







mPMR: A Multilingual Pre-trained Machine Reader at Scale
mPMR:大规模多语言预训练机器阅读器
paper: https://arxiv.org/abs/2305.13645
github: https://github.com/DAMO-NLP-SG/PMR
文章目录~
1.背景动机
mPLMs的跨语言能力,即直接应用到未训练过的语言中:
多语种预训练语言模型(缩写为 mPLMs)已在多种语言中展现出强大的自然语言理解(NLU)能力。尽管 mPLMs 只在英语等资源丰富的源语言上进行微调,但它们可以在未见过的目标语言上保持卓越的跨语言语言理解(XLU)能力。
介绍mPLMs多语言预训练的问题:
事实证明,优化 mPLM 的跨语言表征可以提高 XLU 的能力。例如,平行句子或双语词典等跨语言监督可以通过更好的语言对齐来增强跨语言表征。在预训练过程中适当加入更多语言会带来更好的跨语言表征。一些研究通过利用知识图谱中注释的多语言实体和关系,用事实知识丰富了跨语言表征。尽管存在差异:
基本上都构建了更多样化的多语言语料库,用于预训练 mPLM。这些 mPLMs 可能会达到饱和点,并受到众所周知的多语言性诅咒。在这种情况下,从现有语言或未见语言中引入更多的训练数据来增强 mPLM 可能不会带来进一步的改进,甚至会对其跨语言表征造成损害。
2.Model
介绍本文提出的mPMR模型(并不是在多语言上持续预训练):
在本文中,不训练具有更好跨语言表征的新mPLM,而是提出了多语言预训练机器阅读器(mPMR),以直接指导现有 mPLM 在各种语言中形成 NLU。在 XLU 微调过程中,mPLM 仅依靠跨语言表征将 NLU 能力从源语言转移到目标语言。相比之下,mPMR 能够以统一的 MRC 形式将多语言 NLU 能力从 MRC 式预训练直接继承到下游任务,从而消除源语言微调与目标语言推理之间的差异。
mPMR的输入构造:
mPMR 采用MRC 架构,包含一个编码器和一个提取器。编码器将输入token X X X、查询 Q Q Q、上下文 C C C和特殊标记(即 [ CLS ] [\texttt{CLS}] [CLS]和 [ SEP ] [\texttt{SEP}] [SEP])的连接映射到隐藏表示 H H H中。对于任意两个token X i X_{i} Xi和 X j X_{j} Xj( i < j i<j i<j),提取器接收它们的上下文化表示 H i H_{i} Hi和 H j H_{j} Hj,并预测概率分数 S i , j S_{i,j} Si,j,表示token跨度 X i : j X_{i:j} Xi:j是查询答案 Q Q Q的概率。
mPMR抽取逻辑:
mPMR 以 Wiki Anchor Extrac- tion (WAE) 目标为指导,训练编码器和提取器。WAE 检查上下文中是否存在查询的答案。如果存在,WAE 会首先将查询和上下文视为相关,并提取 [CLS] 标记作为序列级相关性指标。然后,WAE 将从上下文中提取所有相应的答案。
训练数据集的构造:
训练 mPMR 需要有标记的(查询、上下文、答案)三元组。
收集了维基百科上 24 种语言的带锚注释的文章,这 24 种语言是使用最广泛的语言,涵盖了 XLU 任务中使用的合理数量的语言。
利用维基百科锚点获得了一对相关文章。这对文章的一边是对锚实体进行深入描述的文章,我们将其定义为定义文章。这对文章的另一侧被命名为提及文章,它提及了特定的锚文本。我们制作了一个可回答的 MRC 示例,其中锚点是答案,提及文章中锚点的周边文本是上下文,定义文章中锚点实体的定义是查询。此外,我们还可以通过将查询与没有锚关联的无关上下文配对生成一个无法回答的 MRC 示例。
PMR 将 MRC 查询和上下文构建为有效句子,以保持文本的连贯性。然而,句子分割工具通常不适用于低资源语言。为了弥补这一缺陷,我们没有使用句子分割,只是在 mPMR 中对维基百科文章进行了词标记化预处理。对于每个锚点,MRC 查询包括定义文章中的前 Q Q Q 个单词。为了防止预训练过程中的信息泄露,与 PMR 相似,我们将查询中的锚实体匿名为 [MASK] 标记。MRC 上下文由围绕锚点的 C C C 词组成。
随机提及位置,不进行固定,防止收到位置模型的影响:
如果上下文中的答案表现出固定的位置模式,那么模型就容易过度拟合位置捷径。
假设 MRC 上下文由锚点左右两侧的 C / 2 C/2 C/2 单词组成,模型可能会学习到上下文中间部分可能是答案的捷径。为了防止这种位置偏差,我们提出了一种随机答案位置法,允许答案出现在上下文中的任何位置。给定维基百科文章中的一个锚点,上下文包括锚点之前的 ξ \xi ξ单词和锚点之后的 C − ξ C-\xi C−ξ单词,其中 ξ \xi ξ是一个从0到 C C C的随机整数,在不同上下文中各不相同。根据 PMR,将当前上下文中所有与锚点相同的文本跨度视为有效答案。
3.原文阅读
Abstract
我们提出了多语言预训练机器阅读(mPMR),这是一种用于多语言机器阅读理解(MRC)式预训练的新方法。mPMR旨在指导多语言预训练语言模型(mPLMs)执行自然语言理解(NLU),包括多语言序列分类和跨度提取。为了在只有源语言微调数据的情况下实现跨语言泛化,现有的 mPLM 只能将 NLU 能力从源语言转移到目标语言。相比之下,mPMR 允许从 MRC 式预训练到下游任务直接继承多语言 NLU 能力。mPMR 还为跨语言跨度提取和序列分类提供了统一的求解器,从而可以提取理由来解释句对分类过程。
1 Introduction
mPLMs的跨语言能力,即直接应用到未训练过的语言中:
多语种预训练语言模型(缩写为 mPLMs)已在多种语言中展现出强大的自然语言理解(NLU)能力。特别是,尽管 mPLMs 只在英语等资源丰富的源语言上进行微调,但它们可以在未见过的目标语言上保持卓越的跨语言语言理解(XLU)能力。
介绍mPLMs多语言预训练的问题:
事实证明,优化 mPLM 的跨语言表征可以提高 XLU 的能力。例如,平行句子或双语词典等跨语言监督可以通过更好的语言对齐来增强跨语言表征。XLM-R (Con- neau et al., 2020a) 和 mT5 (Xue et al., 2021)表明,在预训练过程中适当加入更多语言会带来更好的跨语言表征。一些研究通过利用知识图谱中注释的多语言实体和关系,用事实知识丰富了跨语言表征。尽管存在差异:
但上述方法基本上都构建了更多样化的多语言语料库,用于预训练 mPLM。这些 mPLMs 可能会达到饱和点,并受到众所周知的多语言性诅咒。在这种情况下,从现有语言或未见语言中引入更多的训练数据来增强 mPLM 可能不会带来进一步的改进,甚至会对其跨语言表征造成损害。
介绍本文提出的mPMR模型(并不是在多语言上持续预训练):
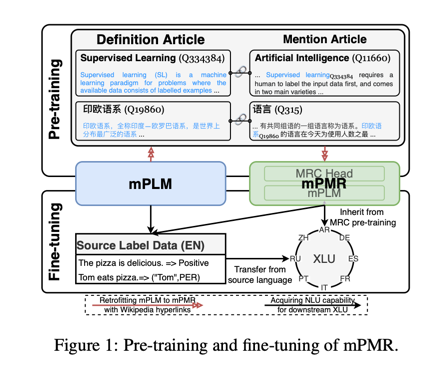
在本文中,我们不训练具有更好跨语言表征的新mPLM,而是提出了多语言预训练机器阅读器(mPMR),以直接指导现有 mPLM 在各种语言中形成 NLU。如图 1 所示,mPMR 类似于 PMR(Xu 等人,2022 年),用于构建带有维基百科超链接的多语言机器阅读编译(MRC)式数据。这些数据用于通过 MRC 式的持续预训练将 mPLM 改造成 mPMR。在改造过程(即预训练)中,mPMR 将共同学习多语言的一般句子分类和跨度提取能力。在 XLU 微调过程中,mPLM 仅依靠跨语言表征将 NLU 能力从源语言转移到目标语言。相比之下,mPMR 能够以统一的 MRC 形式将多语言 NLU 能力从 MRC 式预训练直接继承到下游任务,从而消除源语言微调与目标语言推理之间的差异(Zhou 等,2022a,b, 2023)。因此,与 mPLMs 相比,mPMR 在 XLU 中显示出更大的潜力。
通过统一的q/c构建和随机答案位置策略,提升在低资源语言上的性能:
为了提高 mPMR 在多种语言中的可扩展性,我们进一步提出了统一 Q/C 构建和随机答案位置策略,以完善 MRC 数据的整理。有了这两种策略,mPMR 可以更好地推广到低资源语言,并对位置偏差具有更强的鲁棒性(Ko 等人,2020)。
实验结果表明,在跨度提取方面,mPMR 比 XLM-R有明显的改进,在 TyDiQA 和 WikiAnn 上的平均改进分别高达 12.6 F1 和 8.7 F1。分析表明,mPMR 可以从更多的多语言 MRC 数据预训练中获益。我们还发现,mPMR 在下游任务中的收敛速度更快,并且能够利用其强大的提取能力解释序列分类过程。
2 mPMR
我们介绍了 mPMR 的 MRC 模型和训练数据。我们紧跟 PMR(Xu 等人,2022 年),并介绍了为实现多语言 MRC 式预训练所做的修改。
2.1.Model Pre-training
介绍mPMR的输入构造:
我们的 mPMR 采用与 Xu 等人(2022,2023)相同的 MRC 架构,包含一个编码器和一个提取器。编码器将输入token X X X、查询 Q Q Q、上下文 C C C和特殊标记(即 [ CLS ] [\texttt{CLS}] [CLS]和 [ SEP ] [\texttt{SEP}] [SEP])的连接映射到隐藏表示 H H H中。对于任意两个token X i X_{i} Xi和 X j X_{j} Xj( i < j i<j i<j),提取器接收它们的上下文化表示 H i H_{i} Hi和 H j H_{j} Hj,并预测概率分数 S i , j S_{i,j} Si,j,表示token跨度 X i : j X_{i:j} Xi:j是查询答案 Q Q Q的概率。
mPMR抽取逻辑:
mPMR 以 Wiki Anchor Extrac- tion (WAE) 目标为指导,训练编码器和提取器。WAE 检查上下文中是否存在查询的答案。如果存在,WAE 会首先将查询和上下文视为相关,并提取 [CLS] 标记作为序列级相关性指标。然后,WAE 将从上下文中提取所有相应的答案。
2.2.Multilingual MRC Data
训练数据集的构造:
训练 mPMR 需要有标记的(查询、上下文、答案)三元组。为了获得这些数据,我们收集了维基百科上 24 种语言的带锚注释的文章,这 24 种语言是使用最广泛的语言,涵盖了 XLU 任务中使用的合理数量的语言(Ri 等人,2022 年)。
如图 1 所示,我们利用维基百科锚点获得了一对相关文章。这对文章的一边是对锚实体进行深入描述的文章,我们将其定义为定义文章。这对文章的另一侧被命名为提及文章,它提及了特定的锚文本。我们制作了一个可回答的 MRC 示例,其中锚点是答案,提及文章中锚点的周边文本是上下文,定义文章中锚点实体的定义是查询。此外,我们还可以通过将查询与没有锚关联的无关上下文配对生成一个无法回答的 MRC 示例。
PMR 将 MRC 查询和上下文构建为有效句子,以保持文本的连贯性。然而,句子分割工具通常不适用于低资源语言。为了弥补这一缺陷,我们没有使用句子分割,只是在 mPMR 中对维基百科文章进行了词标记化预处理。对于每个锚点,MRC 查询包括定义文章中的前 Q Q Q 个单词。为了防止预训练过程中的信息泄露,与 PMR 相似,我们将查询中的锚实体匿名为 [MASK] 标记。MRC 上下文由围绕锚点的 C C C 词组成。
随机提及位置,不进行固定,防止收到位置模型的影响:
正如 Ko 等人(2020)所提到的,如果上下文中的答案表现出固定的位置模式,那么模型就容易过度拟合位置捷径。在我们的案例中,假设 MRC 上下文由锚点左右两侧的 C / 2 C/2 C/2 单词组成,模型可能会学习到上下文中间部分可能是答案的捷径。为了防止这种位置偏差,我们提出了一种随机答案位置法,允许答案出现在上下文中的任何位置。具体来说,给定维基百科文章中的一个锚点,上下文包括锚点之前的 ξ \xi ξ单词和锚点之后的 C − ξ C-\xi C−ξ单词,其中 ξ \xi ξ是一个从0到 C C C的随机整数,在不同上下文中各不相同。根据 PMR,我们将当前上下文中所有与锚点相同的文本跨度视为有效答案。
3 Experimental Setup
在 mPMR 中,编码器加载自 XLM-R Conneau 等人(2020 年),提取器随机初始化。然后,这两个组件将使用我们构建的多语言 MRC 数据进行持续的预训练。
下游任务:
我们在一系列跨度提取任务中对 mPMR 进行了评估,包括提取式问题解答 (EQA)、命名实体识别 (NER) 和基于方面的情感分析 (ABSA)。我们还在两个序列分类任务中评估了我们的 mPMR。我们效仿 Xu 等人(2022 年)的做法,将所有任务转换为 MRC 格式,以有效利用在 MRC 式预训练中获得的知识。在 EQA 方面,我们使用了 XQuAD Artetxe 等人(2020 年)、MLQA Lewis 等人(2020 年)和 TyDiQA Clark 等人(2020 年)。在 NER 方面,我们使用了 WikiAnn Pan 等人(2017 年)和 CoNLL Tjong Kim Sang(2002 年);Tjong Kim Sang 和 De Meulder(2003 年)。SemEval16 Pontiki 等人(2016 年)用于 ABSA 任务。在序列分类方面,我们使用了 XNLI Conneau 等人(2018 年)和 PAWS-X Yang 等人(2019 年)。
对比的模型:
我们将 mPMR 与最近改进跨语言表征的方法进行了比较,其中包括:
1)在大量语言上预先训练的模型:XLM-R Conneau 等人(2020 年)、mT5 Xue 等人(2021 年)和 VECO Luo 等人(2021 年);
2)利用多语言实体信息的模型:WikiCL Calixto 等人(2021 年)和 mLUKE-W Ri 等人(2022 年);
3)利用多语言关系信息的模型:KMLM Liu 等人(2022 年)。
为了公平比较,所有模型的参数大小大致相同。
4 Results and Analyses
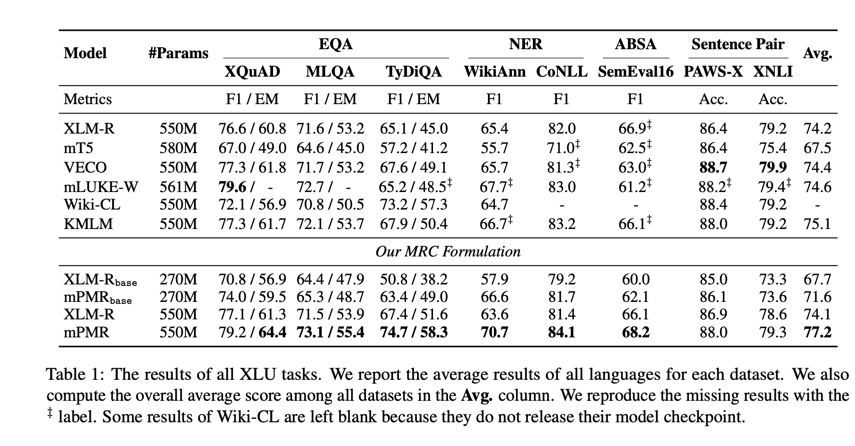
XLU 性能:
表 1 显示了各种 XLU 任务的结果。mPMR 的表现优于之前的所有方法,与最佳基线(即 KMLM)相比,mPMR 的绝对 F1 提高了 2.1。特别是在 TyDiQA 和 WikiAnn 上,mPMR 比 XLM-R 的 F1 分别提高了 7.3 和 7.1。如此显著的改进可能源于以下两个事实:(1) WikiAnn 包含更多的目标语言(即 40 种)。因此,由于缺乏特定语言的数据,现有方法可能难以将这些低资源语言与英语对齐。(2) TyDiQA 是一项更具挑战性的跨语言 EQA 任务,与 MLQA 和 XQuAD 相比,查询和答案之间的词汇重叠少 2 倍(Hu 等人,2020 年)。我们的 mPMR 通过 MRC 式预训练和纯英语 QA 微调获得了目标语言跨度提取能力,在更具挑战性的任务中取得了更大的性能提升。
mPMR 预训练:
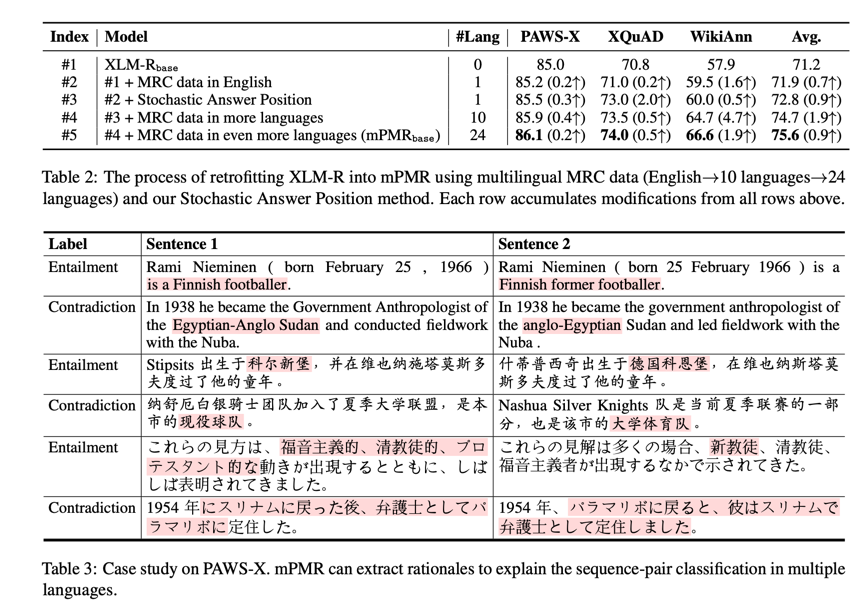
为了反映我们的 MRC 类型数据和随机答案分区方法对预训练的影响,我们在表 2 中逐一分析了从 XLM-R 开始的改造过程。我们的研究结果表明,所观察到的显著改进主要归功于多语言 MRC 数据的加入。引入英语 MRC 数据(模型 #2)带来的改进微乎其微,因为模型 #2 只能依靠跨语言表征来转移在 MRC 式预训练中获得的知识。当使用更多语言的 MRC 数据(模型 #4 和 #5)时,我们可以观察到在 XLU 任务上的显著改进。这可以归功于 MRC 式预训练在目标语言中直接继承的 NLU 能力。此外,使用我们的随机答案位置方法(模型 #3),mPMR 对位置偏差变得更加稳健,从而改进了 XLU 任务。
可解释的句对分类:
可解释的句对分类。在 PMR(Xu 等人,2022 年)的启发下,我们研究了能否利用 mPMR 的提取能力来解释句对分类。请注意,句对分类侧重于两个句子之间的差异。如果我们像 PMR 那样只用任务标签来构建查询,那么这种查询并不完全对应于上下文中的任何平均跨度,因此很难指导跨度提取。因此,我们利用了另一个模板"[CLS] label Sen-1 [SEP] Sen-2 [SEP]",在这个模板中,两个句子分别在查询和上下文中表示。在这个模板中,我们可以从 Sen-2 中提取出导致与 Sen-1 产生收缩或蕴含关系(即任务标签)的确切跨度。具体来说,我们将句子对传递给模型两次,将句子对中的每个句子分别指定为 Sen-2,并从这两个句子中提取概率分数最高的上下文跨度。
如表 3 所示,提取的跨度确实是决定两个句子之间关系的重要依据。这一发现证实了 mPMR 的提取能力可以恰当地用于解释句对分类过程。在微调过程中,提取能力可能会影响句对分类的学习,导致 XNLI 的 Acc.
mPMR 微调:
我们研究了 mPMR 对 XLU 微调的影响。图 2 显示,在 WikiAnn 上,即使微调 500 步,mPMR 的收敛速度也比 XLM-R 快,损失值极低。在测试集性能方面,mPMR 全面超越了 XLM-R,并表现出更高的稳定性。因此,与 XLM-R 相比,mPMR 为处理 XLU 任务提供了更好的起点。图 3 和图 4 提供了来自 XQuAD 和 PAWS-X 的更多示例。

5 Conclusions
本文提出了一种新颖的多语言 MRC 式预训练方法,即 mPMR。mPMR 为跨语言跨度提取和序列分类提供了统一的求解器,可将 NLU 能力从预训练直接转移到下游任务中。
6.Limitations
我们发现我们的工作存在以下两个局限性:
- 与原始文本不同,从维基百科构建 MRC 风格数据需要存在超链接。这种想法对于资源丰富的语言(如英语和中文)非常有效。但对于维基百科中超链接注释较少的语言,这种想法就不那么有效了,因为少量的 MRC 风格训练数据很难指导这些语言的 NLU 能力学习。一个可能的解决方案是探索其他数据重新来源,自动构建大规模的 MRC 数据进行预训练。
- 如表 1 所示,序列分类任务的改进不如跨度提取任务显著。我们认为,锚点的存在并不是结构化查询与上下文之间的强相关性指标。Chang 等人(2020 年)的研究也发现了这一点。因此,为序列分类预训练构建更多相关的查询-上下文对可能会弥补这一问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









