






安装与使用
weka的相关资料可以在https://ml.cms.waikato.ac.nz/weka/获取
下载后的软件界面如图

进行实验

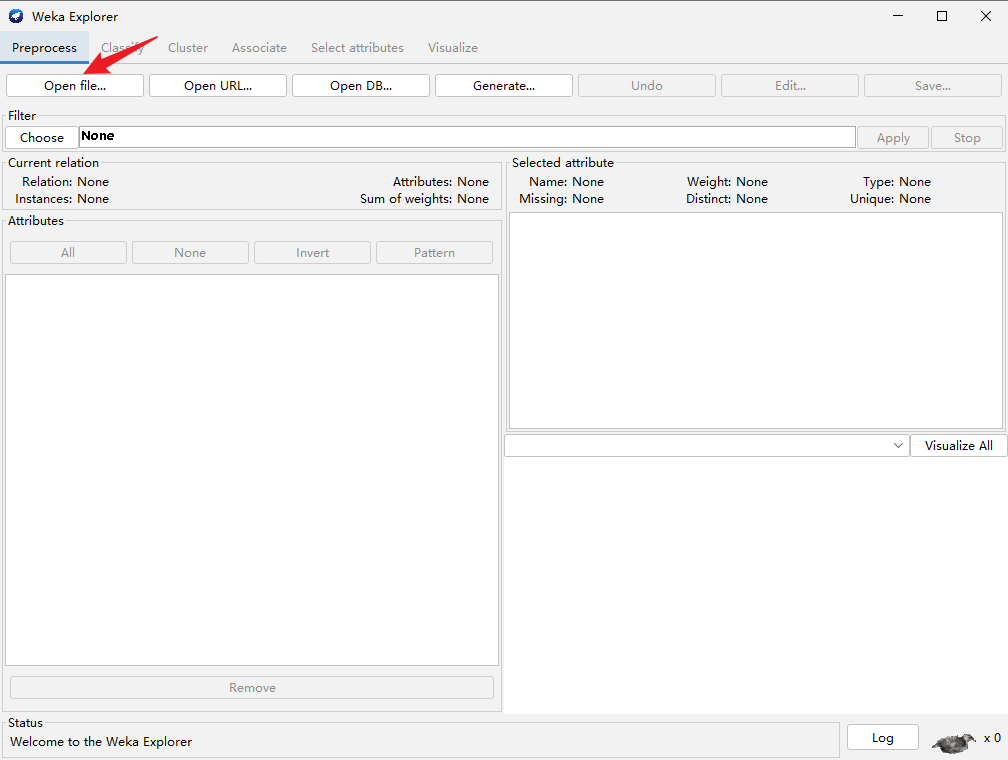
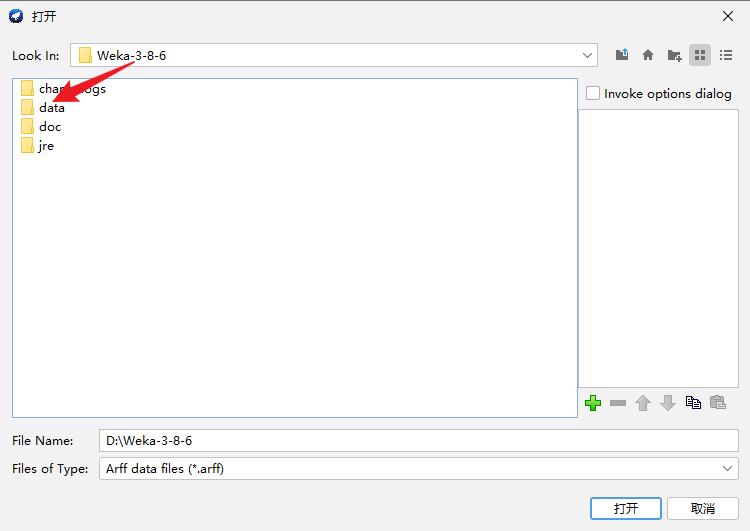
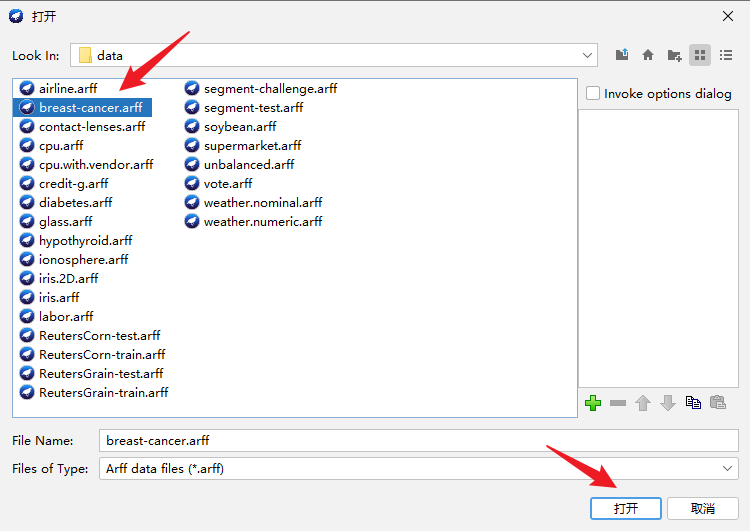
点击“Explorer”,进入如下界面,打开文件,随机选择weka平台官方提供的数据集
之后选择分类,进去如下界面
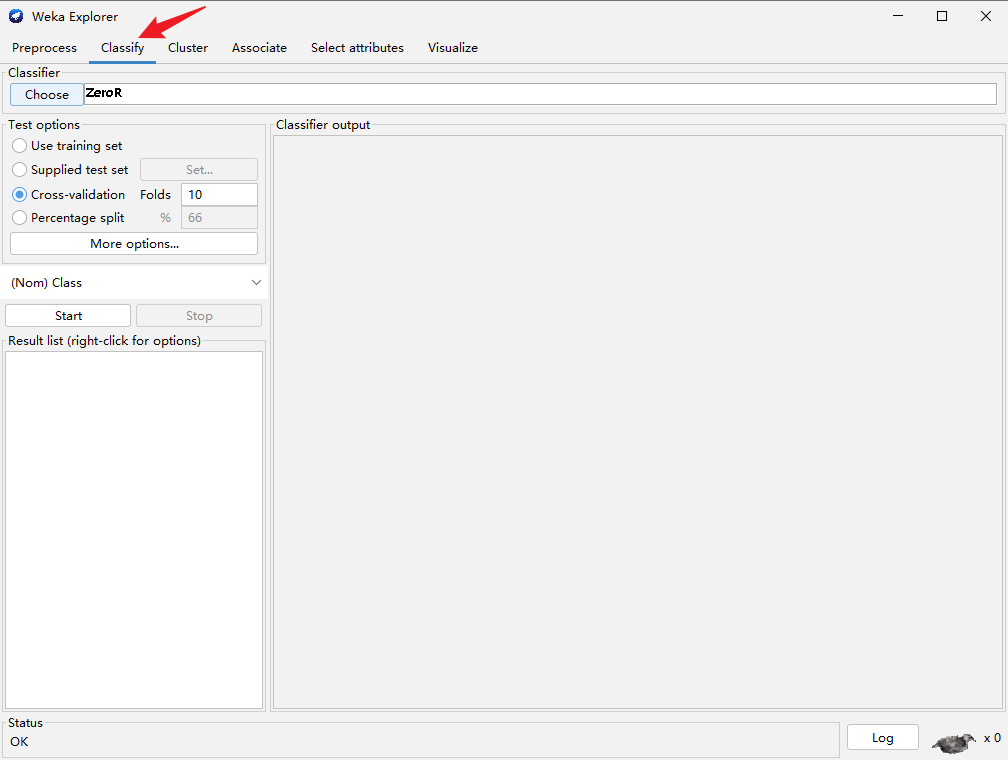
下图中选择数据处理方式,cross——validation的Folds一般选择5
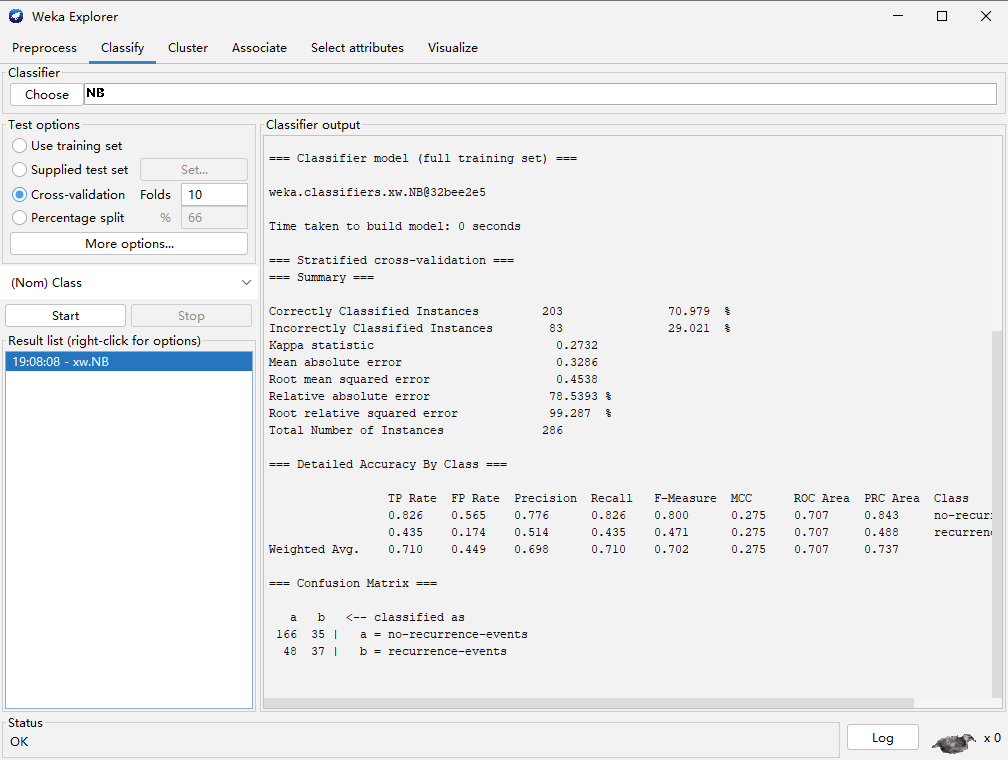
之后进行分类方法选择,例如贝叶斯分类
点击start可以得到分类结果
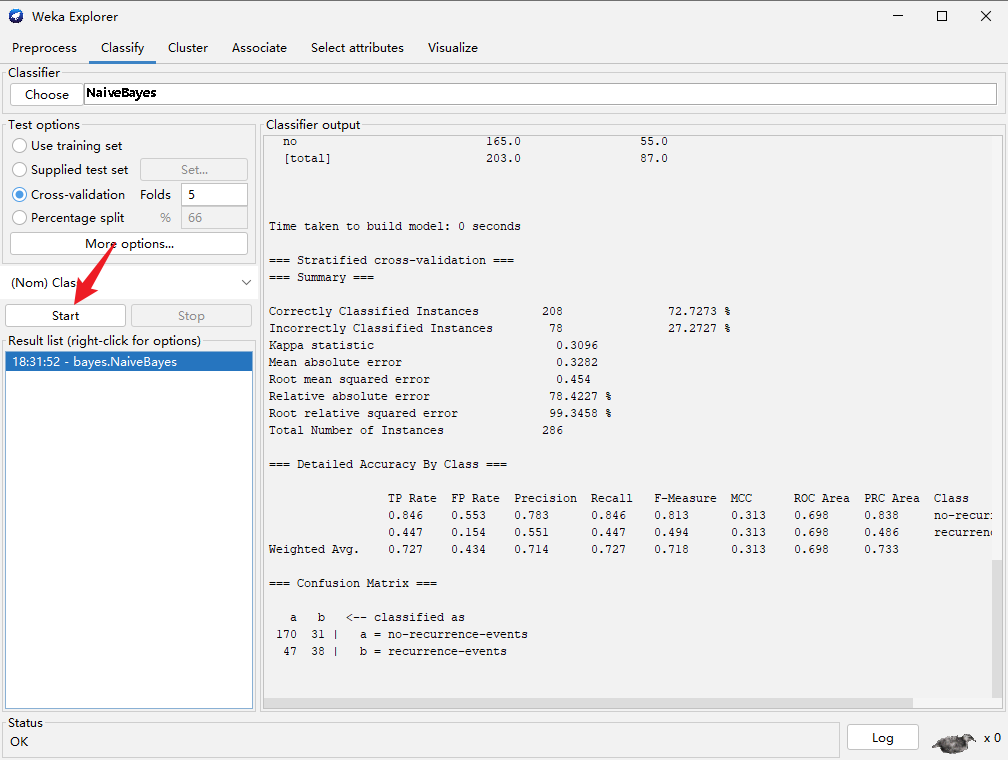
这里我们解释一下“Confusion Matrix”的含义。
=== Confusion Matrix ===
a b <-- classified as
170 31 | a = no-recurrence-events
47 38 | b = recurrence-events
这个矩阵是说,原本是“no-recurrence-events”的实例,有170个被正确的预测为“no-recurrence-events”,有64个错误的预测成了“recurrence-events”;原本是“recurrence”的实例,有47个被错误的预测为“no-recurrence-events”,有38个正确的预测成了“recurrence-events”。170+31+47+38= 286是实例总数,而(170+38)/286= 0.7272727正好是正确分类的实例所占比例。这个矩阵对角线上的数字越大,说明预测得越好。
多个实验结果比较

点击“Experimenter”,进入下图界面,之后点击“New”
之后点击“Browse”,选择文件保存的路径,
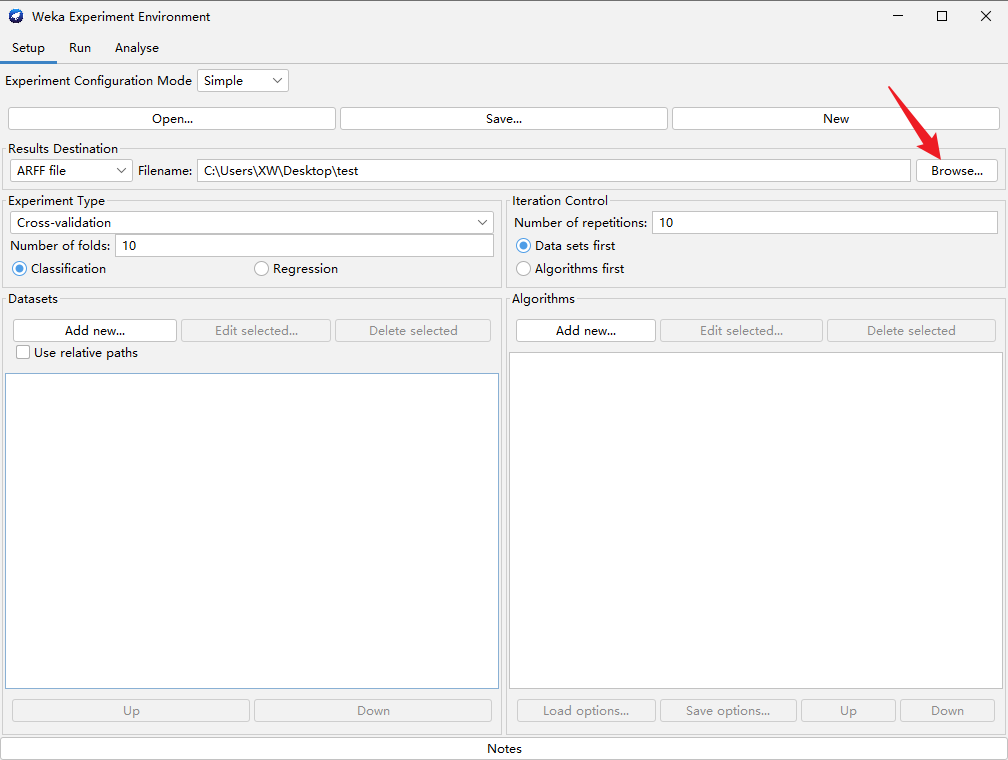
下面的红框中加入想要比较的数据集
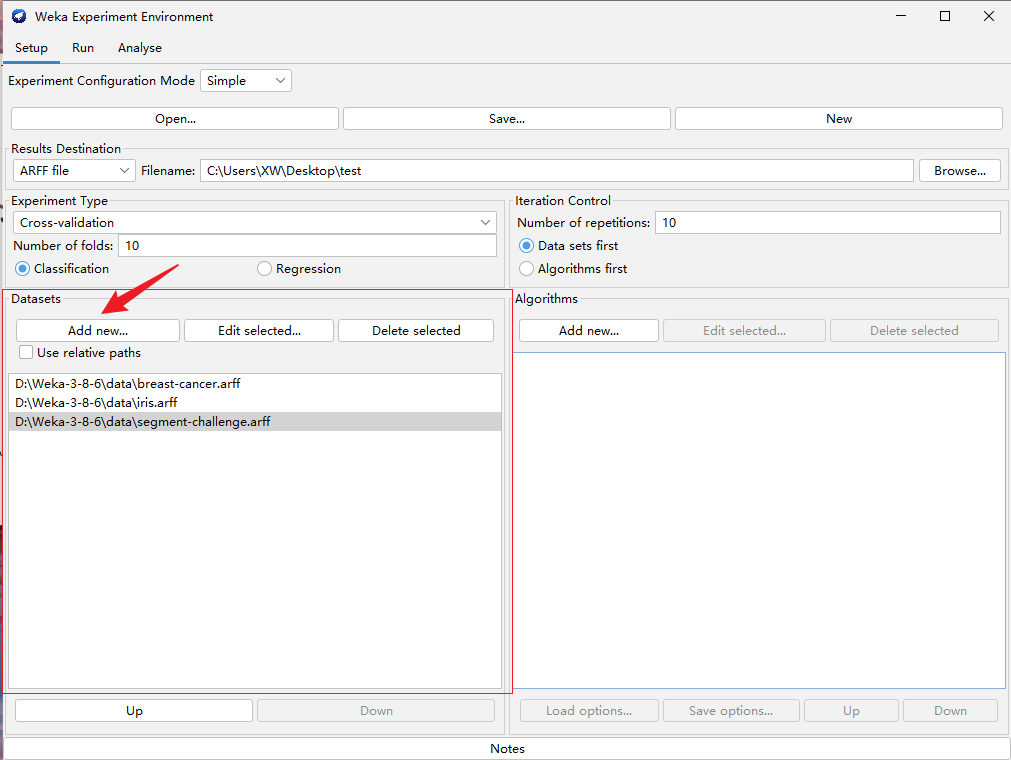
下面的红框中选择想要进行对比的方法
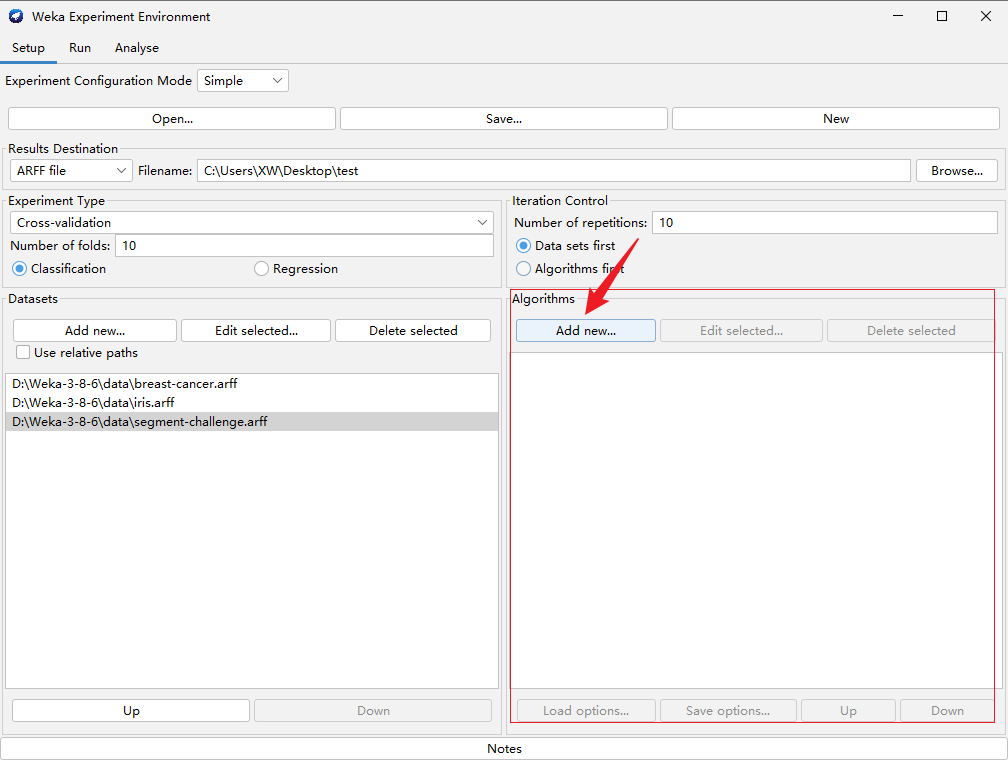
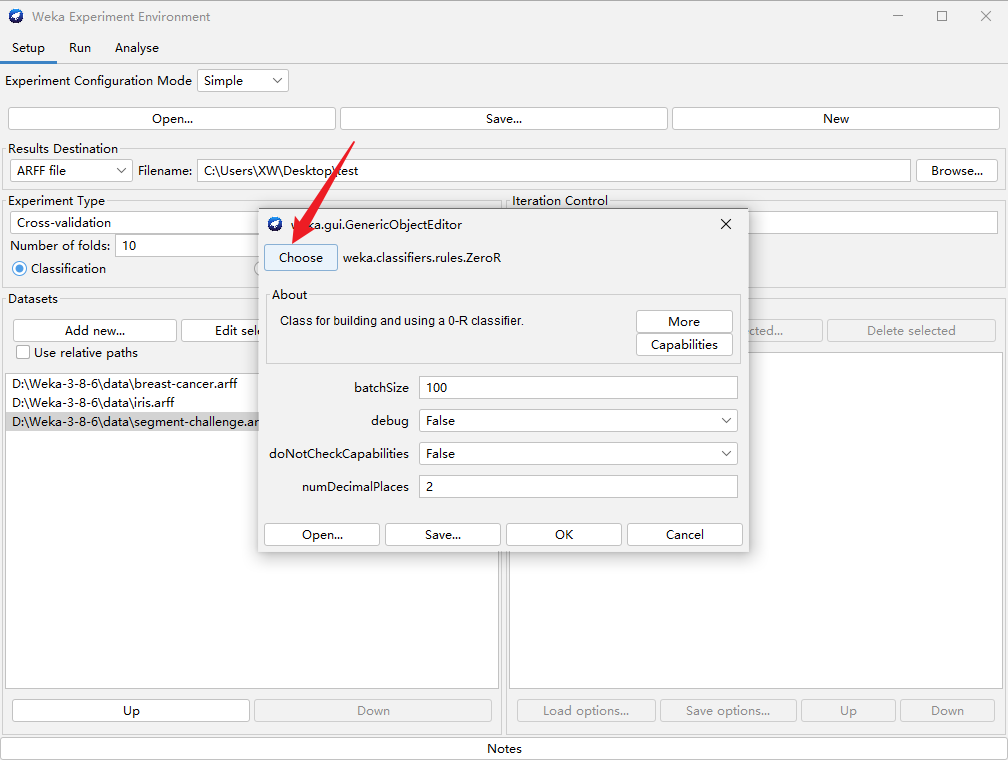
进入Run界面,点击“Start”
进入Analyse界面,点击“File”,选择你之前保存的文件,例如我之前保存在桌面的test文件
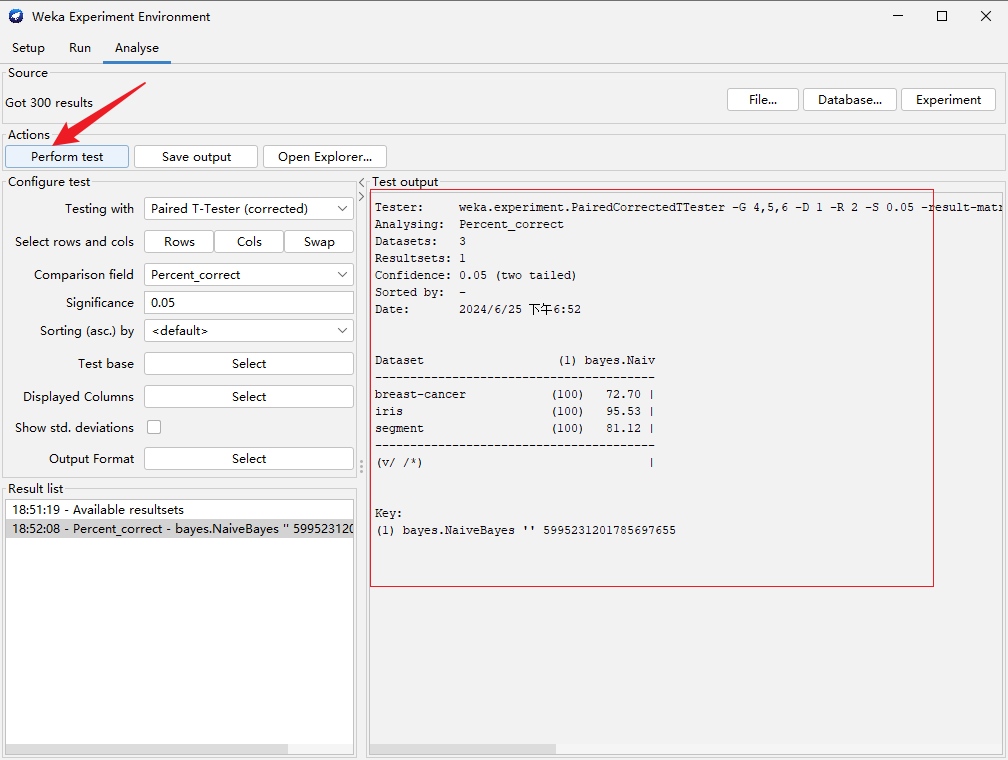
点击“Perform test”,右边出现对比结果表格
二次开发
步骤
打开Weka的安装路径,选择weka-src.jar文件,复杂到你想要实验的目录下,解压,基于此进行二次开发
用IntelliJ IDEA打开解压后的文件
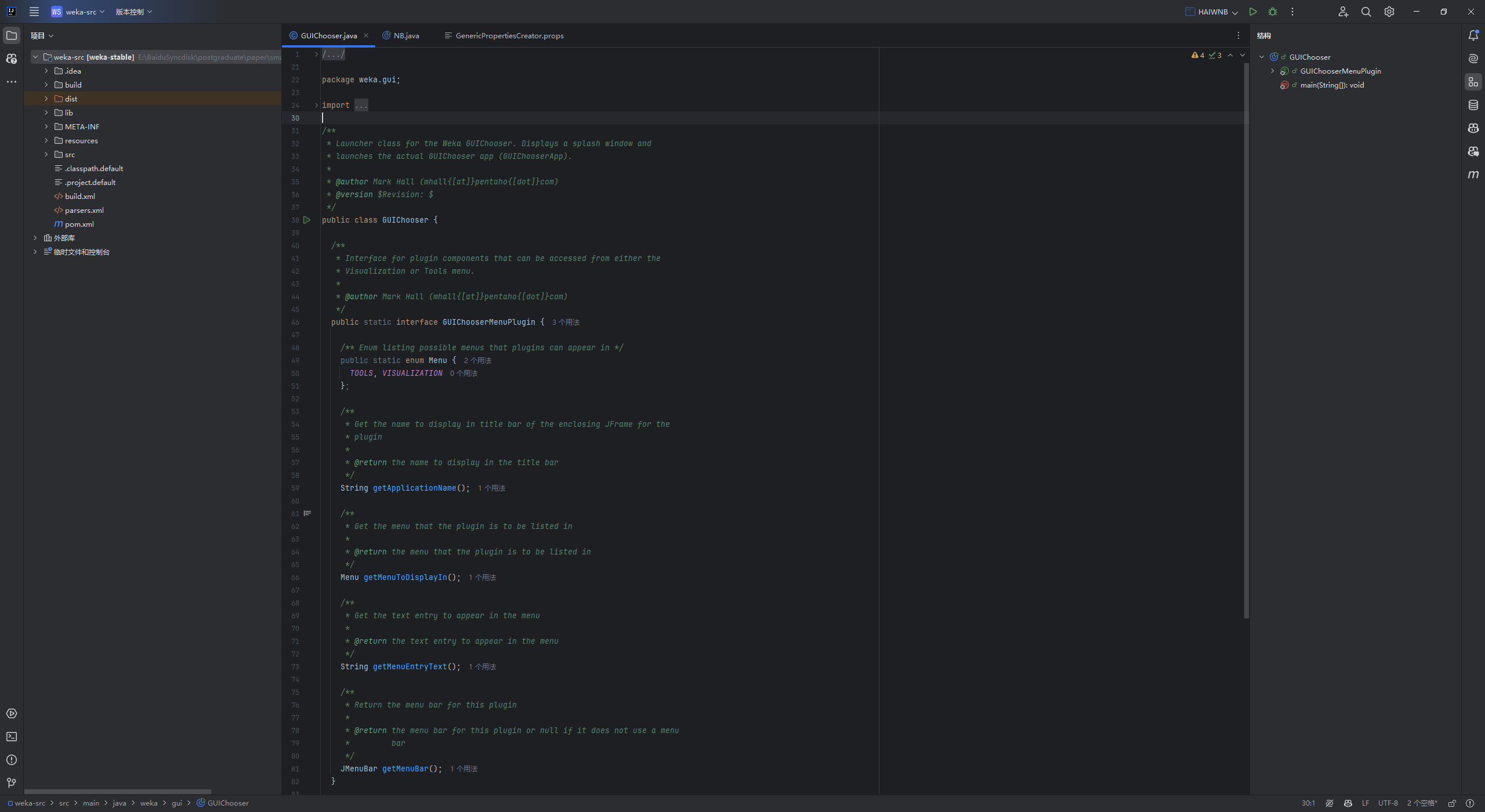
实现自己的分类器,先在weka-src/src/main/java/weka/classifiers下新建一个Package,然后新建一个java文件
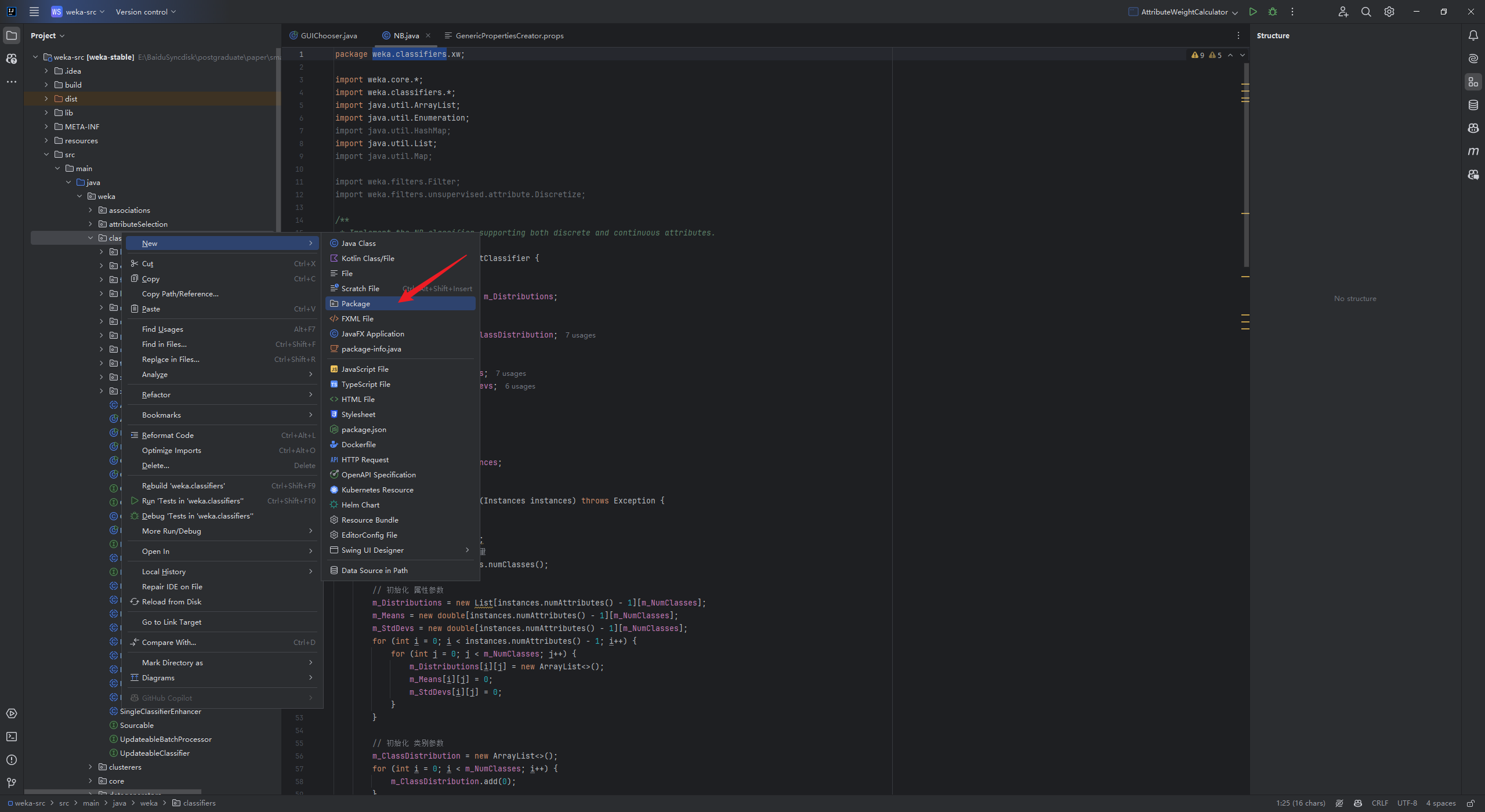
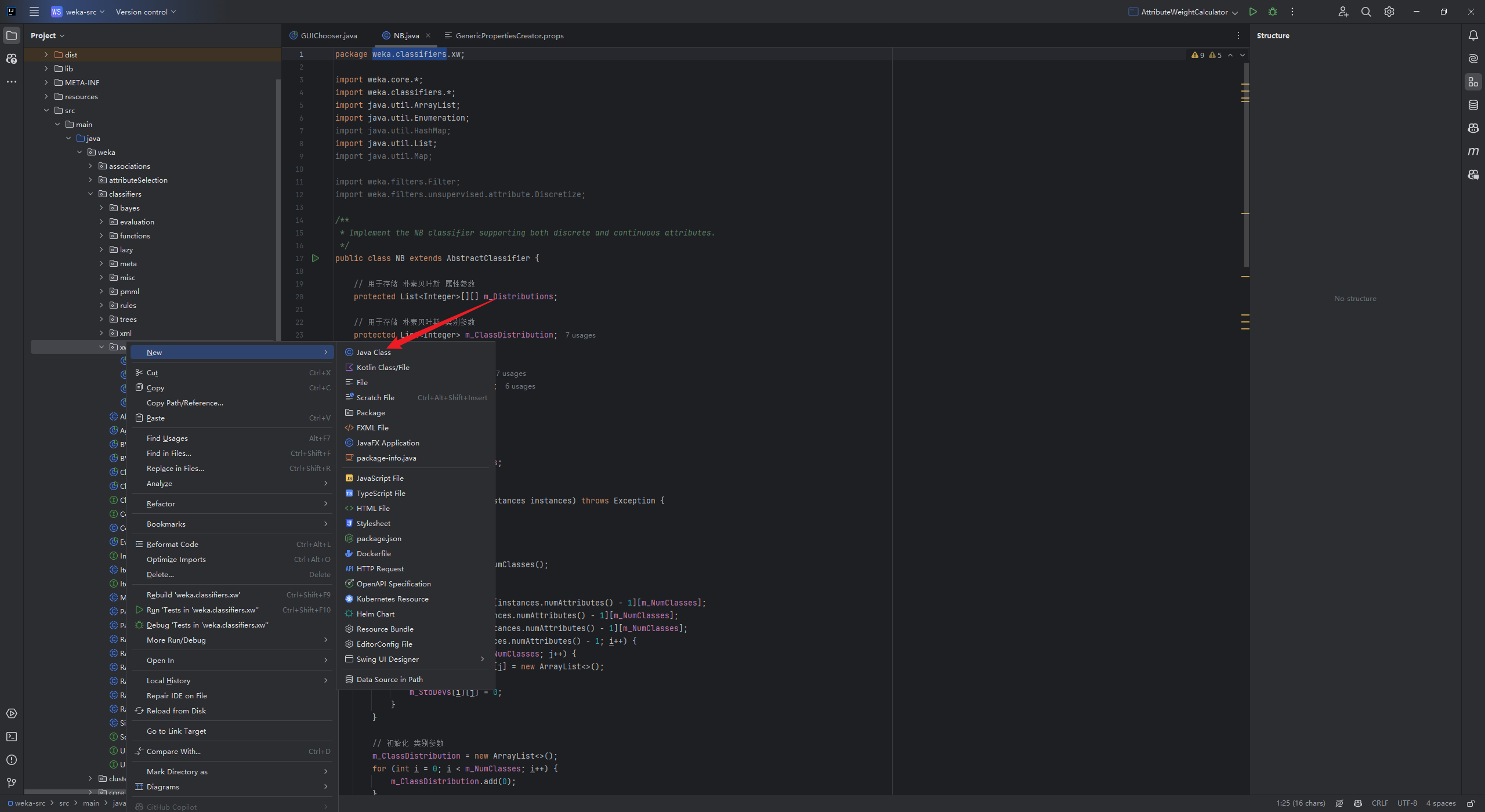
在gui包下面的GenericPropertiesCreator.props文件中增加你刚刚新建的包,例如我的包名称是xw
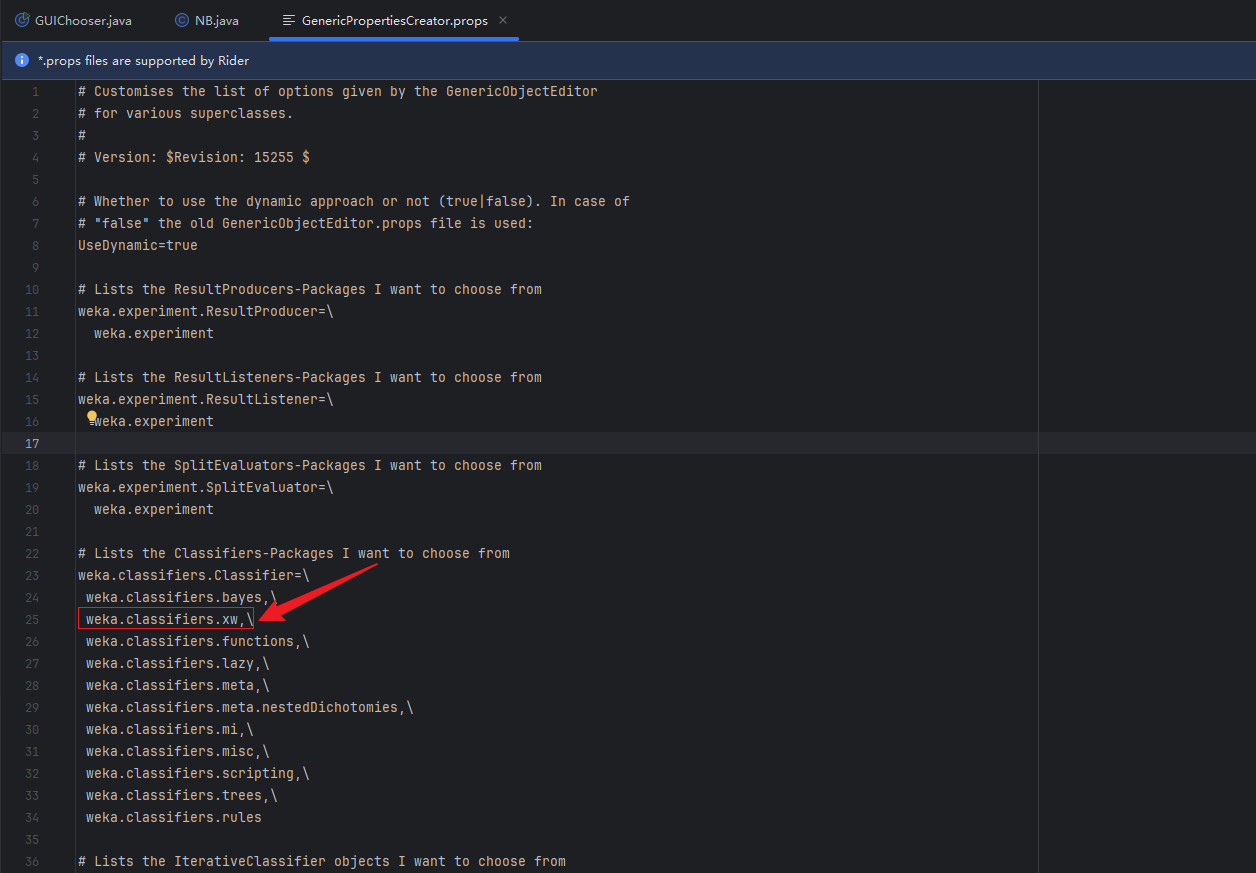 打开gui包下面的GUIChooser文件,运行,可以直接打开weka平台
打开gui包下面的GUIChooser文件,运行,可以直接打开weka平台
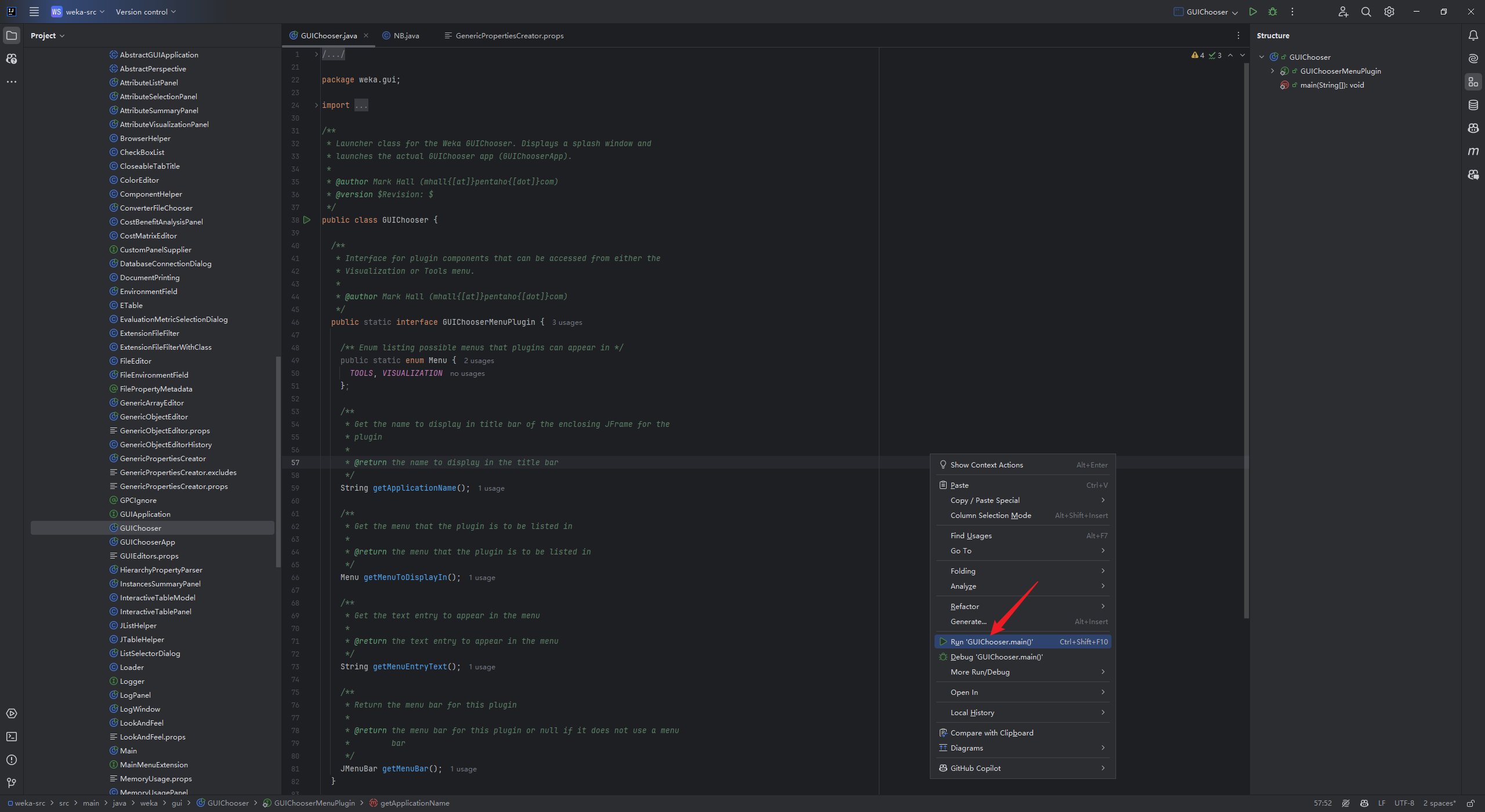

新建的java我命名为NB,打开weka平台,找到新建的NB方法,实现分类
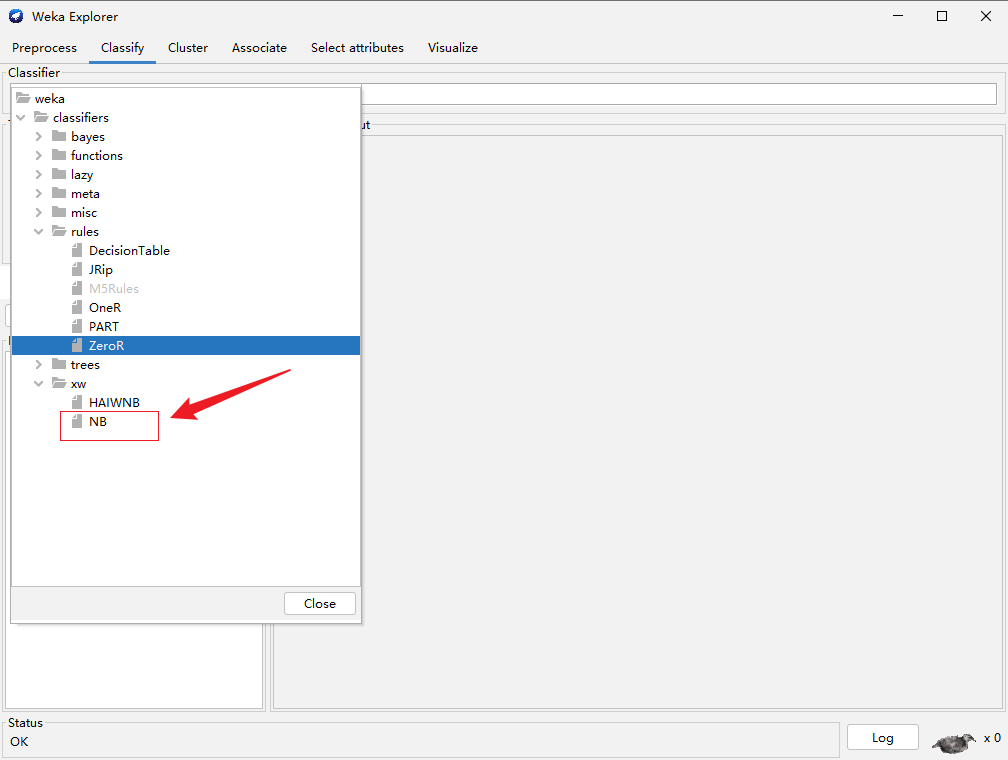
一般情况下分类器只需要重载下面两个函数
public void buildClassifier(Instances instances) throws Exception
public double [] distributionForInstance(Instance instance) throws Exception
朴素贝叶斯实现代码
package weka.classifiers.xw;
import weka.core.*;
import weka.classifiers.*;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import weka.filters.Filter;
import weka.filters.unsupervised.attribute.Discretize;
/**
* Implement the NB classifier supporting both discrete and continuous attributes.
*/
public class NB extends AbstractClassifier {
// 用于存储 朴素贝叶斯 属性参数
protected List<Integer>[][] m_Distributions;
// 用于存储 朴素贝叶斯 类别参数
protected List<Integer> m_ClassDistribution;
// 用于存储连续属性的均值和标准差
protected double[][] m_Means;
protected double[][] m_StdDevs;
// 类别参数 的 种类数量
protected int m_NumClasses;
// 存储训练数据
protected Instances m_Instances;
public void buildClassifier(Instances instances) throws Exception {
// 初始化训练数据
m_Instances = instances;
// 初始化类别参数 的 种类数量
m_NumClasses = instances.numClasses();
// 初始化 属性参数
m_Distributions = new List[instances.numAttributes() - 1][m_NumClasses];
m_Means = new double[instances.numAttributes() - 1][m_NumClasses];
m_StdDevs = new double[instances.numAttributes() - 1][m_NumClasses];
for (int i = 0; i < instances.numAttributes() - 1; i++) {
for (int j = 0; j < m_NumClasses; j++) {
m_Distributions[i][j] = new ArrayList<>();
m_Means[i][j] = 0;
m_StdDevs[i][j] = 0;
}
}
// 初始化 类别参数
m_ClassDistribution = new ArrayList<>();
for (int i = 0; i < m_NumClasses; i++) {
m_ClassDistribution.add(0);
}
// 获取属性参数的枚举类型
Enumeration attributeEnumeration = instances.enumerateAttributes();
// 遍历属性参数
while (attributeEnumeration.hasMoreElements()) {
// 获取属性参数
Attribute attribute = (Attribute) attributeEnumeration.nextElement();
// 获取属性参数的索引
int attributeIndex = attribute.index();
// 检查属性是否为离散型
if (attribute.isNominal()) {
// 获取属性参数的值的枚举类型
Enumeration attributeValueEnumeration = attribute.enumerateValues();
// 遍历属性参数的值
while (attributeValueEnumeration.hasMoreElements()) {
// 获取属性参数的值
String attributeValue = (String) attributeValueEnumeration.nextElement();
// 遍历类别参数
for (int classIndex = 0; classIndex < m_NumClasses; classIndex++) {
// 初始化属性参数的某个值的某个类别参数的计数
m_Distributions[attributeIndex][classIndex].add(0);
}
}
}
}
// 遍历训练数据
for (int instanceIndex = 0; instanceIndex < instances.numInstances(); instanceIndex++) {
// 获取训练数据的实例
Instance instance = instances.instance(instanceIndex);
// 获取训练数据的类别参数的值
int classValue = (int) instance.classValue();
// 计数
m_ClassDistribution.set(classValue, m_ClassDistribution.get(classValue) + 1);
// 遍历属性参数
for (int attributeIndex = 0; attributeIndex < instances.numAttributes() - 1; attributeIndex++) {
// 获取属性参数
Attribute attribute = instances.attribute(attributeIndex);
if (attribute.isNominal()) {
// 获取训练数据的属性参数的值
int attributeValue = (int) instance.value(attributeIndex);
// 确保 m_Distributions[attributeIndex][classValue] 有足够的空间
while (m_Distributions[attributeIndex][classValue].size() <= attributeValue) {
m_Distributions[attributeIndex][classValue].add(0);
}
// 计数
m_Distributions[attributeIndex][classValue].set(attributeValue,
m_Distributions[attributeIndex][classValue].get(attributeValue) + 1);
} else if (attribute.isNumeric()) {
// 更新均值和标准差
double value = instance.value(attributeIndex);
m_Means[attributeIndex][classValue] += value;
m_StdDevs[attributeIndex][classValue] += value * value;
}
}
}
// 计算连续属性的均值和标准差
for (int attributeIndex = 0; attributeIndex < instances.numAttributes() - 1; attributeIndex++) {
Attribute attribute = instances.attribute(attributeIndex);
if (attribute.isNumeric()) {
for (int classIndex = 0; classIndex < m_NumClasses; classIndex++) {
int count = m_ClassDistribution.get(classIndex);
if (count > 1) {
m_Means[attributeIndex][classIndex] /= count;
m_StdDevs[attributeIndex][classIndex] = Math.sqrt(
m_StdDevs[attributeIndex][classIndex] / count - m_Means[attributeIndex][classIndex] * m_Means[attributeIndex][classIndex]);
}
}
}
}
}
/**
* Calculates the class membership probabilities for the given test instance
*
* @param instance the instance to be classified
* @return predicted class probability distribution
* @exception Exception if there is a problem generating the prediction
*/
public double[] distributionForInstance(Instance instance) throws Exception {
// 初始化预测概率数组
double[] predictionProbability = new double[m_NumClasses];
// 遍历类别参数
for (int classIndex = 0; classIndex < m_NumClasses; classIndex++) {
// 初始化预测概率
double prediction = 1;
// 遍历属性参数
for (int attributeIndex = 0; attributeIndex < m_Instances.numAttributes() - 1; attributeIndex++) {
// 获取属性参数
Attribute attribute = m_Instances.attribute(attributeIndex);
if (attribute.isNominal()) {
// 获取属性参数的值
int attributeValue = (int) instance.value(attributeIndex);
// 获取当前属性可能的取值数
int attributeValueCount = m_Distributions[attributeIndex][classIndex].size();
// 检查索引是否有效
if (attributeValue >= attributeValueCount) {
throw new Exception("Attribute value index out of bounds: " + attributeValue);
}
// 计算条件概率P(x|c) (当前属性值在当前类别下占的比例) (拉普拉斯平滑)
double p_x_c = (double) (m_Distributions[attributeIndex][classIndex].get(attributeValue) + 1) /
(m_ClassDistribution.get(classIndex) + attributeValueCount);
// 计算预测概率
prediction *= p_x_c;
} else if (attribute.isNumeric()) {
// 计算连续属性的概率密度函数值
double mean = m_Means[attributeIndex][classIndex];
double stdDev = m_StdDevs[attributeIndex][classIndex];
double value = instance.value(attributeIndex);
double p_x_c = (1 / (Math.sqrt(2 * Math.PI) * stdDev)) *
Math.exp(-Math.pow(value - mean, 2) / (2 * Math.pow(stdDev, 2)));
prediction *= p_x_c;
}
}
// 计算先验概率P(c) (当前类别占总类别的比例) (拉普拉斯平滑)
double p_c = (double) (m_ClassDistribution.get(classIndex) + 1) /
(m_Instances.numInstances() + m_NumClasses);
// 计算预测概率
predictionProbability[classIndex] = prediction * p_c;
}
// 归一化
Utils.normalize(predictionProbability);
// 返回预测概率数组
return predictionProbability;
}
public static void main(String[] argv) {
runClassifier(new NB(), argv);
}
}
数据准备
WEKA必须从CSV文件的第一行读取属性名,否则就会把第一行的各属性值读成变量名。因此我们对于Matllab给出的CSV文件需要用UltraEdit打开,手工添加一行属性名。注意属性名的个数要跟数据属性的个数一致,仍用逗号隔开。
.csv -> .arff
将CSV转换为ARFF最迅捷的办法是使用WEKA所带的命令行工具。
运行WEKA的主程序,出现GUI后可以点击下方按钮进入相应的模块。我们点击进入“Simple CLI”模块提供的命令行功能。在新窗口的最下方(上方是不能写字的)输入框写上
java weka.core.converters.CSVLoader filename.csv > filename.arff
即可完成转换。
在WEKA 3.5中提供了一个“Arff Viewer”模块,我们可以用它打开一个CSV文件将进行浏览,然后另存为ARFF文件。
进入“Exploer”模块,从上方的按钮中打开CSV文件然后另存为ARFF文件亦可。















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









