









MySQL 基础 (一)- 查询语句
1. SQL是什么?MySQL是什么?
SQL(发音为字母 S-Q-L或 sequel)是 Structured Query Language(结构 化查询语言)的缩写。SQL是一种专门用来与数据库沟通的语言。与其他语言(如英语或 Java、C、PHP这样的编程语言)不一样,SQL 中只有很少的词,这是有意而为的。设计 SQL的目的是很好地完成一项 任务——提供一种从数据库中读写数据的简单有效的方法
MySQL是一个数据库管理系统,也是一个关系数据库。它是由Oracle支持的开源软件。
2. 导入示例数据库
- 在Navicat创建数据库,命令如下:
mysql> CREATE DATABASE IF NOT EXISTS yiibaidb DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
- 导入数据库
右击表 ->选择运行SQL命令
3. 查询语句
3.1. SELECT语句简介
使用SELECT语句从表或视图获取数据。表由行和列组成,如电子表格。 通常,我们只希望看到子集行,列的子集或两者的组合。SELECT语句的结果称为结果集,它是行列表,每行由相同数量的列组成。
3.2. SELECT语句的语法
SELECT
column_1, column_2, ...
FROM
table_1
[INNER | LEFT |RIGHT] JOIN table_2 ON conditions
WHERE
conditions
GROUP BY column_1
HAVING group_conditions
ORDER BY column_1
LIMIT offset, length;
- 语句解释
SELECT 语句由以下列表中所述的几个子句组成:SELECT之后是逗号分隔列或星号(*)的列表,表示要返回所有列。
FROM 指定要查询数据的表或视图。
JOIN 根据某些连接条件从其他表中获取数据。
WHERE 过滤结果集中的行。
GROUP BY 将一组行组合成小分组,并对每个小分组应用聚合函数。
HAVING 过滤器基于GROUP BY子句定义的小分组。ORDER BY 指定用于排序的列的列表。
LIMIT 限制返回行的数量。
语句中的SELECT和FROM语句是必须的,其他部分是可选的。
3.3. 实例
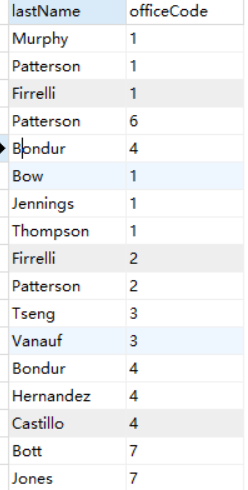
- 检索某几列
SELECT lastName,officeCode
FROM employees;
- 检索所有列
SELECT *
FROM employees;

- 去重(DISTINCT)
注意不能部分使用 DISTINCT
SELECT DISTINCT officeCode
FROM employees;

- 前N个语句筛选
SELECT *
FROM employees
LIMIT 5 OFFSET 2; --5表示返回多少行,2表示从那一行开始

- CASE…END 判断语句
CASE
WHEN 条件1 THEN 结果1
...
END
CASE
WHEN 条件1 THEN 结果1
...
ELSE 其他 END
4. 排序语句 ORDER BY
4.1 基本语法
SELECT
column_1, column_2, ...
FROM
table_1
ORDER BY column_1 -- 指定用于排序的列的列表
4.2 实例
- 正序排列
SELECT lastName,firstName,officeCode
FROM employees
ORDER BY officeCode; --默认正序排列

- 逆序排列
SELECT lastName,firstName,officeCode
FROM employees
ORDER BY officeCode DESC; --逆序排列,DESC作用于其前面的列名

5. 筛选语句 WHERE
5.1 语句解释
SELECT
column_1, column_2, ...
FROM
table_1
WHERE
conditions
在SELECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤。 WHERE子句在表名(FROM子句)之后给出。
5.2 运算符/通配符/操作符



5.3 实例
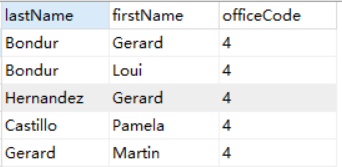
- 检索单个值
SELECT lastName,firstName,officeCode
FROM employees
WHERE officeCode = 4;
- 不匹配检查
SELECT lastName,firstName,officeCode
FROM employees
WHERE officeCode != 4;
- 范围值检查
SELECT lastName,firstName,officeCode
FROM employees
WHERE officeCode BETWEEN 5 AND 7;

5.4 WHERE组合检索实例
- AND/OR操作符
/* AND用法 */
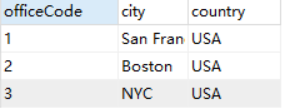
SELECT officeCode,city,country
FROM offices
WHERE country = 'USA' AND city = 'NYC';

/* OR用法 */
SELECT officeCode,city,country
FROM offices
WHERE country = 'USA' OR city = 'NYC';
- IN/NOT操作符
/*IN的格式用法*/
SELECT prod_name, prod_price
FROM Products
WHERE vend_id IN ( 'DLL01', 'BRS01' ) --与OR结果一样
ORDER BY prod_name;
/*NOT的格式用法*/
SELECT prod_name
FROM Products
WHERE NOT vend_id = 'DLL01' --与 != 效果一样
ORDER BY prod_name;
5.5 使用通配符进行过滤
- LIKE操作符
(1)百分号(%)通配符
%表示任何字符出现任意次数。
例1:WHERE prod_name LIKE ‘Fish%’;
表示找出所有以词Fish起头的产品
例2:WHERE prod_name LIKE ‘%bean bag%’;
表示匹配任何位置上包含文本bean bag的值,不论它之前或之后出现什么字符。
例3:WHERE prod_name LIKE ‘F%y’;
表示找出以F起头、以y结尾的所有产品
注意:%不能匹配NULL,即WHERE prod_name LIKE ‘%’
(2)下划线(_)通配符
下划线的用途与%一样,但它只匹配单个字符,而不是多个字符。
6. 函数
6.1 文本处理函数
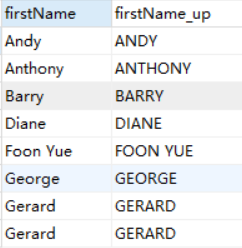
- 常用的文本处理函数

SELECT firstName,UPPER(firstName) As firstName_up
FROM employees
ORDER BY firstName;
6.2 时间处理函数
可参考菜鸟教程:时间处理函数
6.3 数值函数
- 常用数值函数

7. 分组语句 GROUP BY
7.1 聚集函数

- 实例
SELECT COUNT(*) AS num_items,
MAX(price) AS price_max,
MIN(price) AS price_min,
AVG(DISTINCT price) AS price_avg --DISTINCT表示去重
FROM price;

7.2 GROUP BY 函数
分组是使用SELECT语句的GROUPBY子句建立的,通过下面的示例来了解分组函数。
SELECT vend_id, COUNT(*) AS num_prods
FROM Products
GROUP BY vend_id;
结果:
vend_id num_prods
------- ---------
BRS01 3
DLL01 4
FNG01 2
SELECT语句指定了两个列:vend_id包含产品供应商的 ID, num_prods为计算字段(用 COUNT(*)函数建立)。GROUP BY子句指示 DBMS按vend_id排序并分组数据。这就会对每个vend_id而不是整个 表计算 num_prods一次。从输出中可以看到,供应商 BRS01有 3个产 品,供应商DLL01有4个产品,而供应商FNG01有2个产品。
7.3 HAVING子句
- 作用
WHERE 过滤行,而HAVING过滤分组。 - 示例
SELECT officeCode,COUNT(officeCode) AS code_num
FROM employees
GROUP BY officeCode
HAVING COUNT(*) >= 4;

8. SQL注释
/* 这是一条注释,允许跨行注释 */
SELECT officeCode,city,country --这是一条注释
FROM offices #这是一条注释
WHERE country = 'USA' AND city = 'NYC';
9. SQL代码规范
10. 实践项目
10.1 查找重复的电子邮箱
创建 email表,并插入如下三行数据
±—±--------+
| Id | Email |
±—±--------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
±—±--------+
编写一个 SQL 查询,查找 email 表中所有重复的电子邮箱。
根据以上输入,你的查询应返回以下结果:
±--------+
| Email |
±--------+
| a@b.com |
±--------+
说明:所有电子邮箱都是小写字母。
第一步:在navicat命令行界面创建Email表
mysql> use test01;
Database changed
mysql> -- 创建表
CREATE TABLE email (
ID INT NOT NULL PRIMARY KEY,
Email VARCHAR(255)
);
Query OK, 0 rows affected
mysql>
-- 插入数据
INSERT INTO email VALUES('1','a@b.com');
INSERT INTO email VALUES('2','c@d.com');
INSERT INTO email VALUES('3','a@b.com');
Query OK, 1 row affected
Query OK, 1 row affected
Query OK, 1 row affected
第二步:编写SQL查询
SELECT Email
FROM email
GROUP BY Email
HAVING COUNT(*) >= 2;
结果:

10.2 查找大国
第一步:在navicat命令行界面创建world表
mysql> use test01;
Database changed
mysql> -- 创建表
CREATE TABLE World (
name VARCHAR(50) NOT NULL,
continent VARCHAR(50) NOT NULL,
area INT NOT NULL,
population INT NOT NULL,
gdp INT NOT NULL
);
Query OK, 0 rows affected
mysql>
-- 插入数据
INSERT INTO World VALUES( 'Afghanistan', 'Asia',652230,25500100,20343000);
INSERT INTO World VALUES( 'Albania', 'Europe' ,28748,2831741,12960000);
INSERT INTO World VALUES( 'Algeria', 'Africa' ,2381741,37100000,188681000);
INSERT INTO World VALUES( 'Andorra' , 'Europe' ,468,78115,3712000);
INSERT INTO World VALUES( 'Angola' , 'Africa' ,1246700,20609294,100990000);
Query OK, 1 row affected
Query OK, 1 row affected
Query OK, 1 row affected
Query OK, 1 row affected
Query OK, 1 row affected
第二步:创建SQL查询
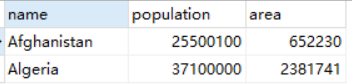
SELECT name,population,area
FROM world
WHERE area >= 3000000 OR
population >= 25000000 AND gdp >= 20000000;
结果:















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









