







本文大部分学习自:https://www.cnblogs.com/banshaohuan/p/13308732.html
多重共线性:
多重共线性是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。
剔除多重共线性主要在模型训练之前的特征工程完成。
逻辑回归模型
模型一般形式:
y
(
x
)
=
1
1
+
e
−
θ
T
x
y(x) = \frac{1}{1+e^{-\theta^T x}}
y(x)=1+e−θTx1
其中,
θ
=
(
θ
0
,
θ
1
,
θ
2
,
.
.
.
,
θ
n
)
T
\theta=(\theta_0,\theta_1,\theta_2,...,\theta_n)^T
θ=(θ0,θ1,θ2,...,θn)T,
x
=
(
x
0
,
x
2
,
.
.
.
.
,
x
n
)
x=(x_0,x_2,....,x_n)
x=(x0,x2,....,xn),
x
0
=
1
x_0=1
x0=1。
实际上
θ
0
\theta_0
θ0是截距项。
这个模型就是线性函数外面复合上一个sigmoid函数/logistic函数。
sigmoid函数本身是一个图像为“S型”;关于点(0,1/2)中心对称;当自变量趋于正无穷时,函数值趋于1,当自变量趋于负无穷时,函数值趋于0。
(将其自变量替换为线性函数,图像会进行x轴方向的伸缩和平移,一维情况下很容易想象。)
模型输出可认为是概率:
将
y
(
x
)
y(x)
y(x)视作是正例概率,则
1
−
y
(
x
)
1-y(x)
1−y(x)就是反例的概率。
ln
y
(
x
)
1
−
y
(
x
)
\ln\frac{y(x)}{1-y(x)}
ln1−y(x)y(x)就是对数几率,易得
ln
y
(
x
)
1
−
y
(
x
)
=
θ
T
x
\ln\frac{y(x)}{1-y(x)}=\theta^Tx
ln1−y(x)y(x)=θTx。所以逻辑回归可以理解为用线性函数拟合对数几率。
这样也可以解释,虽然名称上是回归算法,但是做的却是分类任务。
性能度量/损失函数/优化目标–极大似然MLE
上面说了逻辑回归模型的输出可以看作是样本为正例的概率。
把样本为正反例的概率分布看作是0-1分布,其实我们训练逻辑回归模型的过程就可以看作是参数估计的过程。
统计中常用的参数估计方法有极大似然法MLE,逻辑回归也是使用MLE进行估计。
极大似然法MLE:将 似然函数/对数似然函数 作为优化目标,找到使其最大化的参数。
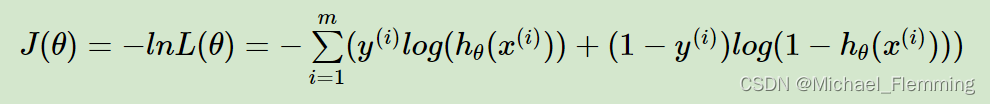
逻辑回归的正则化
上面一节的优化过程是基于训练集完成,即使对训练集拟合得在好,模型的泛化性能不好,也不是一个好的学习器。
与Ridge和LASSO类似,逻辑回归正则项也可以是l-1范数和l-2范数,当然,也有弹性网正则项等。
- 有一个小小的点:sklearn里的优化模型将正则参数放在损失函数前面(LASSO和Ridge是放在正则项前面)

回顾:l-1正则化可以看作是一种嵌入式特征选择,最后解出的回归系数有稀疏性质。而l-2正则化的解倾向于稠密。下面用一个小例子演示一下:
例子:
数据集:UCI的breast cancer数据集(sklearn里的datasets就有,不用自己导入了)
目的:使用 l1正则的逻辑回归 和 l2正则的逻辑回归 分别i训练模型,观察最后解出的回顾系数的稀疏情况。
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_breast_cancer
BC_data = load_breast_cancer()
X = BC_data.data
y = BC_data.target
# 因为只是小小的例子,不用划分训练集和测试集了
lrl1 = LogisticRegression(penalty='l1', solver='liblinear', C=0.5, max_iter=1000) # 可选正则项
lrl2 = LogisticRegression(penalty='l2', solver='liblinear', C=0.5, max_iter=1000)
# 既然要对比两个学习器,就要控制上面的参数是一致的。
lrl1.fit(X, y)
lrl2.fit(X, y)
print('l1-logistic回归系数非0个数:')
print(np.sum(lrl1.coef_ != 0))
print('l2-logistic回归系数非0个数:')
print(np.sum(lrl2.coef_ != 0))
l1-logistic回归系数非0个数:
10
l2-logistic回归系数非0个数:
30
以上只是对比了解出来的回归系数的稀疏性,那到底哪一个模型更好呢?也就是,哪一个泛化能力更好?
下面的例子比较不同正则参数下,两种正则化方法的性能。使用正确率作为评价指标,可以用accuracy_score()函数,也可以直接使用学习器对象的方法lr.score().
**注意1:**此时需要划分训练集与测试集了。
**注意2:**训练集与测试集不同的划分方法也会导致结果不同。
# 用正则化系数和模型精确度的关系 比较l1正则和l2正则的泛化表现
# 注意,这就需要在测试集上看表现了
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 准备正则化参数
Cs = np.linspace(0.05, 1, 19)
accs_lr1_train, accs_lr2_train = [], []
accs_lr1_test, accs_lr2_test = [], []
for i in Cs:
lrl1.set_params(C=i) # 将正则系数修改
lrl2.set_params(C=i)
lrl1.fit(X_train, y_train)
lrl2.fit(X_train, y_train)
accs_lr1_train.append(accuracy_score(lrl1.predict(X_train), y_train))
accs_lr2_train.append(accuracy_score(lrl2.predict(X_train), y_train))
accs_lr1_test.append(accuracy_score(lrl1.predict(X_test), y_test))
accs_lr2_test.append(lrl2.score(X_test, y_test))
# 画图
ax = plt.gca()
accs = [accs_lr1_train, accs_lr2_train, accs_lr1_test, accs_lr2_test]
colors = ['green', 'lightgreen', 'blue', 'lightblue']
[ax.plot(Cs, accs[i], color=colors[i]) for i in range(4)]
ax.legend(labels=['l1-norm-train', 'l2-norm-train', 'l1-norm-test', 'l2-norm-test'], loc=4)
ax.set(xlabel='parameter', ylabel='accuracy')
plt.show()
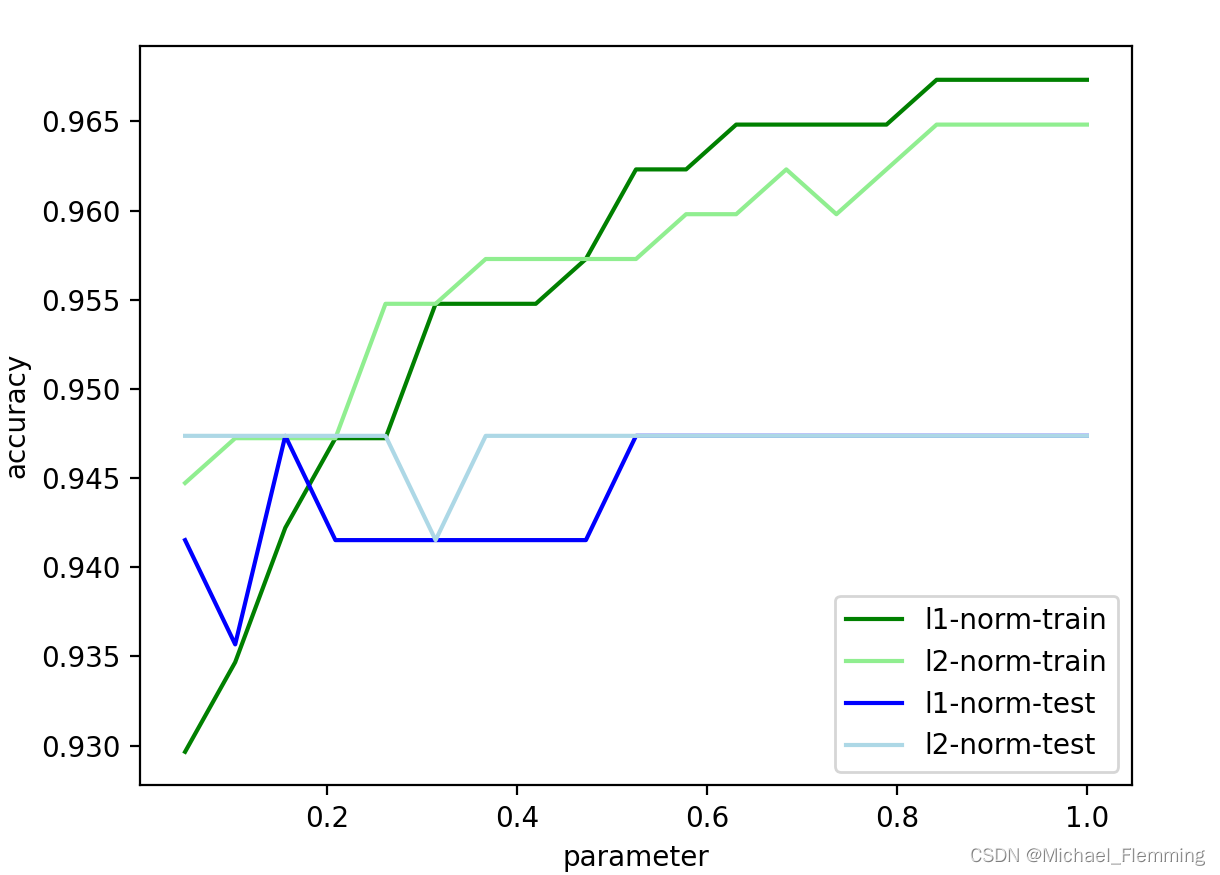
注:一般情况train的曲线在test上面,但是数据集的划分会影响结果,让我们看一下将train_test_split()函数中randomstates设置为520的情况。(random_state定了,以后每次划分的结果都是一样的,所以之后运行多少次曲线都是一样的,因为随机种子是固定的)
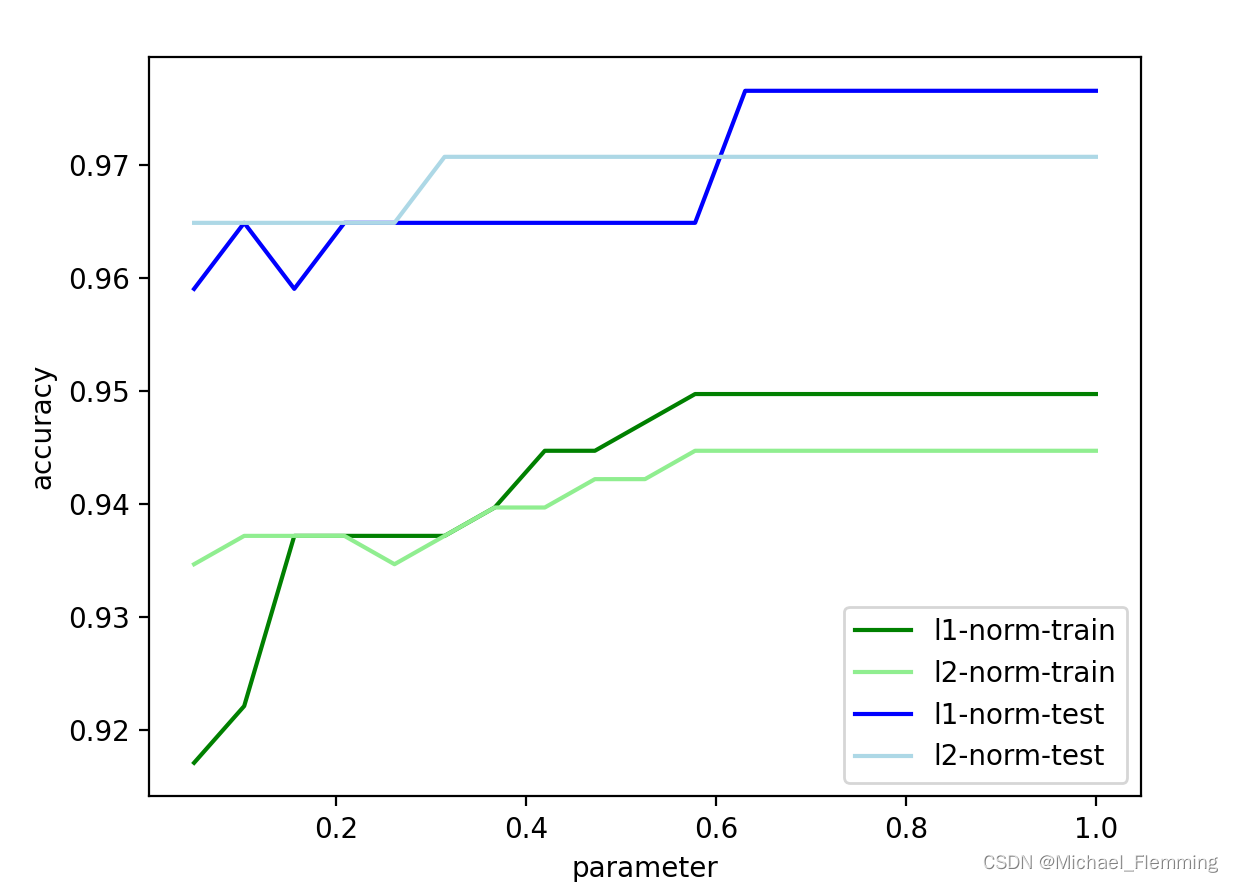
发现此时test曲线竟然在train曲线上方。
总结:
**C越来越大时,正则化强度就越来越小,可以认为模型越来越复杂。**大概C=0.5的时候测试集的精度不再上升,但是训练集精度还是在持续上升。可以认为C=0.5之后模型过拟合。
以上过程可以认为在调参,其实可以用LogisticRegressionCV(带交叉验证的逻辑回归)自动完成。
逻辑回归的特征选择
- 业务选择:✔
- PCA和SVD一般不用:破坏线性关系。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标签之间的关系了。
- 统计方法可以使用,但不是非常必要
- 高效的嵌入法embedded:✔就是l1正则化。结合嵌入法的模块SelectFromModel,我们可以很容易就筛选出 让模型十分高效的特征。此时我们的目的是,尽量保留原数据上的信息,让模型在降维后的数据上的拟合效果保持优秀,因此我们不考虑训练集测试集的问题,把所有的数据都放入模型进行降维。
sklearn.feature_selection.SelectFromModel:
class sklearn.feature_selection.SelectFromModel(estimator, *, threshold=None, prefit=False, norm_order=1, max_features=None)
- 下面是一个简单的使用l1正则化模型+SelectFromModel进行特征选择的例子:
注意:如果模型是l1正则类的,不指定threshold参数,就是默认筛选正则化后系数不为0的对应的特征(实际上是设置了threshold为1e-5)
# 结合l1正则化和SelectFromModel来做特征选择
# SelectFromModel也是一个类
# 与l1正则相关的学习器结合一起用,不设置threshold默认为None,就是筛选出非0的特征
lrl1.set_params(C=0.9, random_state=520)
sfm = SelectFromModel(estimator=lrl1) # prefit默认是false,所以sfm还要重新用lrl1做一遍拟合
X_transform = sfm.fit_transform(X, y)
print(X_transform.shape)
print(sfm.threshold_) # 因为estimator是L1正则化类型的,就使用默认的threshold=1e-05
X_scores = cross_val_score(lrl1, X, y, cv=10)
# 上面的过程对整个X(30个特征)做了一遍l1正则的逻辑回归训练,用最后解出来的系数做了特征选择。
# 现在看看直接用筛选出来的特征X_transform训练学习器是多少分
X_trans_scores = cross_val_score(lrl1, X_transform, y, cv=10)
print(X_scores.mean())
print(X_trans_scores.mean())
# 以我目前的理解,两种办法的得分应该是一模一样的啊(如果交叉验证时数据集的划分是一致的)??
# cv参数较小的时候确实得分是一样的,但是cv大于等于10就不太一样了。
ROC曲线
receiver operating characteristic curve,简称ROC曲线。
下面是一些指标:
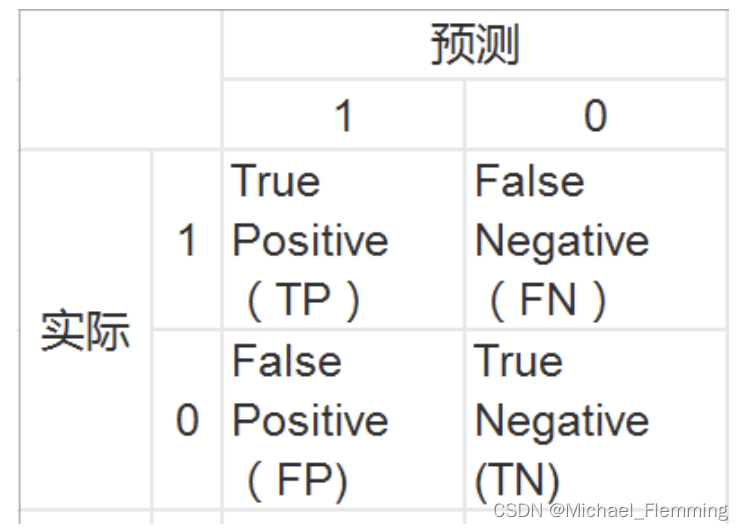
p: the number of real positive cases in the data,真实标签中整理的数量
N: 真实标签中反例的数量
TP: true positive,预测为正例,且真实标签也是正例的数量(预测为正例的样本中真正为正例的数量)
FP: false positive,预测为真例,但是真实标签是反例(预测为正例的样本中,其实是反例的数量;也即是,预测为正例的样本中,预测错的数量)
所以,TP+FP就是预测为正例的数量。
TN和FN同理,就是预测为反例的样本中,实际是反例/正例的数量。
TPR:
T
P
R
=
T
P
P
=
T
P
T
P
+
F
N
TPR=\frac{TP}{P}=\frac{TP}{TP+FN}
TPR=PTP=TP+FNTP 注意,分母是真实正例的数量,不是预测为正例的数量。
FPR:
F
P
R
=
F
P
N
=
F
P
F
P
+
T
N
FPR=\frac{FP}{N}=\frac{FP}{FP+TN}
FPR=NFP=FP+TNFP 注意,分母是真实反例的数量,不是预测为反例的数量。
- ROC曲线是以TPR为中坐标,FPR为横坐标的曲线。
- 但实际上,一个训练好的分类器只有一对(TPR,FPR),只对应一个点啊。下面是四个分类器对比。
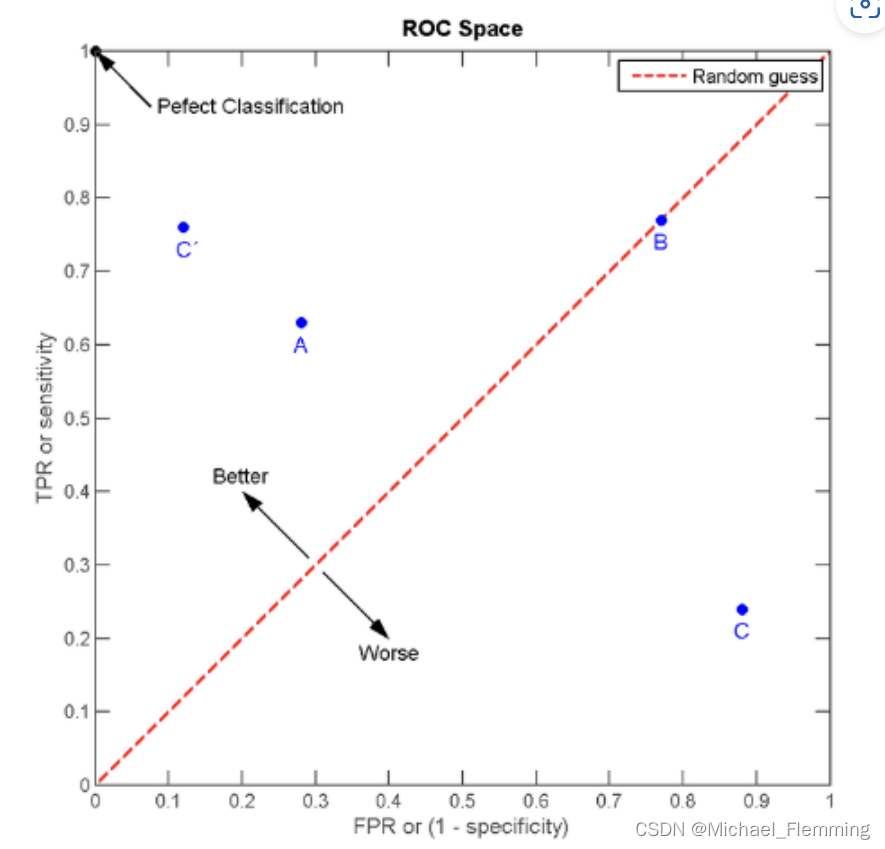
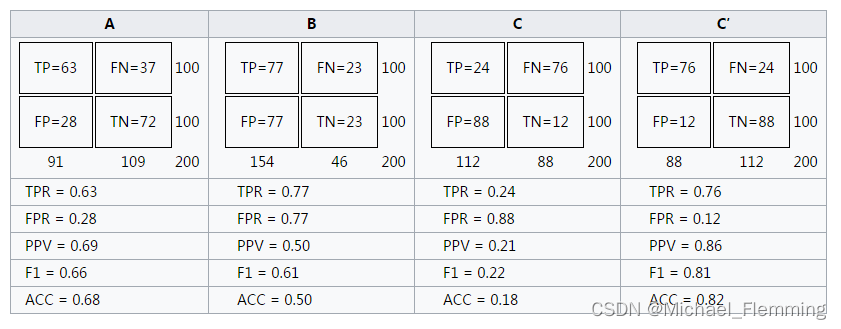
- ROC曲线下面积(the area under the ROC curve, AUC)是指ROC曲线与x轴、(1,0)-(1,1)围绕的面积,如图1阴影部分。
明显,C‘性能最好。 - 可以发现TPR和FPR没有相关性,所以ROC不能理解为一个函数曲线。事实上,ROC曲线上的点代表着一个分类器在不同阈值下的分类效果。
- 分类器阈值是0,对应点(0,0),因为全部预测为反例,TP=FP=0.
- 分类器阈值是1,对应点(1,1),因为全部预测为正例,TP=FP=1。
sklearn逻辑回归
逻辑回归有关类:
linear_model.LogisticRegression 普通逻辑回归分类器
linear_model.LogisticRegressionCV 交叉验证逻辑回归分类器
linear_model.logistic_regression_path 计算Logistic回归模型以获得正则化参数的列表
linear_model.SGDClassifier 利用梯度下降求解的线性分类器(SVM,逻辑回归等等)
linear_model.SGDRegressor 利用梯度下降最小化正则化后的损失函数的线性回归模型
metrics.log_loss 对数损失,又称逻辑损失或交叉熵损失
评价指标有关类:
metrics.confusion_matrix 混淆矩阵,模型评估指标之一
metrics.roc_auc_score ROC曲线,模型评估指标之一
metrics.accuracy_score 精确性,模型评估指标之一
linear_model.LogisticRegression:
class sklearn.linear_model.LogisticRegression(penalty='l2', *, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver='lbfgs', max_iter=100, multi_class='auto', verbose=0, warm_start=False, n_jobs=None, l1_ratio=None)
官方文档
一些参数解释:
penalty:{‘L1’, ‘L2’, ‘elasticnet’, ‘none’}, default=’L2’
用于指定处罚中使用的规范。‘newton-cg’,'sag’和’lbfgs’求解器仅支持L2惩罚。仅“ saga”求解器支持“ elasticnet”。如果为“ none”(liblinear求解器不支持),则不应用任何正则化。
solver:{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}, default=’lbfgs’用于优化问题的算法。
- 对于小型数据集,“ liblinear”是一个不错的选择,而对于大型数据集,“ sag”和“ saga”更快。
- 对于多类分类问题,只有’newton-cg’ ,‘sag’,‘saga’ 和 ‘lbfgs’ 处理多项式损失。“ liblinear”仅限于“一站式”计划。
- ‘newton-cg’,‘lbfgs’,'sag’和’saga’处理L2或不惩罚
- 'liblinear’和’saga’也可以处理L1罚款
- “ saga”还支持“ elasticnet”惩罚
- 'liblinear’不支持设置 penalty=‘none’
一些方法解释:
score(self, X, y[, sample_weight]) 返回给定测试数据和标签上的平均准确度。
注:和使用accuracy_score()函数的结果是一样的。使用的评价指标都是准确率accuracy。















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









