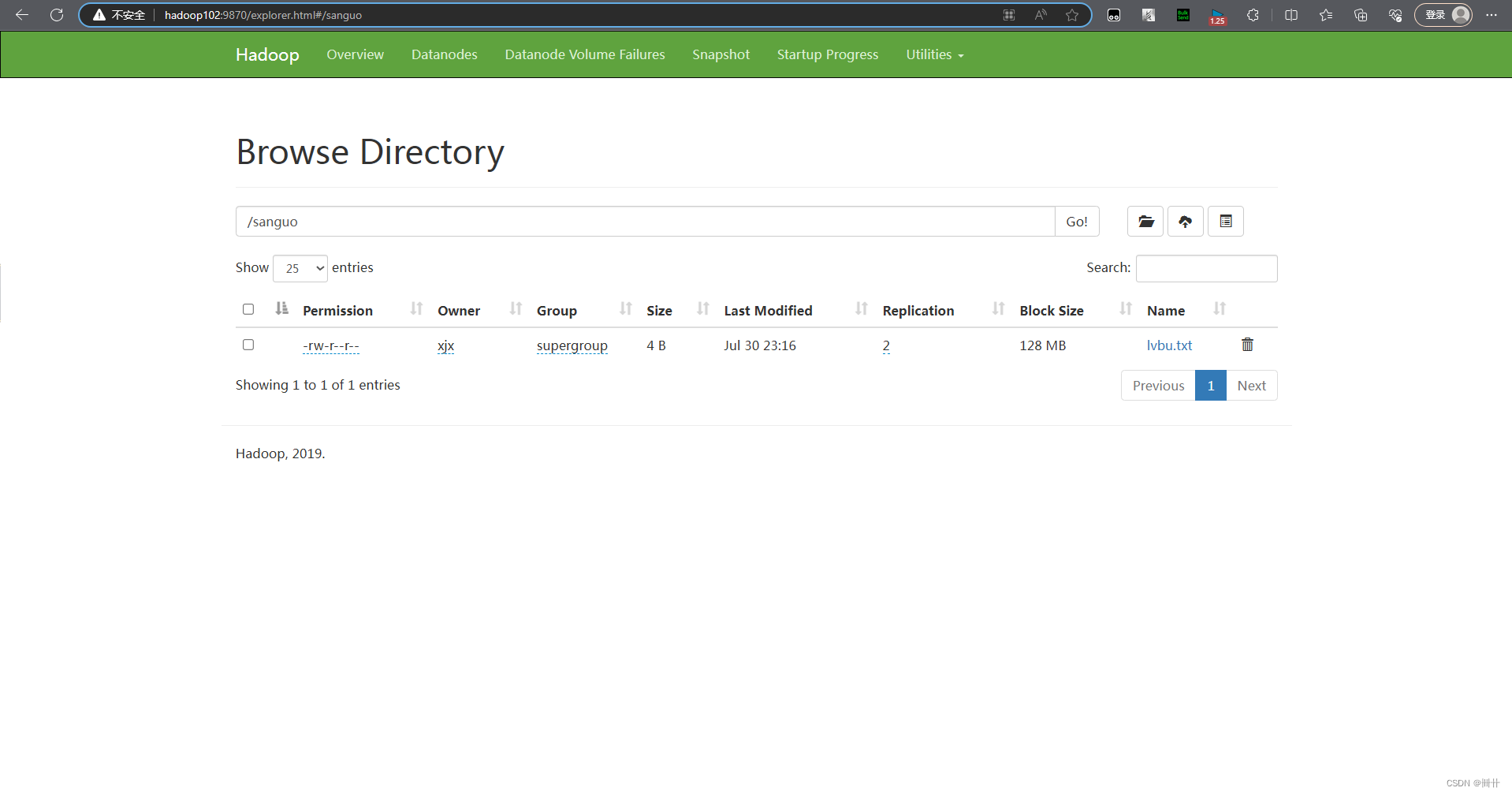
2.3 HDFS 文件更名和移动
// 文件的更名和移动
@Test
public void testmv() throws IOException {
// 参数一:原文件路径; 参数2:目标文件路径
fs.rename(new Path("/sanguo/lvbu.txt"),new Path("/sanguo/guanyu.txt"));
}

// 文件的更名和移动
@Test
public void testmv() throws IOException {
// 参数一:原文件路径; 参数2:目标文件路径
// fs.rename(new Path("/sanguo/lvbu.txt"),new Path("/sanguo/guanyu.txt"));
// 文件的移动和更改
fs.rename(new Path("/sanguo/guanyu.txt"),new Path("/liubei.txt"));
}
// 文件的更名和移动
@Test
public void testmv() throws IOException {
// 参数一:原文件路径; 参数2:目标文件路径
// fs.rename(new Path("/sanguo/lvbu.txt"),new Path("/sanguo/guanyu.txt"));
// 文件的移动和更改
// fs.rename(new Path("/sanguo/guanyu.txt"),new Path("/liubei.txt"));
// 目录更名
fs.rename(new Path("/sanguo"),new Path("shuguo"));
} 
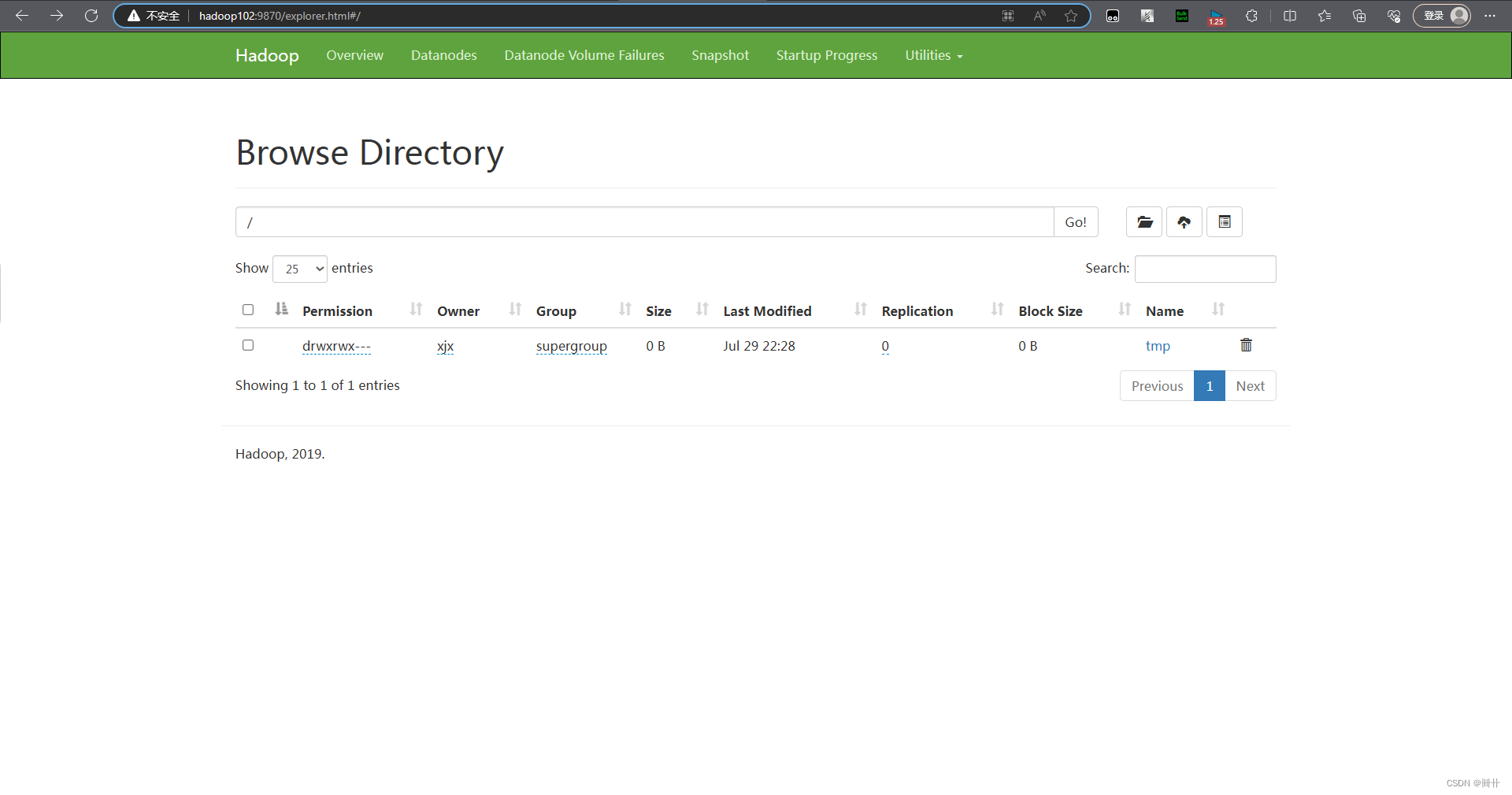
3.2.4 HDFS 删除文件和目录
// 文件删除
@Test
public void testRm() throws IOException {
// 参数一:要删除的路径; 参数2:是否递归删除
fs.delete(new Path("/jdk-8u212-linux-x64.tar.gz"),false);
// 删除空目录
fs.delete(new Path("/xiyou"),false);
// 删除非空目录
fs.delete(new Path("/jinguo"),false);
}
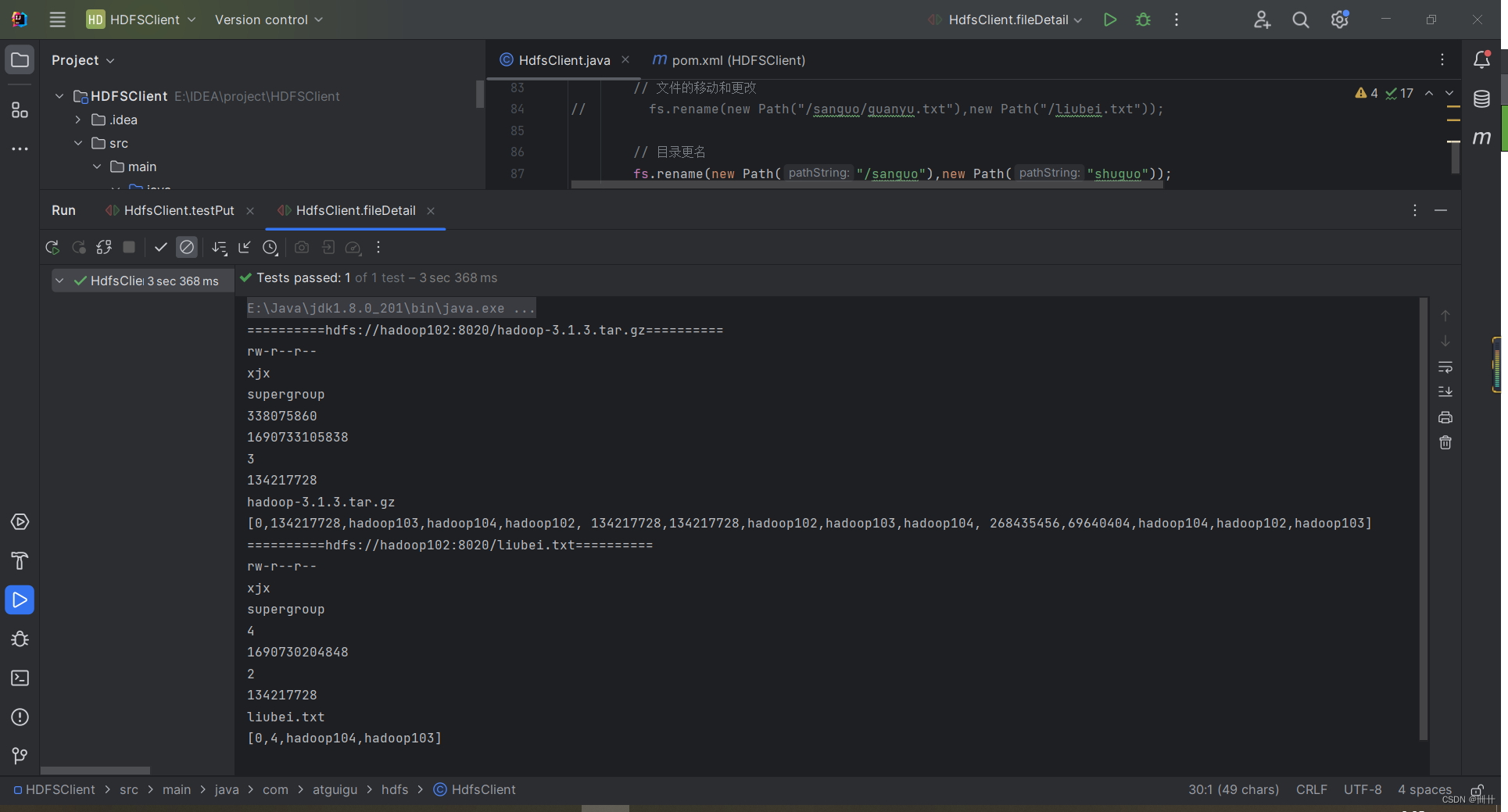
2.5 HDFS 文件详情查看
查看文件名称、权限、长度、块信息
// 获取文件详细信息
@Test
public void fileDetail() throws IOException {
// 获取所有文件信息
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"),true);
//遍历文件
while (listFiles.hasNext()){
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("==========" +fileStatus.getPath() + "==========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
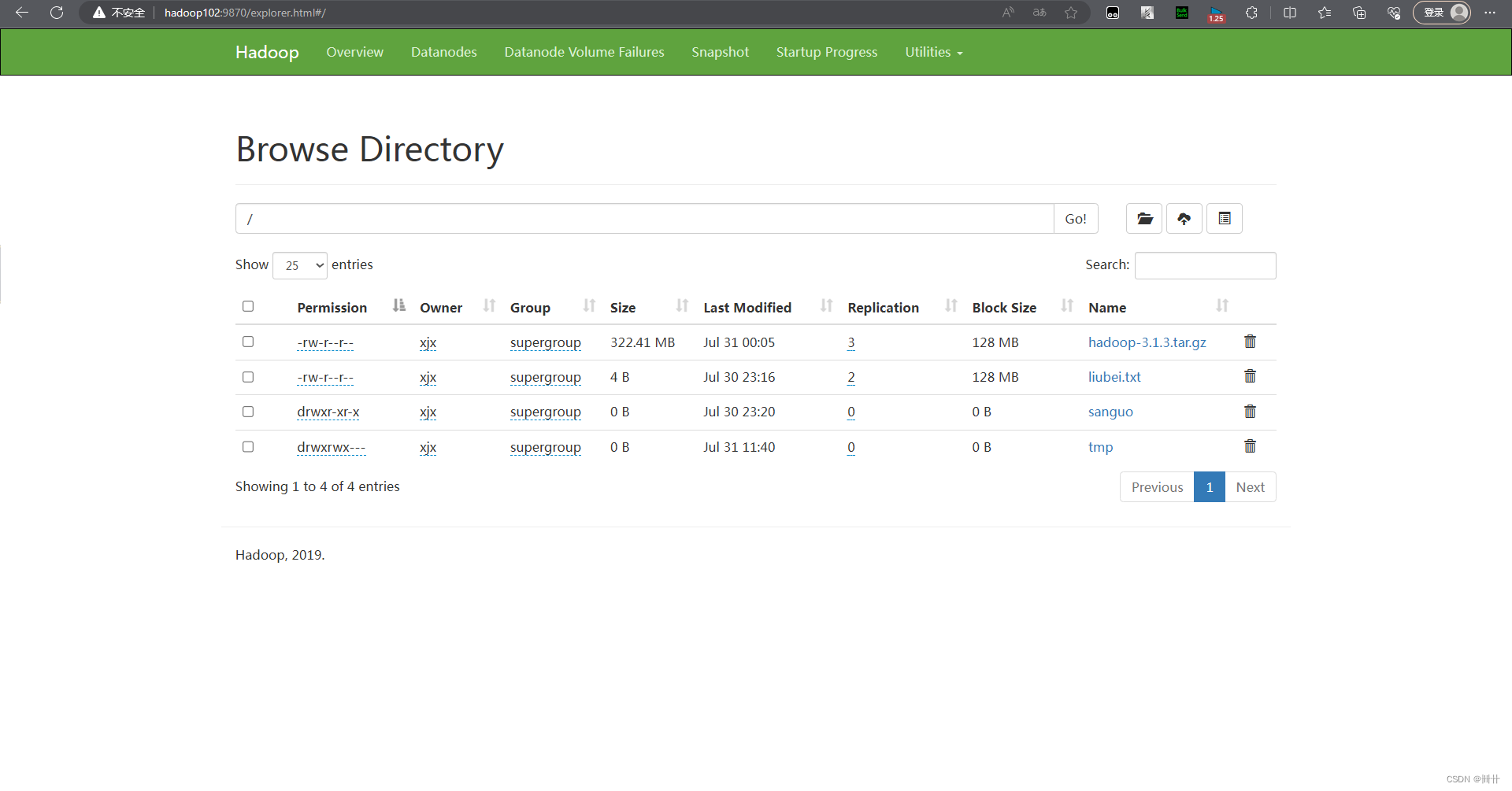
2.6 HDFS 文件和文件夹判断
// 文件和文件夹判断
@Test
public void testFile() throws IOException {
FileStatus[] fileStatuses = fs.listStatus(new Path("/"));
for (FileStatus Status : fileStatuses) {
if (Status.isFile()) {
System.out.println("文件:" + Status.getPath().getName());
}
else {
System.out.println("目录:" + Status.getPath().getName());
}
}
}
















 1286
1286











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









