






目录
1.概述
1.能检测弯曲的文本
2.能有效的分割距离较近的文本
2.核心思想
1.基于像素级别的分割,对任意形状的文本进行定位
2.使用渐进的尺度扩展算法,对相邻文本实例进行识别
3.网络结构
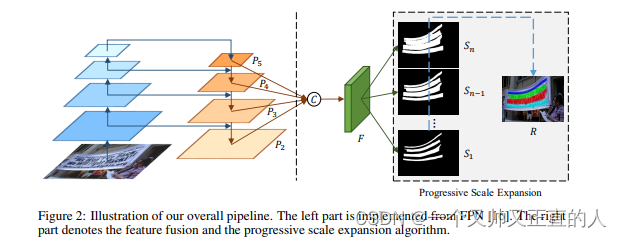
整个网络的结构大致如下:
1、首先是一个简单的ResNet的网络结构
2、其次是类似于FPN的操作方法,生成p2~p5的fpn特征图
3、随后的处理方法为:
(1) 将p3~p5的feature map都upsample到p2的尺度
(2) 不同尺度的feature map进行concat ( element-wise 相加),得到F
(3) 对进行3x3的卷积处理
(4)再进行1x1的上采样
(5)最后得到n个分割结果(S1,S2,...,Sn)
4.渐进的尺度扩展算法
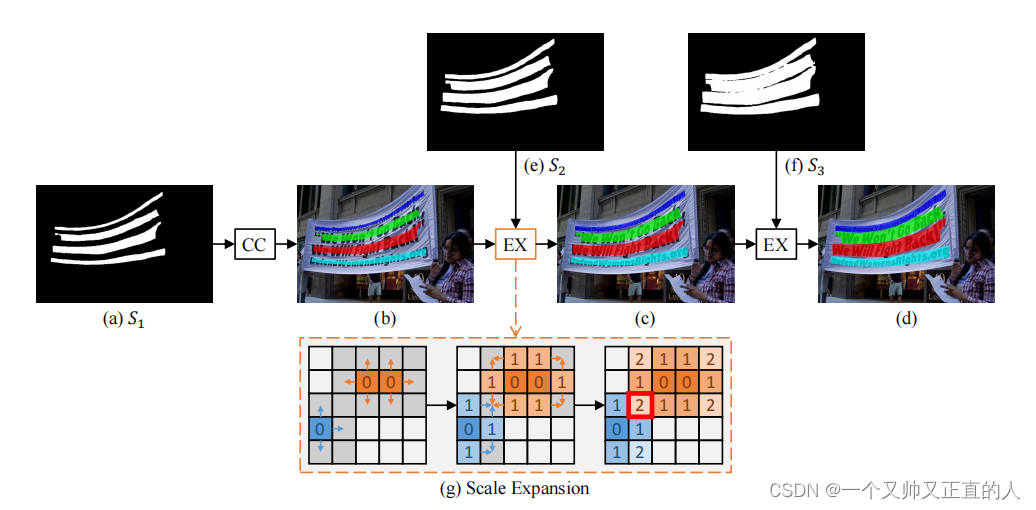
其中心思想来自于广度优先搜索(BFS)算法。具体步骤:
1)从具有最小尺度的kernel开始(在此步骤中可以区分实例),S1(上图a)代表最小kernel的分割结果,它内部有四个连通域C={c1,c2,c3,c4},通过查找连通域得到S1中的四个连通域,得图b(四个连通区域使用不同颜色标记,,小kernel,不同文本行之间的margin很大,很容易区分开)
2)将属于S2中的kernel的但不属于S1中的kernel的像素点(即图g左图中的灰色的部分)进行分配。在灰色区域(S2的kernel范围)内,将b图所找到的连通域的每个pixel以BFS的方式,逐个向上下左右扩展,即相当于把S1中预测的文本行的区域逐渐变宽(或者换种说法:对于S2中kernel的每个像素点,把它们都分别分配给S1中的某个连通域)
3)重复上述过程,完成直到发现最大的kernel做为预测结果
注:此处的kernel可以理解为文本区域
5.标签生成

不同尺度的真实标签,可以通过缩小原始文本区域的标签来得到。
利用Vatti clipping algorithm来得到不同尺度的标签,即录用将原始文本区域标签
缩放到小尺度的问区域
,得到的标签用
表示。
margin 可以通过以下公式得到:
Area()表示求面积,Perimeter()表示求周长。
m为最小缩放比例,n为缩放尺度的个数。
6.损失函数
损失函数分为两部分:
- Lc 代表整个文本实例(Sn)的损失
- Ls 代表缩放后文本实例(S1 -> Sn-1)的损失
其中λ用于平衡Lc和Ls,这里设置为0.7。
这里用dice coefficient损失函数:
和
分别代表
和
在(x,y)处的像素值。
因为图片中会有许多和文字笔画比较像的物体比如栅栏、格子图案等,因此对使用在线困难样本挖掘来更好的区分文本和这些相似的非文本。
专注于区分文本和非文本。
其中M代表OHEM(在线难例挖掘)的training mask。
缩放的文本实例的计算公式如下
,
Ls主要是shrink文本区域的损失,考虑到shrink后的文本区域被原始文本区域包围,因此作者忽略了分割结果Sn中非文本区域的像素从而避免像素冗余的情况。其中W代表Sn中文本区域的mask,Sn,x,y代表Sn中(x,y)的像素值。
7.其他一些说明
1.PSENet输入imgs是包含img、gt_text、training_mask和gt_kernels的列表。 其中img是原始图像,gt_text背景为0的文本区域的值是1。 training_mask是标签为“#”,即文本行区域为0,其余地方的值为1的二值图,gt_kernels共有6张图是与文本区域shrink的不同比例相对应的二值图,文本区域为1,其余区域为0。 psenet是基于实例分割的模型,标签与模型输入大小相同,因此对原图进行反转、旋转、裁剪等操作,对标签也进行同样的操作即可。
2.对于弯曲的文本,论文采用了道格拉斯-普克算法(the Ramer Douglas-Peucker algorithm)来生成任意形状的边界框。















 3054
3054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









