







OARelatedWork: A Large-Scale Dataset of Related Work Sections with Full-texts from Open Access Sources
OARelatedWork: 从开放存取源获取全文的相关工作章节大型数据集
paper: https://arxiv.org/abs/2405.01930
GitHub: https://github.com/KNOT-FIT-BUT/OAPapers
本文是一篇介绍数据集的论文,数据集是一个包含相关工作及其相关引文的大型数据集,其中数据来源为CORE和Semantic Scholar,最终获得了 94 450 篇包含相关工作章节的论文,以及 5 824 689 篇在选定的相关工作章节中被唯一引用的论文。
文章目录~
1.背景动机
介绍相关工作生成任务的背景与缺陷:
相关工作生成是多文档摘要的一个不断发展的子领域,因为考虑到现有模型的限制,对长输入内容进行抽象总结在技术上要求很高。此外,生成相关工作的任务通常被划分为生成单独的段落。这使得任务变得更容易,但同时,这种简化也使得无法评估一个模型是否能够生成结构良好的相关工作部分,因为它只能在简短的子摘要上对模型进行基准测试。生成整篇相关作品不仅需要生成器,还需要评估指标。如何自动评估摘要仍是一个未决问题
本文给出的数据集以及评价指标:
为了解决上述问题,本研究引入了一个大型数据集,用于生成完整的相关工作部分,提供自动处理的被引论文和目标论文全文。
2.DataSet介绍
1.数据来源:
为了获得最终数据集,使用了两个来源,CORE以及Semantic Scholar语料库。
CORE共有540万份文档,每份文档都包含解析后的全文、参考书目以及标题和作者等其他元数据。
Semantic Scholar共包含1.292亿2千多万篇文档。约 90% 的论文仅有摘要。
本文将 CORE 和 Semantic Scholar 两个语料库合并在一起 ,应用了转换、重复数据删除和内容过滤,得到了一个大小为 124.9M 的语料库文档集合:OAPapers。
为了表示每份文档,使用 JSON 格式,其中包含文档内容的树形表示法。其中包含章节、子章节、段落和句子的多个层次。
2.相关工作数据构造:
在语料库中搜索包含类似相关工作部分的文档。这意味着我们不仅要搜索标题为_“相关工作"的部分,还要搜索"背景”、“相关文献"和"文献综述”_等部分。通过这种方式,找到了 50 多万份具有相关工作类章节的文档,确保生成相关任务的每份目标文档和所有引用文档都有摘要。
最终获得了 94 450 篇包含相关工作章节的论文,以及 5 824 689 篇在选定的相关工作章节中被唯一引用的论文。在所有这些唯一被引用的论文中,82% 为纯摘要论文。由于希望提供一个适合评估全文模型的数据集,因此决定确保验证集和测试集中的每个相关工作部分都有全文引用文档。为此,本文找到了满足这一条件的所有文档,并将其中的 50%作为测试集,30% 作为验证集,其余的作为训练集。
注意:在获取与相关工作类似部分的文档时,注意到整个语料库的原始分布发生了领域偏移。尽管数据集包含了指定研究领域的其他领域(如心理学、物理学或医学)的文档,但数据显示,这些文档主要转向计算机科学。
3.原文阅读
Abstract
本文介绍了 OARelatedWork,这是第一个用于生成相关工作的大规模多文献汇总数据集,其中包含整个相关工作部分和被引用论文的全文。该数据集包含 94 450 篇论文和 5 824 689 篇唯一引用论文。该数据集是专为自动生成相关作品的任务而设计的,目的是使该领域转向从所有可用内容中生成完整的相关作品部分,而不是仅从摘要中生成部分相关作品部分,后者是目前该领域有吸引力方法的主流。我们的研究表明,当使用全部内容而不是摘要时,提取式总结的额定上限在 ROUGE- 2 分数上提高了 217%。此外,我们还展示了完整内容数据对天真、oracle、tra- ditional 和基于转换器的基线的益处。由于输入长度有限,长输出(如相关工作章节)给 BERTScore 等自动评估指标带来了挑战。我们利用 BERTScore 提出并评估了一种元指标,从而解决了这一问题。尽管是在较小的区块上运行,但我们表明,与原始 BERTScore 相比,这种元度量与人类判断相关。
1 Introduction
介绍相关工作生成任务的背景:
相关工作生成是多文档摘要的一个不断发展的子领域。相关作品部分不是简单的参考文献摘要,因为适当的相关工作部分是将特定工作置于相关论文的背景下,讨论其异同。这就对模型、相关工作部分的生成以及用于训练这些模型的数据集提出了很高的要求。如图 1 所示,模型需要处理由目标论文和所有要引用的参考文献组成的大量文本输入。数据集必须包括所有必要的数据,这可能具有挑战性,因为有些科学论文是在付费墙之后。此外,即使可以获得这些数据,也很难对其进行自动处理,因为它们通常是 PDF 格式。幸运的是,现有的工具可以将其转换为更适合机器使用的格式。例如,GRO-BID(GRO,2008-2023 年)就是专门为处理科学论文而设计的,符合该领域的最先进水平(Meuschke 等人,2023 年)。
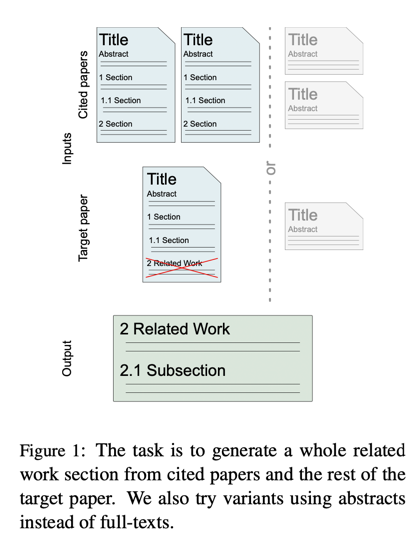
现有相关工作生成任务的缺陷:
虽然 Hoang 和 Kan(2010 年)的开创性工作最初使用全文参考文献和主题层次树来确定目标论文,但现在通常只使用摘要(Lu 等人,2020 年;Chen 等人,2021 年、2022 年;Liu 等人,2023 年),因为考虑到现有模型的限制,对长输入内容进行抽象总结在技术上要求很高。此外,生成相关工作的任务通常被划分为生成单独的段落。这使得任务变得更容易,但同时,这种简化也使得无法评估一个模型是否能够生成结构良好的相关工作部分,因为它只能在简短的子摘要上对模型进行基准测试。
生成整篇相关作品不仅需要生成器,还需要评估指标。如何自动评估摘要仍是一个未决问题
本文给出的数据集以及评价指标:
为了解决上述问题,本研究引入了一个大型数据集(第 2.2 节),用于生成完整的相关工作部分,提供自动处理的被引论文和目标论文全文。为了克服基于嵌入的评价指标(如 BERTScore,Zhang 等人,2020 年)在长度上的局限性,我们提出并评估了一种用于评价长篇摘要的元指标(第 4 节)。我们创建了几个基线模型,并用它们来分析不同类型内容的优势(第 6.2 节)。通过使用完整的输入,我们发现这些模型能够利用这些额外的上下文,并产生明显更好的结果。PRIMERA Xiao 等人(2022 年)的基线模型从仅使用摘要时的 0.08 ROUGE-2 提高到使用所有可用数据时的 0.15 ROUGE-2。
2 OARelatedWork Dataset
本节介绍了所使用的数据源,并描述了用于创建数据集的管道。
2.1.Corpus Processing
为了获得最终数据集,我们首先创建了一个科学文章语料库。为了建立我们的语料库,我们使用了两个来源,即CORE以及Semantic Scholar语料库。
CORE 的创建者向我们提供了由 GROBID 转化为 XML/TEI 格式的论文。共有540万份文档,每份文档都包含解析后的全文、参考书目以及标题和作者等其他元数据。与Semantic Scholar数据不同的是,这些文档没有指定年份、研究领域或DOI。我们使用微软学术图谱(MAG)来获取这些字段。此外,书目也没有链接。提到的论文没有已知的 ID,因此我们需要进行书目链接。所使用的 CORE 文集包含 2020 年之前的论文。
关于Semantic Scholar语料库,我们使用了S2ORC数据集和Semantic Scholar API提供的论文。截至2023年,该数据集共包含1.292亿2千多万篇文档。该数据集的规模远大于CORE数据集,因为它也包含仅有摘要的论文。约 90% 的论文仅有摘要。
我们将 CORE 和 Semantic Scholar 两个语料库合并在一起 ,应用了转换、重复数据删除和内容过滤,得到了一个大小为 124.9M 的语料库。我们称这个文档集合为_OAPapers_。
为了表示每份文档,我们使用 JSON 格式,其中包含文档内容的树形表示法。其中包含章节、子章节、段落和句子的多个层次。我们认为,这种树形表示法可能对未来的用例很有帮助,因为它可以让你在输入模型时轻松选择文档的部分内容或标记内容部分。
2.1.1 Bibliography Linking
我们决定进行书目链接有两个原因。首先,我们使用的数据源包含没有确定书目的文档(CORE)。第二个原因是为了丰富现有的链接。
在这项任务中,我们使用了 MAG、Semantic Scholar引文图谱和我们自己的搜索器。我们将Semantic Scholar视为主要来源,但在处理过程中,我们发现还可以使用 MAG 获取更多链接。
我们使用了自己的搜索器,尽管它的贡献微乎其微。已识别的书目条目数量仅增加了 0.6%,即大约 1160 万个新链接。我们的搜索分多个阶段进行。第一阶段是候选检索。它包括使用 SQLite 数据库对文档标题进行字符串匹配搜索。我们允许为匹配的标题添加不同的后缀。此外,还进行近似匹配。它是在使用特征定位敏感哈希算法创建的嵌入向量空间中寻找 k 个近邻。我们使用这种方法是因为它的计算复杂度较低。最后一步是过滤阶段。
该过滤器可过滤记录的标题、作者和年份。标题和作者字段是必填字段。如果要匹配的两条记录的年份字段都是已知的,则相差不能超过两年。按照 Lo 等人(2020)的方法,我们用 Jaccard 指数和包含度量的调和平均值来计算 title 的相似度得分:
C
=
∣
N
1
∩
N
2
∣
min
(
∣
N
1
∣
,
∣
N
2
∣
)
,
(1)
C=\frac{|N_{1}\cap N_{2}|}{\min(|N_{1}|,|N_{2}|)}\,, \tag{1}
C=min(∣N1∣,∣N2∣)∣N1∩N2∣,(1)
其中
N
1
N_{1}
N1 和
N
2
N_{2}
N2 是匹配字符串的词集,也用于Jaccard index。
只有相似度超过 0.75 阈值的标题才会被视为匹配。在匹配作者时,我们要求至少有一对作者是匹配的。匹配再次使用相似度量(使用相同的阈值),但现在只是包含度量,因为我们希望在一个来源中只有一个姓氏的情况下也能获得高相似度。我们注意到,经常出现的情况是,一个来源中的名字用首字母表示,而另一个来源中的名字用全称表示。因此,我们也为每个名字创建了一个首字母版本,并在匹配时加以考虑。
为了通过 Jaccard / 包含度量和字符串匹配搜索计算相似性,我们首先通过 Unidecode将字符串转换为近似的 ASCII 格式,去除非单词字符,转换为小写字母,并去除重复字符,从而对标题和作者(作者不用于字符串匹配搜索)进行规范化处理。
为了评估我们的搜索结果,我们决定对搜索结果进行人工评估,结果发现在 50 个案例中,有 47 个案例的搜索结果是正确的。
2.1.2 Content Hierarchy
在所使用的数据源中,文件已被解析为章节和段落。尽管如此,我们还是决定在这种浅层结构上增加更多层次,因为我们相信这将提高数据的可用性。理想情况下,我们希望将文档分为章节、小节、段落和句子。然而,解析小节是一项非常困难的任务,因为现有资源中的小节标题往往已经无法正确解析。
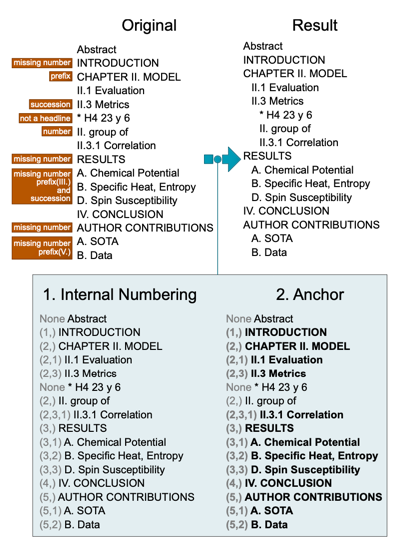
为了解析分节,我们使用标题中的编号。我们的方法适用于标题列表,其中一些可能是小节。它首先利用写作习惯和格式,猜测缺失编号的标题的章节编号,从而尝试创建内部编号。转换示例见图 2。然后找出连续编号的最长稀疏序列(我们称之为锚)。然后,将其余的标题行放入构建的层次结构中,如图 2 中的例子,非粗体标题被放在 II.3 指标部分。如果失败,算法会保留原始的浅层结构。如果层次结构中的元素少于三个,或者层级编号不匹配,算法就会保留原来的层次结构。例如,假设上一小节是 2.3.1,接下来是 3.5 节。它还考虑了数字格式;因此,例如,对于前面的 2.3.1 小节,后面的 2.3.B 小节就会被认为有问题。由于对转换的详尽描述超出了本文的范围,我们建议读者对我们的代码进行研究。
我们在 100 篇论文上手动分析了我们的分节解析器。由于我们只想评估分节解析器,因此我们只考虑了原始语料库中提供的标题,而没有考虑原始 PDF 中真正的分节标题。我们发现,有 20 篇论文的算法失败了,只保留了原始的浅层结构。在其余的 80 篇论文中,我们认为 89% 的论文解析正确。我们的分析还显示,这 80 篇论文中有 55% 没有使用小节。
为了进行句子分割,我们使用了 scispaCy 模型(Neumann 等人,2019 年)。该模型是针对生物医学领域的论文进行训练的,因此更适合我们的情况,因为标准(网络)模型在处理这类文档时通常会出现问题。标准模型的问题之一是引用跨度被错误地分类为句子边界。
2.1.3 Citation Spans
在我们的数据中,除了合并引文(如[3-6])外,我们保留了引文跨度的原始形式。我们决定将其扩展到每条引文,因为我们提供了字符偏移来识别引文跨度。否则,这将意味着两个引文跨度可能处于同一位置。
原始资料来源已经提供了经过解析的引文跨度。不过,我们决定也使用自己的哈佛式引文简单解析器。这是一个正则表达式搜索器,用于检查搜索跨度中的信息是否至少与一个书目条目相对应。匹配的条件是作者和年份。年份必须完全匹配,而作者的匹配方法与第 2.1.1 节所述的相同。这一步是在书目识别之后进行的。我们发现引文跨度增加了 1366 万,即增加了 1.8 %。
2.1.4 Document Content Cleaning
由于我们处理的文档可能存在严重的解析问题,因此我们决定在数据处理流程中添加一个清理步骤。我们删除:
- 标题为空的章节。
- 整个子层次中没有文本的章节。
- 标题中拉丁字符少于 30% 的章节。
2.2.Related Work Dataset
为了创建一个合适的数据集来生成相关工作部分,我们在语料库中搜索包含类似相关工作部分的文档。这意味着我们不仅要搜索标题为_“相关工作"的部分,还要搜索"背景”、"相关文献"和"文献综述"等部分。为避免混淆,“背景"只有在有另一个名为"引言”_的部分时才被视为有效。
通过这种方式,我们找到了 50 多万份具有相关工作类章节的文档。不过,我们决定进一步过滤这些文档,以提高最终文档集的质量。我们的管道会过滤掉每一个违反以下条件的相关作品:
- 至少包含三句话。
- 必须至少引用两篇文献。
- 相关工作部分的每个引文组必须至少有一个链接文件。
我们将引文组定义为后续引文跨度的序列。之所以使用组这一条件,是因为在开放存取的环境中,全面覆盖被引论文是不现实的。我们认为,每个组至少有一个代表是一个很好的近似值,因为一个组中的引文往往因为相似的原因而被引用。
我们还确保生成相关作品的每份目标文档和所有引用文档都有摘要。
通过这种方法,我们获得了 94 450 篇包含相关工作章节的论文,以及 5 824 689 篇在选定的相关工作章节中被唯一引用的论文。
在所有这些唯一被引用的论文中,82% 为纯摘要论文。由于我们希望提供一个适合评估全文模型的数据集,因此我们决定确保验证集和测试集中的每个相关工作部分都有全文引用文档。为此,我们找到了满足这一条件的所有文档,并将其中的 50%作为测试集,30% 作为验证集,其余的作为训练集。
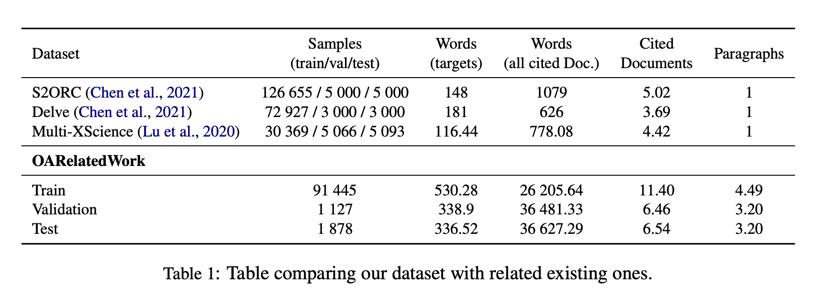
不过,从表 1 中可以看出,这种拆分方式会导致训练集包含较长的目标,因为较短的文本更有可能涵盖所有引文,因为较短的相关作品平均引文较少。不过,考虑到我们的任务定义(见第 3 节),这并不构成根本问题。
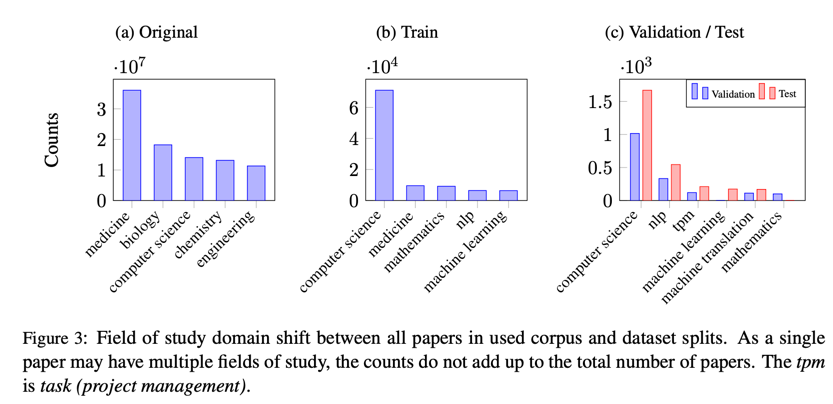
2.2.1 Domain Shift
在获取与相关工作类似部分的文档时,我们注意到整个语料库的原始分布发生了领域偏移。
图 3 显示了原始语料库和数据集拆分后的研究领域分布情况。尽管我们的数据集包含了指定研究领域的其他领域(如心理学、物理学或医学)的文档,但数据显示,这些文档主要转向计算机科学。
3.Tasks Definition
为了确定使用不同输入的贡献,我们制定了四个不同的任务。每个任务都要生成相关任务 Y = ( y 1 , y 2 , . . . , y L ) Y=(y_{1},y_{2},...,y_{L}) Y=(y1,y2,...,yL),其中 y i y_{i} yi 是相关任务部分的第 i 个标记,长度为 L L L。
系统会收到输入内容 X X X、目标长度 L L L,以及目标内容是否具有分节形式的信息。我们提供目标长度和分节信息是因为它们是作者的主观决定,而不是输入文本的特征。
我们对以下输入进行了区分:
- 引用论文的摘要和目标论文的摘要。
- 引用论文全文和目标论文全文(不含相关工作部分)。
- 引用论文全文。
- 目标论文全文(不含相关工作部分)。
4 Evaluation
我们使用多个指标来评估生成的文本。为了与之前的工作进行比较,我们使用了 ROUGE-1-F1、ROUGE-2-F1 和 ROUGE-L-F19 指标 [14]。
在应用评价指标10 之前,我们将所有引文和参考文献的跨度11 从其原始形式 ID TITLE FIRST_AUTHOR 归一化为 和 。 以及类似的参考文献。
4.1.BlockMatch
我们还决定采用基于嵌入的指标 BERTScore [23]。不过,由于我们处理的是长文本,而 BERT 输入长度有限,因此我们创建了一个元度量 BlockMatch ,用于处理较小的数据块。该元度量假定我们有一组参考块 R R R、一组预测块 P P P 和度量 m m m,提供一个相似性得分。在我们的实验中,区块是一个段落或标题文本。
它使用 m m m 计算每对区块的得分矩阵 S S S。然后,它采用_匈牙利算法_(Munkres,1957 年)来解决分配问题,以获得总分最高的参照区块和预测区块的组合 C C C:
t
=
s
u
m
(
r
,
p
)
∈
C
s
r
,
p
,
(2)
t=sum_{(r,p)\in C}s_{r,p}\,, \tag{2}
t=sum(r,p)∈Csr,p,(2)
其中,
s
r
,
p
s_{r,p}
sr,p 是矩阵
S
S
S 的元素,对应于参考值
r
r
r 和预测值
p
p
p 之间的得分。最后,它会计算
r
e
c
a
l
l
=
t
/
∣
R
∣
recall=t/|R|
recall=t/∣R∣、precision
=
t
/
∣
P
∣
=t/|P|
=t/∣P∣ 以及其中的
F
1
F_{1}
F1。我们在结果中报告了
F
1
F_{1}
F1。
4.1.1 Evaluation of BlockMatch Metric
为了展示所提出的指标与人类判断之间的相关性,我们使用了 Krishna 等人(2023 年)提供的数据和工具。这项工作测量了长篇摘要的自动度量与人工判断之间的相关性。在源文本的基础上,人类注释者被问及摘要的忠实度,分为粗略和精细两个级别。
由于我们需要将生成文本和参考文本分块,而原始数据并不像我们的数据那样提供段落,因此我们决定使用 _5 句分块来创建人工段落。
我们用_BlockMatch–ROGUE-2_、BERTScore_和_BARTScore_扩展了三个现有指标。最初的研究比较了_SQuALITY(Wang 等人,2022 年)和_PubMed_数据集的相关性。结果显示,不同领域的相关性不同,因此我们决定只使用 PubMed(Cohan 等人,2018 年),因为我们的目标是科学论文。
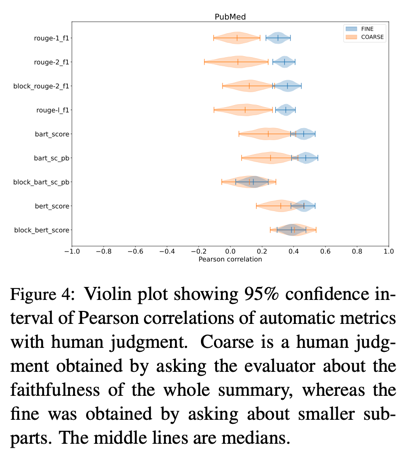
图 4 显示了 PubMed 数据集中扩展指标与人类判断的皮尔逊相关性。我们发现,就中值而言,BertScore 和 BartScore 的相关性优于 ROUGE 分数。然而,严格来说,只有 ROUGE-2 分数的分块变体更好。对于_BartScore_的分块版本,中值低于原始变体的中值。最后虽然_BertScore_的块版本的粗中值较高,细中值较低,但仍高于其他块变体的中值。因此,我们在实验中使用了_BertScore_的分块版本。
4.2.Citation Metric
由于引用是相关工作部分的重要组成部分,我们对其进行单独评估。形式上,对于参考文献中的一组引用文档 R c = { x ∣ x R_{c}=\{x|x Rc={x∣x_ 是参考文献中引用文档的标题或 ID} 和一组预测引用 P c = { x ∣ x P_{c}=\{x|x Pc={x∣x是生成文本中引用文档的标题或 ID},我们计算如下:
c r = ∣ R c ∩ P c ∣ ∣ R c ∣ (3) c_{r}=\frac{|R_{c}\cap P_{c}|}{|R_{c}|}\tag{3} cr=∣Rc∣∣Rc∩Pc∣(3)
c p = ∣ R c ∩ P c ∣ ∣ P c ∣ . (4) c_{p}=\frac{|R_{c}\cap P_{c}|}{|P_{c}|}\,.\tag{4} cp=∣Pc∣∣Rc∩Pc∣.(4)
然后,我们报告 c r c_{r} cr 和 c p c_{p} cp 的 F 1 F_{1} F1。
5 Related Work
5.1.Datasets
现有多个数据集,它们在输入类型、任务定义和样本数量上各不相同。
第一项工作(Hoang 和 Kan,2010 年)通过一个包含 20 篇论文的数据集介绍了相关作品生成任务。该数据集由相关工作摘要参考文献、引用文章全文和主题树组成。在这种情况下,任务是生成整个相关工作部分。
然而,对于抽象方法而言,生成长文本和处理长输入更为困难。这导致了一些数据集的产生,这些数据集只关注用于生成单段落摘要的纯抽象输入(Lu 等人,2020 年;Chen 等人,2021 年)。与我们数据的比较见表 1。
有些研究侧重于引文文本生成,即生成引用给定参考文献的句子(或多个句子)。目前正在使用各种输入,如引用论文的标题和摘要(AbuRa’ed 等人,2020 年)或引用句子和引用摘要的上下文(Xing 等人,2020 年)。最近,Funkquist 等人(2023 年)发布了_CiteBench_,以统一现有的引文文本数据集。
我们的工作与此不同,因为我们的数据集旨在提供所有可用资源,以生成整个相关工作部分。我们认为,出于这个原因,我们需要在可能的情况下超越摘要,同时提供目标论文的其余部分,以便我们生成相关工作部分的对比部分(像这样的段落)。
5.2.Evaluation
由于 "相关作品 "生成是一项 "摘要 "任务(Hoang 和 Kan,2010 年),因此它使用了该领域常用的指标。即使有人工评分,总结的评估也是一项艰巨的任务,因为注释者之间的一致性往往很小,尤其是在非专家参与的情况下(Fabbri 等人,2020 年;Gillick 和 Liu,2010 年)。
使用最广泛的指标是 ROUGE(Lin,2004 年),它有许多变体,如 ROUGE-N-F1 和 ROUGE-L。ROUGE-N 基于 n-grams 的词法重叠。ROUGE-L 则使用最长共同子序列的长度。还有许多其他基于词汇重叠度量的方法,例如 BLEU(Papineni 等人,2002 年)或 METEOR(Lavie 和 Agarwal,2007 年)。然而,所有这些指标都有一个明显的缺点,即无法从语义上匹配不同文本形式中的相同文本。这可以通过多个参考文献(可能很难获得)或考虑同义词(如 METEOR 的情况)来缓解。
另一种研究不基于词汇重叠,而是使用语言模型。BERTScore (Zhang 等人,2020 年)使用上下文 BERT(Devlin 等人,2019 年)嵌入来获得候选标记和参考标记之间的余弦相似度,然后将它们汇总到最终得分中。另一方面,BARTScore(Yuan 等人,2021 年)将评估表述为文本生成任务,得分是给定输入序列的目标序列的对数概率。根据目标序列和源序列的不同,可以得到忠实度、精确度、召回率或 F 1 F_{1} F1。这些指标的问题在于它们对输入长度有限制(BERT 为 512 个词组),这对我们的任务来说是个问题。因此,我们决定构建第 4.1 节所述的元度量,对较小的数据块进行操作并汇总结果。
6.Experiments
我们在数据集上研究了几种基本方法,并消除了不同类型的信息丰富输入的影响。这些基线包括天真和oracle方法、传统系统和基于transformer的模型。
6.1.Models
6.1.1 Lead
LEAD 从每篇文档中选取前 n n n 个句子,因此是从摘要中选取。在我们的实验中,我们只选择了每篇文档中的第一句话,同时还添加了引用跨度,引用跨度指的是提取该句子的文档。
这种基线有助于了解文档开头的显著性。预计在科学文献领域,开头的显著性较高,因为有摘要部分。
6.1.2 Greedy Oracle
Greedy Oracle(GO)是一种提取方法,它贪婪地选择句子,使给定的指标(在我们的例子中是 ROUGE-2-F1)最大化。它是对提取模型上限的估计。贪婪选择策略与 Nallapati 等人(2017)中所描述的相同。
在实验中,我们使用贪婪提取甲骨文作为独立的摘要器,并将其与其他模型结合使用。这样就可以在长输入类型上测试基于神经网络的模型,并分析附加内容的有用性。
将 Greedy Extractive Oracle 作为独立摘要器使用和将其与其他模型一起使用时会有细微差别。在前一种情况下,我们会根据所有给定文档中的所有句子创建一个摘要,而在后一种情况下,我们会为每个文档分别创建子摘要。
6.1.3 TextRank
TextRank Mihalcea 和 Tarau (2004) 是一种传统的基于提取图的摘要器。它建立了一个加权图,节点代表每个句子,边的权重代表两个句子之间的相似度。相似度基于长度归一化词性重叠。然后,它在构建的图上运行排序算法,选出排名靠前的句子作为摘要。
我们对每个输入文档分别使用 TextRank,并将每个子摘要的近似目标长度设定为基本真实摘要长度的合理部分。
对于每个子摘要,我们都会添加一个引用跨度,指向创建子摘要的文档。
6.1.4 Primera
PRIMERA Xiao 等人(2022 年)是基于 LED Beltagy 等人(2020 年)的多文档摘要预训练模型。它使用间隙句生成预训练目标和为多文档摘要设计的特殊实体金字塔屏蔽策略。
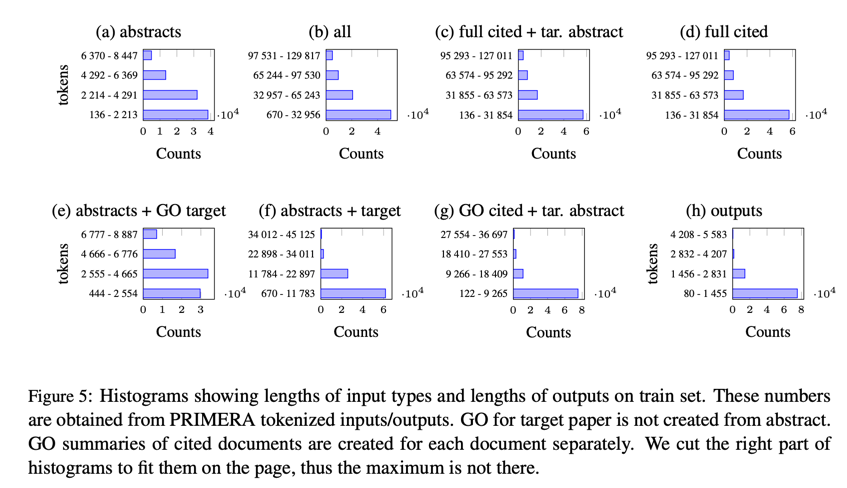
由于我们使用的是长输入(见图 5),而原始模型只支持最大长度为 4096 美元的输入词组和 1024 美元的输出词组,因此我们将编码器位置嵌入的数量增加到 8192 美元(GO 实验为 16384 美元),解码器为 2048 美元。与 Beltagy 等人(2020 年)的研究一样,我们通过复制已有的嵌入词来初始化这些额外的嵌入词。我们还在混合设置中使用了 PRIMERA(也是 MPT),由 Greedy Oracle 为每篇输入论文提供提取摘要。
为了进行微调,我们使用 Lion Chen 等人(2024 年)的优化器和线性调度器,预热步数为 4000 步,学习率为 1e-05,无权重衰减,批量大小为 16,并使用患者 3 提前停止。我们在训练过程中使用教师强迫,在推理过程中使用波束搜索,波束大小为 4。
图 6 显示了输入格式。可以看出,我们添加了一个新的全局标记 ,用于划分查询和引用文档的内容。文档内容(也是目标内容)使用类似 Markdown 的文本表示,并带有引文和参考文献的特殊格式(见第 4 节)。当内容不可用时,我们在输入中至少输入作者(最多两个)和标题。每个引文由 id 或未知符号、引用论文的标题和第一作者组成。这种格式允许模型从记忆中提取参考文献。
6.1.5 Mpt
为了建立大型语言模型系列的基线,我们对 7b 参数模型 MPT-7b 进行了微调(MosaicML NLP 团队,2023 年)。我们保持与 PRIMERA 案例相同的输入格式,在输入上添加前缀模型,并让它生成目标相关工作。我们使用 Lion Chen 等人(2024 年)的优化器对 MPT 进行微调,最大序列长度为 18200 个 token,共 3000 步,采用余弦学习率调度器,热身 50 步,学习率 5e-06,注意力和 mlp dropout 0.1,批量大小 64,无权重衰减。在推理过程中,使用核采样对目标进行采样,采样率为 p p p=0.85。
6.2.Results
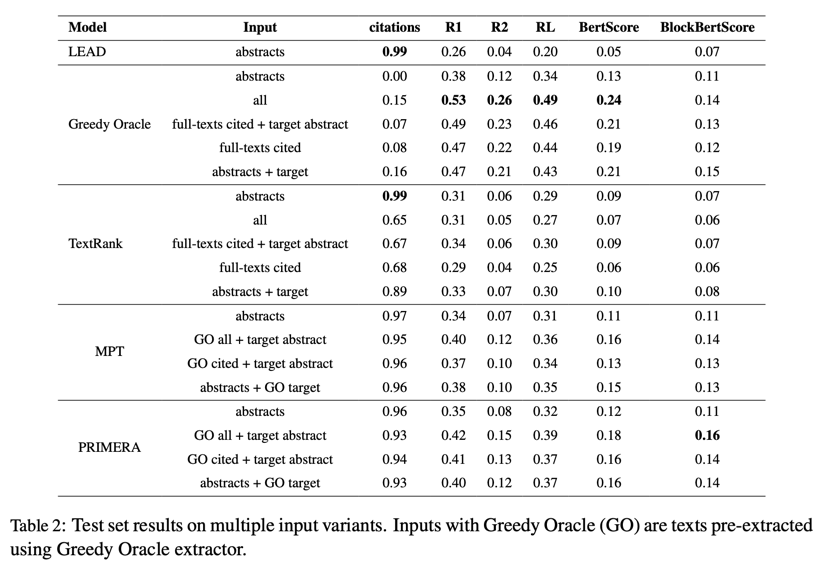
为了研究不同输入类型的优势,我们使用第 6.1 节中描述的模型进行了实验。评估结果见表 2。
LEAD 和 TextRank 的引用得分较高,这是因为我们在每个文档的提取句子中添加了引用后缀13。TextRank 非摘要输入得分较低的原因是精确度较低。另一方面,这些模型的引文指标并不完美(等于 1),因为存在已知文档之外的引文。
我们决定不将引文与 "贪婪甲骨文 "创建的摘要进行连接,以正确展示甲骨文句子是如何覆盖相关工作中的引用文档的。结果显示,当使用整个目标时,引用得分更高。这表明,论文的不同部分也会在类似的上下文中提到引用文件。这在意料之中,因为很多时候,例如引言可能会提到相同的论文。请参见表 2 中用 abstract + target 进行的 Greedy Oracle 实验。平均而言,有 16% 的引文在所选的突出句子中有所涉及。
神经基线的 Citations score 显示了良好的性能,表明模型能够关注多篇论文,而不是只选择一篇(或几篇)作为摘要。
Greedy Oracle 和神经基线结果对文本生成进行了评估,结果表明,与只使用摘要相比,使用全文是有益的。然而,传统的 TextRank 似乎无法从额外的上下文中获益。
就 ROUGE 分数而言,没有任何模型接近这一提取上限。而_(Block)Bertscore_的情况有所不同,但必须指出的是,该上限是通过优化 ROUGE-2-F1 估算得出的。
7 Conclusion and Future Work
这里提出的数据集是为了将相关工作的生成转移到更现实的场景中,因为我们将任务定义为生成整个章节,而不仅仅是一个段落。我们的工作超越了摘要的范围,显示了使用额外上下文的好处,同时也带来了处理超大输入和生成长摘要的挑战。
我们还排除了作者的一些主观因素,如相关作品的长度或将相关作品划分为若干小节。使用建议的设置、长度和结构信息作为输入来训练模型,也可能会开发出更方便用户设置这些属性的工具。
我们的工作还提出并评估了一种元度量_BlockMatch_,它与基于神经的度量相结合非常有用,因为神经度量无法将整个上下文与其输入相匹配。
在未来的工作中,该数据集还可用于训练检索增强模型,该模型将用于选择相关的工作论文。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









