









package com.chen
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamWordCount {
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")
//2.初始化 SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建 DStream,读进来的数据为一行行
val lines = ssc.socketTextStream("192.168.56.100", 9999)
//将每一行数据做切分,形成一个个单词
val words = lines.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordToOne = words.map((_, 1))
//将相同的单词次数做统计
val wordToCount = wordToOne.reduceByKey(_ + _)
//打印
wordToCount.print()
//1、采集是长期执行的任务,所以不能直接关闭
//2、如果mian方法执行完毕,应用程序也会自动结束,所以不能让main执行完毕
//ssc.stop()
//启动采集器
ssc.start()
//等待采集器关闭
ssc.awaitTermination()
}
}
启动netcat,如下图

netcat安装教程
https://blog.csdn.net/weixin_44371237/article/details/126638496
执行StreamWordCount
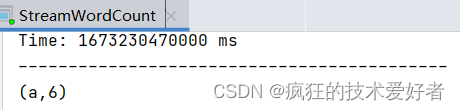
代码里面设置了3秒统计一次,所以输入7次,统计了6次,剩1次在下个3秒中统计















 1182
1182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









