





1. 文本检测难点
文本内包含文本,艺术字体,任意方向 ,曲线文字 ,多语言,其他环境因素等是文本检测中的难点
2. 分割
问题1: 语义分割模型是对pixel进行分类,所以理论上讲,可以检测不规则的文本,但是其很难分离靠得近的文字块,难以区分到底是一个文本还是多个文本
3. PSENet
针对相邻文本的难区分性提出了PSE算法来解决这个问题
3.1 网络结构
如下图所示,网络结构类似于Fpn,在网络的末尾处选择四个feature map:分别为P2,P3,P4,P5,经上采用后进行concate操作得到F,再经过卷积后最终预测输出n个feature map:
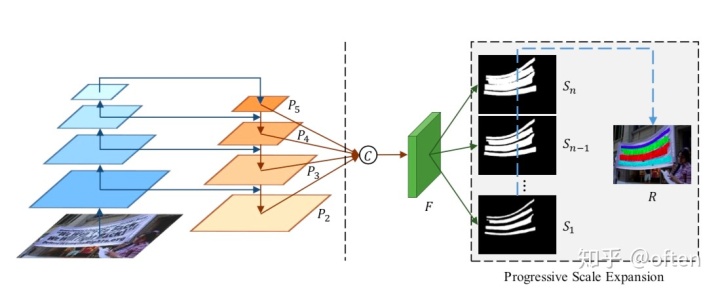
3.2 ground truth
从上面的网络结构图中,可以看到我们需要输出不同尺度范围的文本kernel,这些kernel形状一致,只是胖瘦不一,且尺度逐级递增。其中,
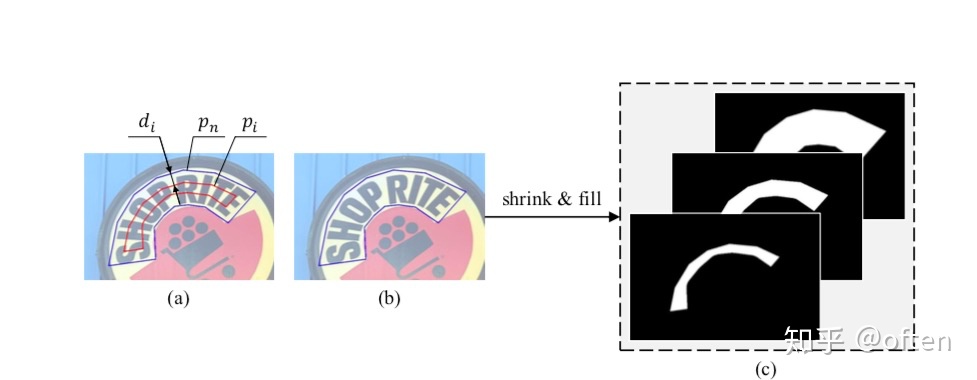
对于Pn和Pi之间的间距di定义为:
Area()代表多边形面积
Perimeter()代表多边形边长
其中n不是不同尺度kernel的个数,论文中取n=6,m代表最小缩放比例,范围(0,1),文章中m=0.5,即
3.3 渐进尺度扩张算法
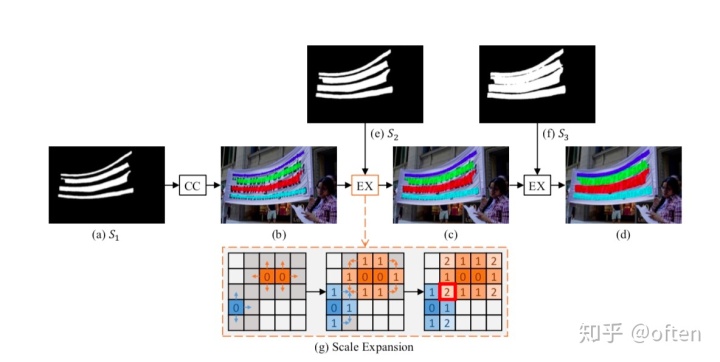
现在网络输出了
3.4 损失函数
定义:
通常文本实例占自然场景比例较小,采用二进制的交叉熵损失会遇到类别不平衡的问题,造成结果偏向非文本区域。本文采用dice coefficient损失函数:
其中:
文本区域和栅栏、栅格很相似,论文采用OHEM,使模型更好的区分文本和一些难例,正负样本比例为1:3.
具体
4. PSENet改进版:PAN-不降精度,极大加快速度
PSENet问题,速度较慢,后处理人工处理太多,效率低。PAN针对这两个问题,提出了低成本的分割模块和可学习的后处理办法。
4.1网络结构
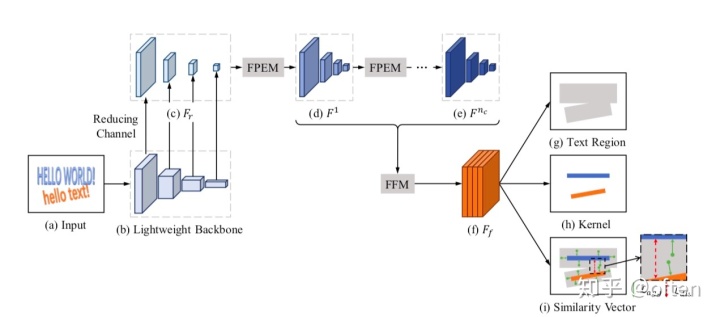
采用resnet18的轻量化网络作为backbone,该主干网络感受野较小,表达能力欠缺,所以提出了一个可高效修正的分割head.他有两个部分组成:特征金字塔增强模块(FPEM)和特征融合模块(FFM)。 如上图所示,FPEM可级联且被设计得计算量很小,连接在 backbone 后面让不同尺寸的特征有更深、更具表征能力。在 FPEM 模块后面,使用特征融合模块(FFM)来将不同层级的 FPEM 所产生的特征融合为最终用于分割任务的特征。
4.2 分割模块
4.2.1.PFEM模块

如上图,FPEM呈现U型状,由up-scale 增强、down-scale 增强两个阶段,up-scale输入是backbone输出的特征金字塔,步长分别 32,16,8,4 。 down-scale 阶段,输入的是由 up-scale 增强生成的特征金字塔,增强的步长从 4 到 32,同时,down-scale 增强输出的的特征金字塔就是FPEM 的输出。 和FPN结构类似,FPEM能够融合低级和高级信息来增强不同scale的特征,且设计成了一个可级联结构,使不同scale的特征能够更好的融合在一起,特征感受野也增大。同时,FPEM由可分离卷积构成,计算量为FPN1/5。
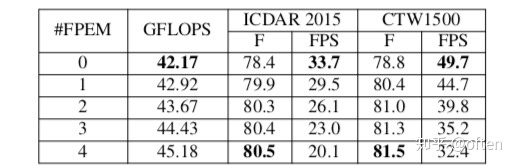
这个表格可以看出,FPEM模块数量从0到4,F(F-measure)提高了将近3个点。
4.2.2. FFM模块
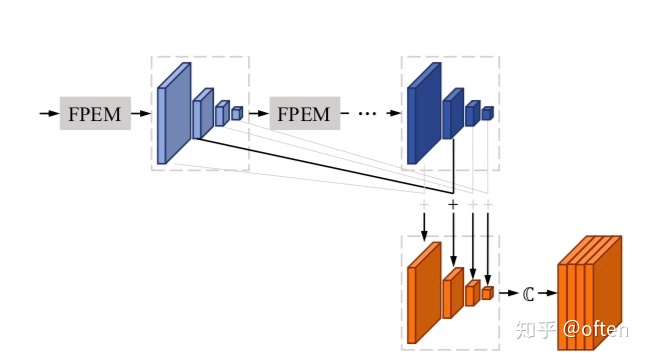
FFM模块用于融合FPEM的特征,因为FPEM是级联结构,输出的多个尺度的feature map。为了减少特征通道量,加快速度,论文并没有采用将不同sacle的特征图upsample后全部concate的思路,(因为这样会有scales_numstage_num128:每个scale的特征图被1*1卷积降维成128个channel的特征)。论文针对性的提出了如上图的融合方法,同一尺度的feature map通过逐元素相加,再对其进行upsample操作后使特征图具有相同的 size,最后concate起来,得到了模型的输出特征。
最后,使用1x1 conv得到6通道的输出。网络的输出包括: text region: 1个通道 kernel: 1个通道 similar vector: 4个通道(每个位置学习一个4维的特征向量,使用这个特征向量来聚类,这是一个无监督学习方法)
4.3 loss损失函数
4.3.1.定义:
其中:
对
4.3.2.
其中:
4.3.3.
N:文本实例数量 Ti表示第i个文本实例,
|Ti|表示第i个文本实例像素个数 Ki表示第i个文本实例kernel D定义了Ti内的像素p与Ki的距离,计算方式如下:
其中,
4.3.4.
其中:
4.4 后处理
原理就是利用学习到的similar vector 1. 通过连通阈获得初始的kernel(即文本实例的骨架)及其实例可能的像素 2. 对于Ki,按四个方向融合像素,判断依据为该像素p与Ki的similar vector之间的距离d = 6, 则认为该像素属于该类。 3. 重复2操作,直至Ki都融合到自己的像素。
4.5 疑问
- 为何测试阶段距离阈值d=6,比
=3还大,d>3在训练阶段是被认为属于不同实例??? 经与作者联系后确认为3.
5. DBNet
5.1 发现问题
在基于分割的文本检测网络中,最终的二值化map都是使用的固定阈值来获取,并且阈值不同对性能影响较大。 后处理的过程时间复杂度很高,很耗时。例如,pan,要先二值化,接下去还要进行聚类,不优雅。
5.2 DIfferentiable binarization及自适应阈值
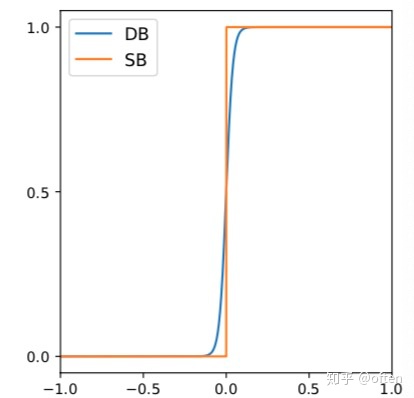
可导的二值化过程,通过网络自适应得到像素的阈值。同时将阈值设计为为可导结构,使其也可以监督网络学习,让得到的阈值非常的具有鲁棒性。 传统的固定阈值二值化:
DB近似二值化:
5.3 网络结构图
如下图,图中“1/2”, “1/4”, ... and “1/32” 表示feature和输入图像的缩放比
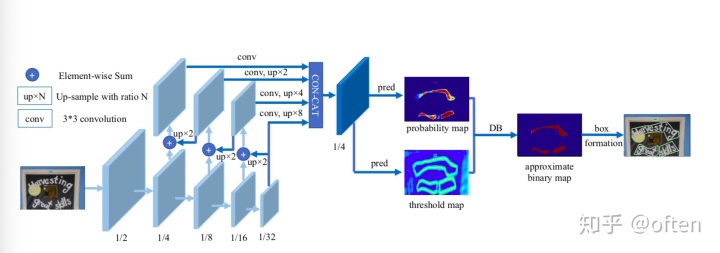
模型经过FPN层后,得到 probability map: 像素点为文本的概率 threshold map:像素点的自适应阈值 binary map: 近似的二值图
5.4 label生成
- probability map的制作方式和psenet等是一致的,利用pse算法制作即可
- threshold map: 将文本框分别向内和向外扩张d(上述pse算法中的d)个像素,然后计算收缩框和扩张框这个区域
内像素点距离其最近文本框边界的归一化距离D,1-D即得到threshold map在该点的值。对于处于两个文本框
的区域的像素点,其threshold map的值选择离它距离最近文本框的归一化距离。 同时设置threshold map值的上下限,最小值为0.3。对于非文本区域probability很容易学习,其概率值一般接近于0,同理,文本区域的骨架也是如此,其概率一般都很高。最难的就是边界的学习了,所以对threshold map着重于边界处阈值的学习。可以看到,在
区域内,离文本框越远,则意味着其阈值越高,要想被预测为文本区域,则其probability map对应位置的score得非常高。而probability map对应区域的位置label 为0。我们就可以看的很清楚了,在学习过程中,文本框骨架的边界外沿的这部分像素,网络在拼命拉低probability map的预测值,threshold map在拼命拉高其阈值,两者相互写协作,使DBNet的边界学习的非常好。
5.5 loss函数
本文的loss函数主要有三个部分:
5.6 预测
因为threshold map分支的监督作用,probability map的边界会学习的很好。因此,可以直接按照收缩的方法将预测得到的文本骨架框扩张回去(Vatti cliipping algorithm)扩张回去。大大简化了后处理的步骤。
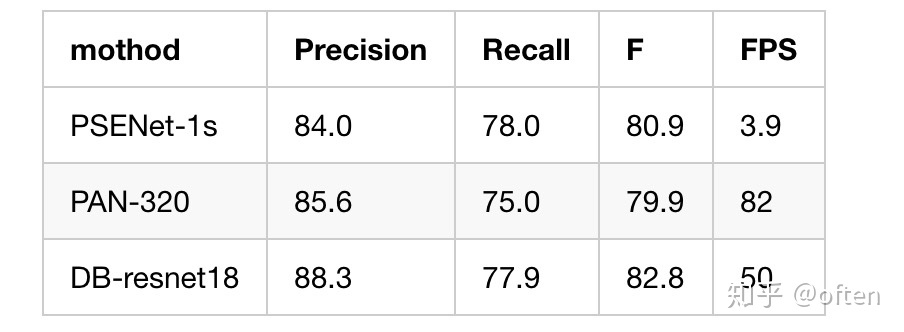
6. 比较(Total-text)
7. 资料
DB
https://arxiv.org/pdf/1911.08947.pdfarxiv.org https://github.com/MhLiao/DBgithub.com https://github.com/WenmuZhou/DBNet.pytorchgithub.comPSENet
狼牙:论文分享——PSENETzhuanlan.zhihu.com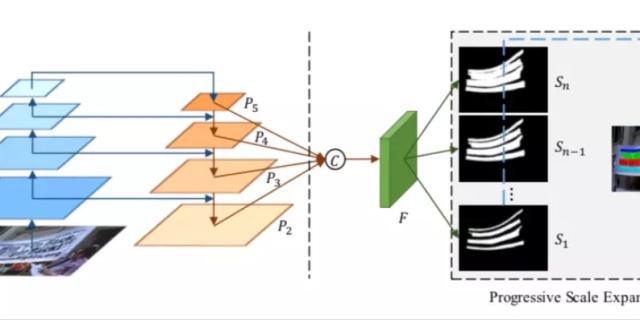
PAN















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









