







文章目录
本篇的内容建立在对Grounded-SAM有一定基础,且上手实际使用过。如果对GroundingDINO或者Grounded-SAM没有接触,想要了解的同学可以参考我之前的博客:
Grounded-SAM技术文章阅读:全自动标注集成项目(Grounded-SAM)技术报告阅读:Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Grounded-SAM使用教程:Grounded-SAM(最强Zero-Shot视觉应用):本地部署及各个模块的全网最详细使用教程!-CSDN博客
GroundingDINO论文阅读:由文本提示检测图像任意目标(Grounding DINO)论文详细阅读: Marrying DINO for Open-Set Object Detection-CSDN博客
GroundingDINO源码解析:文本提示检测图像任意目标(Grounding DINO) 的使用以及全网最详细源码讲解
1.Grounded-SAM的应用前景
Grounded-SAM使用Grounding DINO作为开放集对象检测器,并与任何分割模型(SAM)相结合。这种整合可以根据任意文本输入检测和分割任何区域。从而能够在很多的业务场景中使用,例如:
- 视觉问答(VQA)系统:Grounded-SAM 可以用于构建视觉问答系统,在该系统中,用户可以提出关于图像内容的问题,然后模型可以基于图像和问题的语义对齐来回答问题,实现跨模态信息的传递。
- 图像描述生成:Grounded-SAM 可以用于生成图像描述,通过理解图像中的内容并结合文本生成语义丰富的描述,从而提高图像描述生成的准确性和流畅性。
- 商品搜索与推荐:在电子商务领域,可以利用 Grounded-SAM 来实现商品搜索和推荐系统。模型可以从商品图像和用户输入的文本描述中提取语义信息,帮助用户更准确地搜索到所需商品或获取个性化推荐。
- 虚拟助手和智能对话系统:Grounded-SAM 可以用于构建虚拟助手和智能对话系统,使系统能够更好地理解用户输入的语言和相关图像,从而提供更加智能化的交互和服务。
- 自动图像标注:Grounded-SAM 可以用于自动给图像添加标注,通过对图像内容和标注文本的语义对齐,模型可以生成准确描述图像内容的标注,提高图像管理和检索的效率。
2.Grounded-SAM在中文业务中的问题
Grounded-SAM作为GroundingDINO+SAM组成的集成项目,其结果依赖GroundingDINO的目标框检测,只有目标框准确地被划分出来,才能使得最后整体的结果提高。其中,GroundingDINO通过将基于Transformer的检测器DINO与真值预训练相结合,该检测器可以通过人类输入(如类别名称或指代表达)对任意物体进行检测。简单来说,Grounding DINO可以根据文字描述检测指定目标。现在开源的GroundingDINO预训练模型是英文版,因此,在中文业务中,应用GroundingDINO 可能会面临以下一些问题:
- 语义差异:中文语言与英文之间存在语义和文化上的差异,这可能会影响模型在理解中文文本描述时的准确性。
- 模型泛化:训练出的视觉 grounding 模型在中文业务中的泛化能力可能受到影响,因为模型可能更容易理解在训练集中出现频繁的概念而忽略罕见的概念。
我们在使用Grounded-SAM处理中文场景的时(例:自动图像标注),给出的文本提示(GroundingDINO中建议:使用
.分割不同类目的提示,我在使用的时候直接简化,即提示就是要检测的类别名称)都是由各种翻译器将中文提示翻译成英文提示,这样会出现—提示差异:由于中文翻译成英文后,与真正的英文表达之间会存在近义词的情况,可能改近义词在GroundingDINO的训练集中并没有出现过或出现次数较少,从而导致结果误差较大。
简单来说,中文翻译成英文后,并不能很好的迎合GroundingDINO检测器,因为它对应的训练集中同一个物品,使用的英文单词不一样。例如,对于休闲裤,Deepl翻译为Casual Pants,而GroundingDINO训练集中对应的是trousers 。下图中,我给出两个不同文本提示(休闲裤)的例子:可以发现,trousers 效果更好,识别出了右上角的休闲裤。
| Casual Pants | trousers |
|---|---|
 |  |
3.文本提示的修正-提高GroundingDINO图像目标检测
我针对提示差异主要的解决思路是:通过将中文翻译的英文提示与训练集中的英文类目做一个实体对齐操作,将我们的想要划分的提示尽可能的迎合现有开源的GroundingDINO模型,从而提高检测效果。下面我主要从3个部分展开介绍:
-
GroundingDINO训练数据集:给出GroundingDINO使用的训练数据集,并整合所有数据集中的类目
-
类目实体对齐召回:使用实体对齐/相似度算法,匹配出源文本类目与GroundingDINO训练数据集中最相近的实体类目。
3.1.GroundingDINO训练数据集
在GroundingDINO原文(在附录)中,指明了训练所使用的数据集分布:
B. Data Usage
我们在模型预训练中使用了三种类型的数据。
- Detection data. 根据 GLIP,我们通过将类别名称串联到文本提示中,将物体检测任务重新表述为短语实景任务。 我们使用 COCO 、O365 和 OpenImage(OI) 进行模型预训练。为了模拟不同的文本输入,我们在训练过程中从数据集中的所有类别中随机抽取类别名称。
- Grounding data. 我们使用 GoldG 和 RefC 数据作为基础数据。GoldG 和 RefC 都经过 MDETR 的预处理。这些数据可直接输入GroundingDINO。GoldG 包含 Flickr30k 实体 和 Visual Genome 中的图像。 RefC 包含 RefCOCO、RefCOCO+ 和 RefCOCOg 中的图像。
- Caption data. 为了提高模型在新类别上的性能,我们将语义丰富的标题数据输入到模型中。按照 GLIP 的方法,我们使用伪标签标题数据进行模型训练。训练有素的模型会生成伪标签。
O365 数据集有两个版本,我们分别称之为 O365v1 和 O365v2。O365v1 是 O365v2 的子集。O365v1 包含约 600K 幅图像,而 O365v2 包含约 170 万幅图像。根据之前的研究,我们在 O365v1 上预先训练了 Grounding-DINO-T,以便进行公平的比较。为了获得更好的结果,我们在 O365v2 上对 Grounding-DINO-L 进行了预训练。
在 GroundingDINO 中,Detection data、Grounding data 和 Caption data 分别指以下内容:
- Detection data(检测数据):通常指包含物体检测信息的数据。这种数据通常包括图像以及针对图像中物体的边界框(bounding box)信息,通常用于标识图像中的物体位置和类别。
- Grounding data(定位数据):Grounding 指的是将自然语言描述与图像中对应的区域进行关联。因此,Grounding data 是将自然语言描述(通常是文本)与图像中特定区域(通常是bounding box)之间的关联信息。这种数据用于训练模型来实现图像与文本之间的对齐和理解。
- Caption data(描述数据):指包含关于图像内容的自然语言描述的数据。通常是与图像相关的文本描述,用于描述图像中呈现的场景、对象等信息。
注意,Grounding data:是多模态数据集 即图片对应一个的是一个caption;Caption data:GLIP生成的也是一个图片对应的伪caption字幕。这两类数据集我目前并不需要(我目前的应用还不需要去解析这部分数据集)
对于Detection data:包含了三个:COCO,O365, OpenImage(OI)
3.1.1.COCO
COCO数据集官方地址: https://cocodataset.org/#download (80 Class)
COCO数据集描述:
COCO数据集是一个可用于图像检测,语义分割和图像标题生成的大规模数据集。它有超过330K张图像(其中220K张是有标注的图像),包含150万个目标,80个目标类别,每张图像包含五句图像的语句描述,且有250,000个带关键点标注的行人。
COCO数据集类目(80 class):
{1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorbike', 5: 'aeroplane', 6: 'bus', 7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant', 12: 'stop sign', 13: 'parking meter', 14: 'bench', 15: 'bird', 16: 'cat', 17: 'dog', 18: 'horse', 19: 'sheep', 20: 'cow', 21: 'elephant', 22: 'bear', 23: 'zebra', 24: 'giraffe', 25: 'backpack', 26: 'umbrella', 27: 'handbag', 28: 'tie', 29: 'suitcase', 30: 'frisbee', 31: 'skis', 32: 'snowboard', 33: 'sports ball', 34: 'kite', 35: 'baseball bat', 36: 'baseball glove', 37: 'skateboard', 38: 'surfboard', 39: 'tennis racket', 40: 'bottle', 41: 'wine glass', 42: 'cup', 43: 'fork', 44: 'knife', 45: 'spoon', 46: 'bowl', 47: 'banana', 48: 'apple', 49: 'sandwich', 50: 'orange', 51: 'broccoli', 52: 'carrot', 53: 'hot dog', 54: 'pizza', 55: 'donut', 56: 'cake', 57: 'chair', 58: 'sofa', 59: 'pottedplant', 60: 'bed', 61: 'diningtable', 62: 'toilet', 63: 'tvmonitor', 64: 'laptop', 65: 'mouse', 66: 'remote', 67: 'keyboard', 68: 'cell phone', 69: 'microwave', 70: 'oven', 71: 'toaster', 72: 'sink', 73: 'refrigerator', 74: 'book', 75: 'clock', 76: 'vase', 77: 'scissors', 78: 'teddy bear', 79: 'hair drier', 80: 'toothbrush'}
3.1.2.O365
O365数据集官方地址: Objects365 Dataset (80 Class)
O365数据集描述:
该数据集拥有超过600,000个图像,365个类别和超过1000万个高质量的边界框。由精心设计的三步注释管道手动标记,它是迄今为止最大的对象检测数据集合(带有完整注释),并为社区创建了更具挑战性的基准。
Objects365在63万余张图像上标注了365个对象类,训练集中有超过1000万个边界框,超越了Pascal VOC、ImageNet和COCO数据集。下表给出了Objects365与之前所有的目标检测数据集在图像数量、边界框数量、对象类数量等参数上的对比。经过研究后发现,Objects365的图像数量是COCO的5倍,边界框是COCO的11倍,对象种类数和平均边界框数也是最大的。Objects365包括了人、衣物、居室、浴室、厨房、办公、电器、交通、食物、水果、蔬菜、动物、运动、乐器14个大类,每一类都有数十个小类。
O365数据集类目(365 class):
{1: 'Person', 2: 'Sneakers', 3: 'Chair', 4: 'Other Shoes', 5: 'Hat', 6: 'Car', 7: 'Lamp', 8: 'Glasses', 9: 'Bottle', 10: 'Desk', 11: 'Cup', 12: 'Street Lights', 13: 'Cabinet/shelf', 14: 'Handbag/Satchel', 15: 'Bracelet', 16: 'Plate', 17: 'Picture/Frame', 18: 'Helmet', 19: 'Book', 20: 'Gloves', 21: 'Storage box', 22: 'Boat', 23: 'Leather Shoes', 24: 'Flower', 25: 'Bench', 26: 'Potted Plant', 27: 'Bowl/Basin', 28: 'Flag', 29: 'Pillow', 30: 'Boots', 31: 'Vase', 32: 'Microphone', 33: 'Necklace', 34: 'Ring', 35: 'SUV', 36: 'Wine Glass', 37: 'Belt', 38: 'Moniter/TV', 39: 'Backpack', 40: 'Umbrella', 41: 'Traffic Light', 42: 'Speaker', 43: 'Watch', 44: 'Tie', 45: 'Trash bin Can', 46: 'Slippers', 47: 'Bicycle', 48: 'Stool', 49: 'Barrel/bucket', 50: 'Van', 51: 'Couch', 52: 'Sandals', 53: 'Bakset', 54: 'Drum', 55: 'Pen/Pencil', 56: 'Bus', 57: 'Wild Bird', 58: 'High Heels', 59: 'Motorcycle', 60: 'Guitar', 61: 'Carpet', 62: 'Cell Phone', 63: 'Bread', 64: 'Camera', 65: 'Canned', 66: 'Truck', 67: 'Traffic cone', 68: 'Cymbal', 69: 'Lifesaver', 70: 'Towel', 71: 'Stuffed Toy', 72: 'Candle', 73: 'Sailboat', 74: 'Laptop', 75: 'Awning', 76: 'Bed', 77: 'Faucet', 78: 'Tent', 79: 'Horse', 80: 'Mirror', 81: 'Power outlet', 82: 'Sink', 83: 'Apple', 84: 'Air Conditioner', 85: 'Knife', 86: 'Hockey Stick', 87: 'Paddle', 88: 'Pickup Truck', 89: 'Fork', 90: 'Traffic Sign', 91: 'Ballon', 92: 'Tripod', 93: 'Dog', 94: 'Spoon', 95: 'Clock', 96: 'Pot', 97: 'Cow', 98: 'Cake', 99: 'Dinning Table', 100: 'Sheep', 101: 'Hanger', 102: 'Blackboard/Whiteboard', 103: 'Napkin', 104: 'Other Fish', 105: 'Orange/Tangerine', 106: 'Toiletry', 107: 'Keyboard', 108: 'Tomato', 109: 'Lantern', 110: 'Machinery Vehicle', 111: 'Fan', 112: 'Green Vegetables', 113: 'Banana', 114: 'Baseball Glove', 115: 'Airplane', 116: 'Mouse', 117: 'Train', 118: 'Pumpkin', 119: 'Soccer', 120: 'Skiboard', 121: 'Luggage', 122: 'Nightstand', 123: 'Tea pot', 124: 'Telephone', 125: 'Trolley', 126: 'Head Phone', 127: 'Sports Car', 128: 'Stop Sign', 129: 'Dessert', 130: 'Scooter', 131: 'Stroller', 132: 'Crane', 133: 'Remote', 134: 'Refrigerator', 135: 'Oven', 136: 'Lemon', 137: 'Duck', 138: 'Baseball Bat', 139: 'Surveillance Camera', 140: 'Cat', 141: 'Jug', 142: 'Broccoli', 143: 'Piano', 144: 'Pizza', 145: 'Elephant', 146: 'Skateboard', 147: 'Surfboard', 148: 'Gun', 149: 'Skating and Skiing shoes', 150: 'Gas stove', 151: 'Donut', 152: 'Bow Tie', 153: 'Carrot', 154: 'Toilet', 155: 'Kite', 156: 'Strawberry', 157: 'Other Balls', 158: 'Shovel', 159: 'Pepper', 160: 'Computer Box', 161: 'Toilet Paper', 162: 'Cleaning Products', 163: 'Chopsticks', 164: 'Microwave', 165: 'Pigeon', 166: 'Baseball', 167: 'Cutting/chopping Board', 168: 'Coffee Table', 169: 'Side Table', 170: 'Scissors', 171: 'Marker', 172: 'Pie', 173: 'Ladder', 174: 'Snowboard', 175: 'Cookies', 176: 'Radiator', 177: 'Fire Hydrant', 178: 'Basketball', 179: 'Zebra', 180: 'Grape', 181: 'Giraffe', 182: 'Potato', 183: 'Sausage', 184: 'Tricycle', 185: 'Violin', 186: 'Egg', 187: 'Fire Extinguisher', 188: 'Candy', 189: 'Fire Truck', 190: 'Billards', 191: 'Converter', 192: 'Bathtub', 193: 'Wheelchair', 194: 'Golf Club', 195: 'Briefcase', 196: 'Cucumber', 197: 'Cigar/Cigarette ', 198: 'Paint Brush', 199: 'Pear', 200: 'Heavy Truck', 201: 'Hamburger', 202: 'Extractor', 203: 'Extention Cord', 204: 'Tong', 205: 'Tennis Racket', 206: 'Folder', 207: 'American Football', 208: 'earphone', 209: 'Mask', 210: 'Kettle', 211: 'Tennis', 212: 'Ship', 213: 'Swing', 214: 'Coffee Machine', 215: 'Slide', 216: 'Carriage', 217: 'Onion', 218: 'Green beans', 219: 'Projector', 220: 'Frisbee', 221: 'Washing Machine/Drying Machine', 222: 'Chicken', 223: 'Printer', 224: 'Watermelon', 225: 'Saxophone', 226: 'Tissue', 227: 'Toothbrush', 228: 'Ice cream', 229: 'Hotair ballon', 230: 'Cello', 231: 'French Fries', 232: 'Scale', 233: 'Trophy', 234: 'Cabbage', 235: 'Hot dog', 236: 'Blender', 237: 'Peach', 238: 'Rice', 239: 'Wallet/Purse', 240: 'Volleyball', 241: 'Deer', 242: 'Goose', 243: 'Tape', 244: 'Tablet', 245: 'Cosmetics', 246: 'Trumpet', 247: 'Pineapple', 248: 'Golf Ball', 249: 'Ambulance', 250: 'Parking meter', 251: 'Mango', 252: 'Key', 253: 'Hurdle', 254: 'Fishing Rod', 255: 'Medal', 256: 'Flute', 257: 'Brush', 258: 'Penguin', 259: 'Megaphone', 260: 'Corn', 261: 'Lettuce', 262: 'Garlic', 263: 'Swan', 264: 'Helicopter', 265: 'Green Onion', 266: 'Sandwich', 267: 'Nuts', 268: 'Speed Limit Sign', 269: 'Induction Cooker', 270: 'Broom', 271: 'Trombone', 272: 'Plum', 273: 'Rickshaw', 274: 'Goldfish', 275: 'Kiwi fruit', 276: 'Router/modem', 277: 'Poker Card', 278: 'Toaster', 279: 'Shrimp', 280: 'Sushi', 281: 'Cheese', 282: 'Notepaper', 283: 'Cherry', 284: 'Pliers', 285: 'CD', 286: 'Pasta', 287: 'Hammer', 288: 'Cue', 289: 'Avocado', 290: 'Hamimelon', 291: 'Flask', 292: 'Mushroon', 293: 'Screwdriver', 294: 'Soap', 295: 'Recorder', 296: 'Bear', 297: 'Eggplant', 298: 'Board Eraser', 299: 'Coconut', 300: 'Tape Measur/ Ruler', 301: 'Pig', 302: 'Showerhead', 303: 'Globe', 304: 'Chips', 305: 'Steak', 306: 'Crosswalk Sign', 307: 'Stapler', 308: 'Campel', 309: 'Formula 1 ', 310: 'Pomegranate', 311: 'Dishwasher', 312: 'Crab', 313: 'Hoverboard', 314: 'Meat ball', 315: 'Rice Cooker', 316: 'Tuba', 317: 'Calculator', 318: 'Papaya', 319: 'Antelope', 320: 'Parrot', 321: 'Seal', 322: 'Buttefly', 323: 'Dumbbell', 324: 'Donkey', 325: 'Lion', 326: 'Urinal', 327: 'Dolphin', 328: 'Electric Drill', 329: 'Hair Dryer', 330: 'Egg tart', 331: 'Jellyfish', 332: 'Treadmill', 333: 'Lighter', 334: 'Grapefruit', 335: 'Game board', 336: 'Mop', 337: 'Radish', 338: 'Baozi', 339: 'Target', 340: 'French', 341: 'Spring Rolls', 342: 'Monkey', 343: 'Rabbit', 344: 'Pencil Case', 345: 'Yak', 346: 'Red Cabbage', 347: 'Binoculars', 348: 'Asparagus', 349: 'Barbell', 350: 'Scallop', 351: 'Noddles', 352: 'Comb', 353: 'Dumpling', 354: 'Oyster', 355: 'Table Teniis paddle', 356: 'Cosmetics Brush/Eyeliner Pencil', 357: 'Chainsaw', 358: 'Eraser', 359: 'Lobster', 360: 'Durian', 361: 'Okra', 362: 'Lipstick', 363: 'Cosmetics Mirror', 364: 'Curling', 365: 'Table Tennis'}
3.1.3.OpenImage(OI)
OpenImage(OI)数据集官方地址: https://github.com/amukka/openimages (19995 Class)
OpenImage(OI)数据集描述:
Open Images 是一个包含约 900 万个图片 URL 的数据集,这些 URL 都标注了图片级标签和边界框,涵盖数千个类别。数据集分为训练集(9,011,219 幅图像)、验证集(41,620 幅图像)和测试集(125,436 幅图像)。在 V2 版本中,V1 的验证集被分为验证和测试两部分。这样做的目的是为了使评估更加简便易行。图像都标注了图像级标签和边界框。
OpenImage(OI)数据集类目(365 class):
OpenImage(OI)类目数量太大,这里就不放出来了,给出下载链接:https://storage.googleapis.com/openimages/2017_11/classes_2017_11.tar.gz
3.1.4.三个数据集的类目整合
-
COCO,0365,OpenImage(OI)数据集中的类目被放在
coco_class.csv,o365_class.csv,openimage_class.csv中,格式如下图:
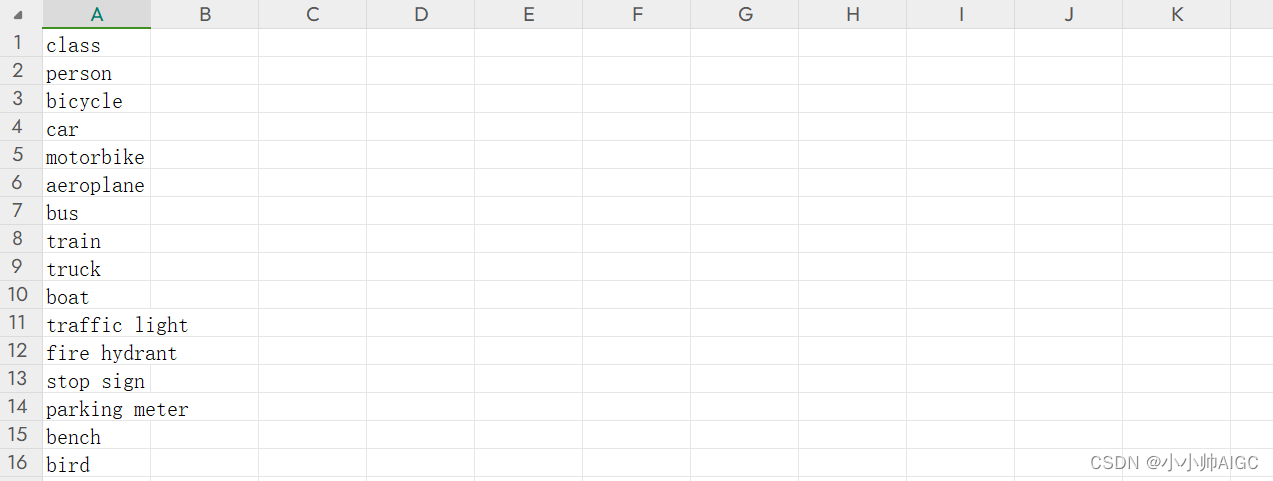
-
整合所有的类目(去重),整合后的类目被放在groundingDINO_class.csv中:
import pandas as pd import json def combine_class(class_name): all_class_dict={} for i in range(len(class_name)): path=f'./data/{class_name[i]}_class.csv' current_class_dict=pd.read_csv(path).to_dict(orient='records') for j in range(len(current_class_dict)): current_class_name=current_class_dict[j]['class'].lower() if current_class_name not in all_class_dict: all_class_dict[current_class_name]=str() else: print(current_class_name) all_class_list=[] for key in all_class_dict: all_class_list.append({'class':key}) all_class_list_df=pd.DataFrame(all_class_list) all_class_list_df.to_csv('./data/groundingDINO_class.csv',index=False) if __name__ == '__main__': #read&combine all class class_name=['coco','o365','openimage'] combine_class(class_name)
3.2.(source-target)类目实体对齐召回
3.2.1.计算GroundingDINO训练类目的实体嵌入
实体相似度计算的算法有很多,大家可以自行去选择效果更好的算法模型,我使用的是基础的CLIP模型来计算单词/词组的Embedding。
对于CLIP的介绍/部署/使用可以参考我另一个文章:多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读
这里不做过多赘述。具体代码逻辑如下:
-
首先会读取3.1节获取的GroundingDINO总的类目文件。
-
加载预训练的 CLIP 模型和预处理器,使用的预训练模型是 “ViT-L-14-336px.pt”。
-
对传入的 class_name_dict 中的每个类别名进行实体嵌入处理:
- 使用 CLIP 模型对类别名进行 tokenize 处理并转换为相应的张量。
- 使用 CLIP 模型对文本进行编码得到文本特征。
- 将得到的文本特征转换为字符串形式,并放入 result_dict 中。
-
最后,将处理后的 result_dict 转换为 DataFrame,并将结果保存到csv文件中。
def process_embedding(): path = './data/groundingDINO_class.csv' class_name_dict = pd.read_csv(path).to_dict(orient='records') device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-L-14-336px.pt", device=device) result_dict=[] for i in tqdm(range(len(class_name_dict))): current_class_name=class_name_dict[i]['class'] text = clip.tokenize([current_class_name]).to(device) with torch.no_grad(): text_features = model.encode_text(text).cpu().numpy().tolist() text_features = '{' + str(text_features[0])[1:-1] + '}' result_dict.append({'id':i+1,'class':current_class_name,'text_features':text_features}) if result_dict != []: result_dict_df = pd.DataFrame(result_dict) result_dict_df.to_csv('./data/groundingDINO_class_embedding.csv', index=False) if __name__=="__main__": # compute embedding embedding_info=process_embedding()
3.2.2.计算源类目的嵌入并召回
- 首先需要将源中文类目通过翻译API转换为英文,这里可以先翻译好保存起来,也可以使用各种翻译的API来执行运行时翻译,具体的API有百度翻译/有道翻译/Deepl,但是这些翻译API有的是收费,有的是有一定额度限制,我在这里给出一个完全免费的翻译API,可能翻译的结果有点机翻,但是架不住免费。
翻译API地址:文本翻译接口 - openai接口测试 (apifox.cn)
我这里将翻译后的结果保存到了一个json文件中,文件名为translate_category_zh2en.json,具体jsonge格式如下:
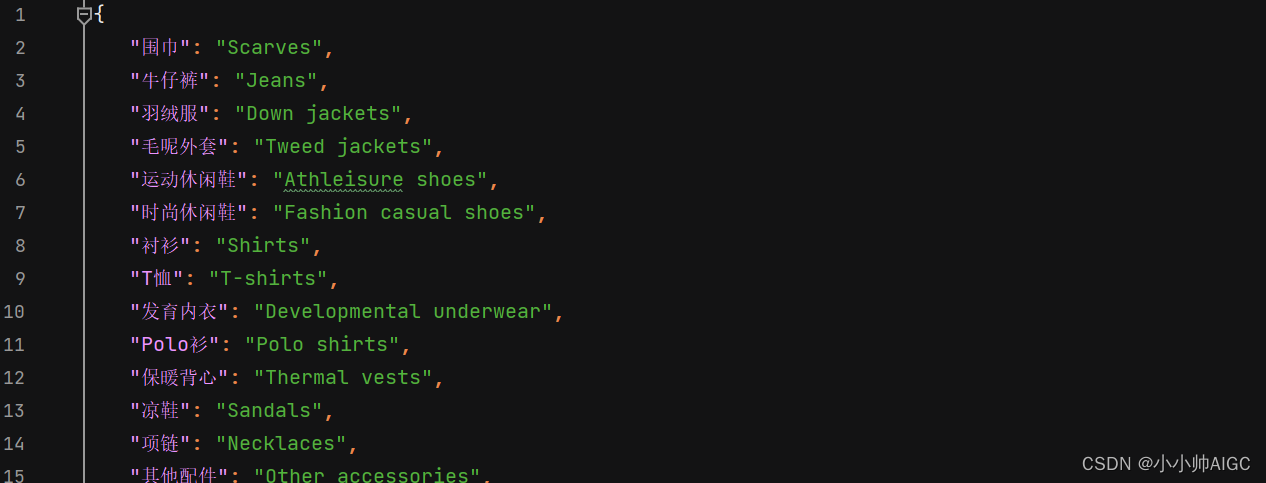
-
对翻译后的每个源英文版类目计算Embedding并与所有的GroundingDINO训练类目Embedding计算相似度,按照相似度排序执行召回前Top-K个目标类目。
def process_similarity(process_data_dict): adb_conn,adb_cursor=create_adb_conn() all_result_recall={} for i in tqdm(range(len(process_data_dict))): current_name=process_data_dict[i]['en_class'].lower() all_result_recall[process_data_dict[i]['ch_class']]=[] text = clip.tokenize(current_name).to(device) with torch.no_grad(): text_features = model.encode_text(text).cpu().numpy().tolist()[0] #compute recall recall_result=recall(adb_conn=adb_conn,adb_cursor=adb_cursor,text_features=text_features,table_name='test.groundingdino_class_emb') for j in range(len(recall_result)): all_result_recall[process_data_dict[i]['ch_class']].append(recall_result[j]) with open('./data/recall_result.json','w',encoding='utf-8') as json_file: json.dump(all_result_recall,json_file,indent=3, ensure_ascii=False) if __name__=="__main__": #read_valid_class_ch2en with open('./data/translate_category_zh2en.json','r',encoding='utf-8') as json_file: process_data_dict=json.load(json_file) class_list=[] for key,value in process_data_dict.items(): class_list.append({'ch_class':key,'en_class':value}) #process similarity process_similarity(class_list)我使用的结构是计算源类目嵌入和执行相似度召回是同时进行的,相似度计算使用的是余弦相似度,召回使用的阿里云的ADB数据库来执行的,所以对于召回的代码就不放出来了,大家不一定能用上,这里的召回,最简单的方式就是直接计算两个embedding的相似度,然后对相似度得分进行排序,从来实现召回的效果:
def compute(item_emb_1,item_emb_2): s = sum([a * b for a, b in zip(item_emb_1, item_emb_2)]) return s -
我在这里给定过滤阈值
filter_threshold=0.9,首先,通过read_recall_filter函数从文件中读取recall_result.json中的数据,然后根据设定的阈值filter_threshold对数据进行过滤,只保留得分高于阈值的结果,并将筛选后的结果保存到recall_result_filter.json文件。然后,update_translate_category_zh2en函数更新一个包含中文到英文翻译的映射字典translate_category_zh2en.json,根据之前筛选得到的结果recall_result_filter.json对其中的部分映射进行更新,将对应的英文类别信息替换为筛选后的结果中的类别信息,然后将更新后的映射保存到translate_category_zh2en_filter.json文件中。import json def read_recall_filter(): with open('./data/recall_result.json','r',encoding='utf-8') as json_file: recall_dict=json.load(json_file) filter_result={} filter_threshold=0.9 for key,value in recall_dict.items(): for i in range(len(value)): if value[i]['scores']>filter_threshold: filter_result[key]={'class':value[i]['class'],'scores':value[i]['scores']} break print(len(filter_result)) with open('./data/recall_result_filter.json','w',encoding='utf-8') as json_file: json.dump(filter_result,json_file,indent=3,ensure_ascii=False) def update_translate_category_zh2en(): with open('./data/recall_result_filter.json','r',encoding='utf-8') as json_file: recall_result_filter_dict=json.load(json_file) with open('./data/translate_category_zh2en.json','r',encoding='utf-8') as json_file: translate_category_zh2en_dict=json.load(json_file) for key in translate_category_zh2en_dict: if key in recall_result_filter_dict: translate_category_zh2en_dict[key]=recall_result_filter_dict[key]['class'] with open('./data/translate_category_zh2en_filter.json','w',encoding='utf-8') as json_file: json.dump(translate_category_zh2en_dict,json_file,indent=3,ensure_ascii=False) if __name__=="__main__": #read recall_result read_recall_filter() #update translate category zh2en update_translate_category_zh2en()
最终,完成整个流程,即中文类目提示->(经过翻译)->英文类目提示->(GroundingDINO类目召回)->修正后英文类目提示,从而提升整体性能。
我做的电商领域的自动标注/识别出每个主图的主要商品信息,这种方式使得效果有一点提升,但是不是试用所有的场景,改可以作为当大家发现模型效果不够好的时候,可以尝试下该方法是否有所改善,在后续我可能会对我的垂直领域进行微调操作,从而满足更细致的提示以检测目标。


















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









