







- Attention is all you need.
- 注意力是你所需要的一切
- Vaswani A, Shazeer N, Parmar N, et al.
- Advances in neural information processing systems, 2017, 30.
文章目录
摘要
- 首先指出,目前主要的序列转导(sequence transduction)模型是含有encoder和decoder的基于复杂的RNN或CNN。性能最好的模型还通过注意力机制连接encoder和decoder。
- 序列转导模型:给定一个序列,生成另外一个序列(如机器翻译:给一句英文,翻译成一句中文)
- 然后提出,本文提出的模型Transformer—完全基于注意力机制,不需要任何递归(RNN)或卷积(CNN)的网络结构。
- 接着通过两个机器翻译的实验,证明了Transformer具有良好的性能,同时具有更高的并行性,并且需要训练的时间显著减少。
- the WMT 2014 Englishto-German translation task、the WMT 2014 English-to-French translation task
- 最后,还证明了Transformer可以很好地推广到其他任务。
1. 引言
- 介绍了序列建模和转导问题中常见的模型:RNN、LSTM、GRU
- 介绍了RNN的原理以及RNN的弊端:
- RNN原理:RNN模型通常会沿着输入和输出序列的符号位置进行计算。将位置与计算的时间步对齐,它们生成一系列隐藏状态 ht,作为先前隐藏状态 ht−1 和位置 t 输入的函数。
- RNN弊端:RNN这种固有的顺序性质阻碍了训练示例中的并行化,这对于处理长序列是非常不利的,因为内存限制限制了示例之间的批处理。
- 介绍了注意力机制的优势
- Attention mechanisms允许对依赖关系建模,而不考虑它们在输入或输出序列中的距离。
- 目前的注意力机制大部分,都是与RNN结合使用。
- 提出,本文的Transformer是一种避免使用RNN,并且完全依赖注意力机制来绘制输入和输出之间的全局依赖关系。
- 再次强调,Transformer能够明显提高模型训练的并行度。
2. 背景
- 介绍了,如何使用CNN来替换RNN,从而减少顺序计算的常见模型:拓展GPU、ByterNet、ConvS2S
- 介绍了,自注意力的原理,以及能够应用于各种任务:阅读理解、抽象概括、文本蕴含、和与学习无关的句子等等
- self-attention:一种将单个序列的不同位置相关联的注意力机制。
- 介绍了端到端记忆网络:是基于注意机制的RNN,而不是序列对齐RNN。
- 强调了Transformer是第一个完全依赖自注意力来计算输入和输出表示,而不是使用序列对齐的RNN或卷积的转换模型。
3. 模型结构
Transformer也是像大多数序列转导模型一样,具有encoder-decoder结构, 并且每个步骤模型都是自回归(auto-regressive)的。
- encoder:编码器将输入序列 ( x 1 , . . . , x n ) (x_1, ..., x_n) (x1,...,xn)映射到连续表示序列 z = ( z 1 , . . . , z n ) z=(z_1, ..., z_n) z=(z1,...,zn)
- decoder:解码器依次生成一个输出序列 ( y 1 , . . . , y m ) (y_1, ..., y_m) (y1,...,ym) (注意:encoder生成的序列长度和decoder输出的序列长度有可能不一样。)
- auto-regressive:在过去时刻的输出作当前时刻的输入。
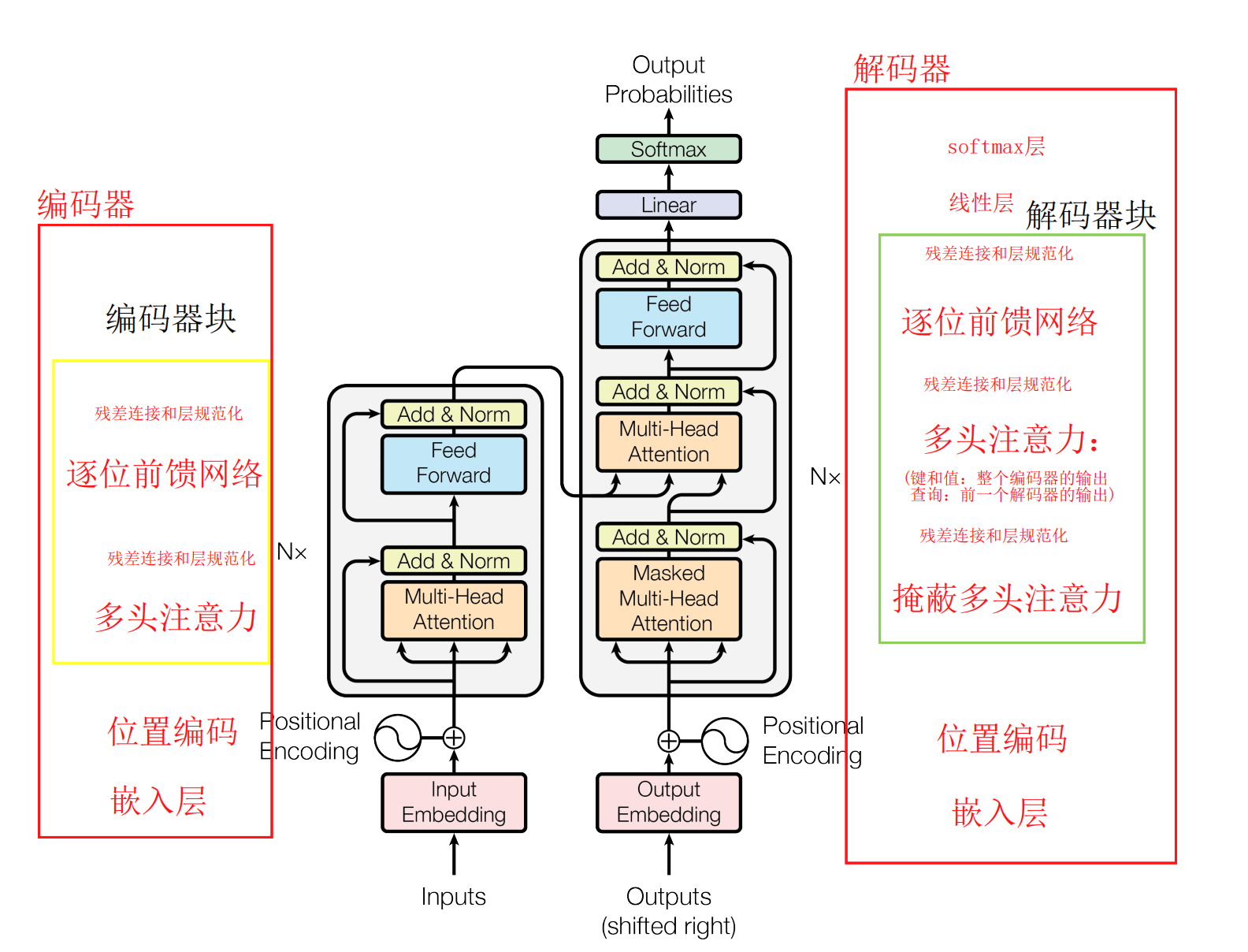
3.1 encoder和decoder块
- encoder:
- 编码器由N=6个相同的编码器块组成。
- 每个编码器块有两个子层:
- 一个是多头自注意力机制,
- 另一个是简单的MLP前馈网络。
- 对每个子层的输出采用残差连接和层归一化: L a y e r N o r m ( x + S u b l a y e r ( ) x ) LayerNorm(x + Sublayer()x) LayerNorm(x+Sublayer()x);
- 为了实现残差连接,所有的子层和嵌入层生成的输出维度相同: d m o d e l = 512 d_{model}=512 dmodel=512
- decoder:
- 解码器也由N=6个相同的解码器块组成。
- 每个编码器块有三个子层:
- 一个带有mask的多头自注意力机制(为了防止注意力机制关注当前位置以后的位置,mask与输出嵌入偏移一个位置相符合,确保位置i的预测只能依赖于小于i位置处的已知输出),
- 一个对编码器块输出执行的多头注意力机制
- 一个简单的MLP前馈网络。
- 对每个子层的输出采用残差连接和层归一化。
- 为什么Transformer使用LayerNorm而不使用BatchNorm?:
- 特征归一化:(特征-均值)/标准差。
- 二维输入(样本n,特征feature ):
- BN:对一个mini-batch内的每一个特征做归一化。
- LN:对每个样本做归一化。![[Pasted image 20240321110549.png|50]]
- 三维输入(有多个序列,每个序列有多个词(长度不一定相同),每个词都是一个向量(特征))
- BN:对一个batch内所有序列的每个特征做归一化。
- LN:对每个序列的做归一化。
- 如果每个序列的长度不一样:
- BN:如果一个batch内的序列长度变化较大时,计算BN的结果抖动就会比较大,并且在预测时,需要先计算之前全部样本均值和标准差,如果将全局的均值和标准差预测一个新的较长的序列(在训练的时候没有遇见过),则之前计算的均值和方差可能会不在那么好用。
- LN:计算每个样本自己的均值和方差,其他的序列长短对当前序列无关。 并且在预测时,也不需要计算全局的均值和标准差,计算结果相对稳定。

3.2 Attention
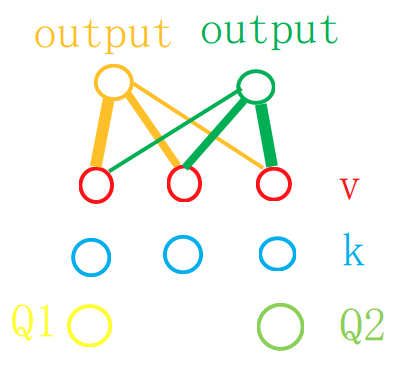
- 注意力函数是将query和一组key-value对映射到output(输出)的函数,其中query、key、value和output都是向量。
- output实际上是value的加权和,所以(output的维度于value的维度是一样的)其中对每个value的权重是由query和对应的key的相似度计算的。
- (假设有3个key和value,Q1和k1和k1比较相似,则它关于V1和V2的权重就大一些,关于V3的权重就小一点 )
3.2.1 缩放点积注意力(Scaled Dot-Product Attention)
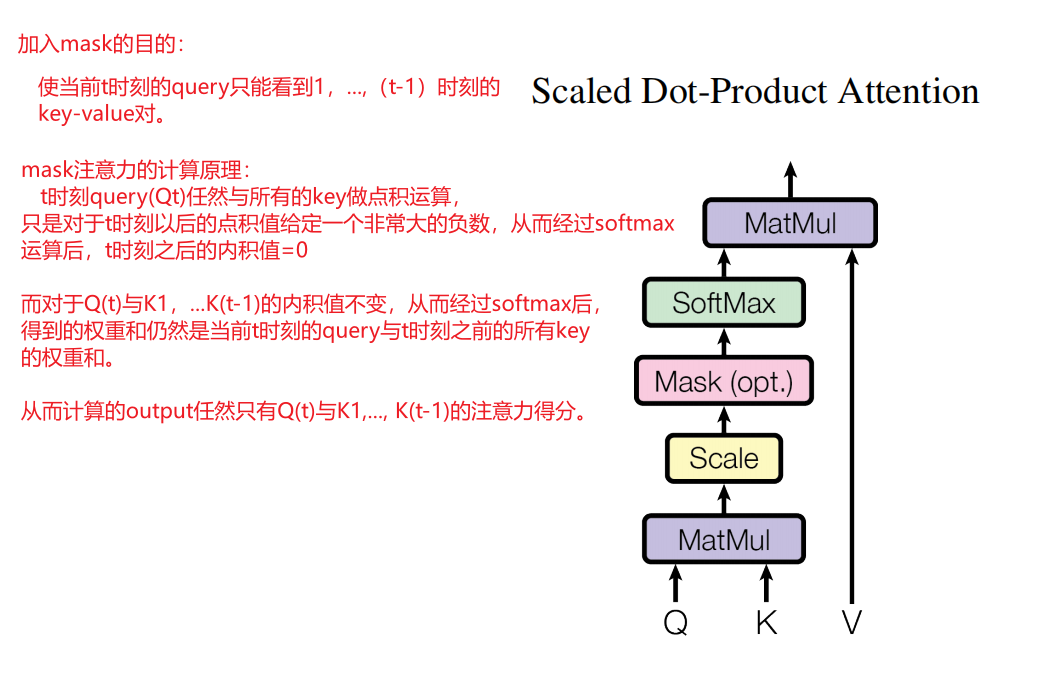
Scaled Dot-Product Attention:输入由query和key(维度都是 d k d_k dk)以及value(维度是 d v d_v dv)组成,计算query与所有的key的点积,在除以 d k \sqrt{d_k} dk,然后应用softmax函数(输出是非负且和为1)来得到value的权重。
(在实际的过程中,同时计算一组query的注意力函数,将其打包到矩阵Q中,key和value也打包到矩阵K和V中)(query和key的个数可能不同,但是query和key的维度一定是一样的)
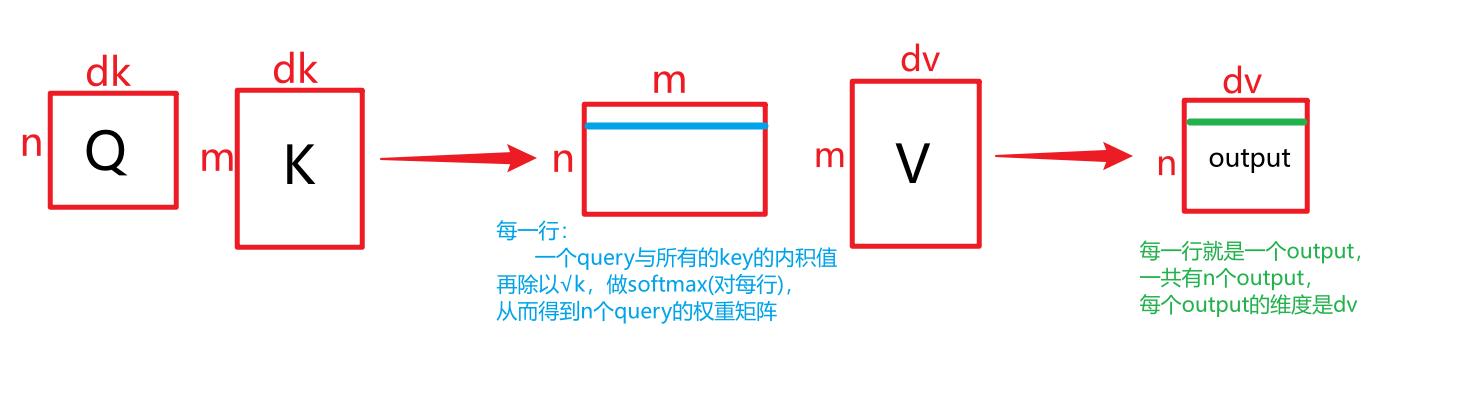
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V ( 1 ) Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\ \ \ \ \ (1) Attention(Q,K,V)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









